此代码已经继续加入单步预测(单变量、多特征变量、风速、电力负荷预测)全家桶:单步预测全家桶(单变量、多特征变量、风速、电力负荷预测) (mbd.pub)
多特征变量包括以下内容:
2.多特征变量序列预测(七) CEEMDAN+Transformer-BiLSTM预测模型 (mbd.pub)
3.多特征变量序列预测(六) CEEMDAN+CNN-Transformer风速预测模型 (mbd.pub)
4.多特征变量序列预测(三)CNN-Transformer风速预测模型 (mbd.pub)
5.多特征变量序列预测(二)CNN-LSTM-Attention风速预测模型 (mbd.pub)
6.多特征变量序列预测(一)CNN-LSTM风速预测模型 (mbd.pub)
7.多特征变量序列预测(四)Transformer-BiLSTM风速预测模型 (mbd.pub)
8.多特征变量序列预测-Transformer预测模型 (mbd.pub)
9.多特征变量序列预测-LSTM预测模型 (mbd.pub)
10.多特征变量序列预测(五)CEEMDAN+CNN-LSTM风速预测模型 (mbd.pub)
11.多特征变量序列预测(11) 基于Pytorch的TCN-GRU预测模型 (mbd.pub)
单变量包括以下内容:
1.VMD-CNN-Transformer预测模型 (mbd.pub)
2.VMD-CNN-BiLSTM预测模型 (mbd.pub)
3.基于Python时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较 (mbd.pub)
4.风速预测:基于EMD-LSTM的预测模型 (mbd.pub)
5.单步预测模型(三)CNN-GRU并行模型 (mbd.pub)
6.风速预测:EMD-Transformer模型 (mbd.pub)
8.风速预测:EMD-CNN-LSTM模型 (mbd.pub)
9.单步预测模型(二)CNN-LSTM模型 (mbd.pub)
10.风速预测:EMD-LSTM-Attention(基于Pytorch实现) (mbd.pub)
11.风速预测:EMD-CNN-GRU并行模型 (mbd.pub)
12.单步预测(八)CEEMDAN-TCN-Attention预测模型 (mbd.pub)
包括 风速数据, 以及已经生成制作好的风速数据集、标签集,对应代码均可以运行
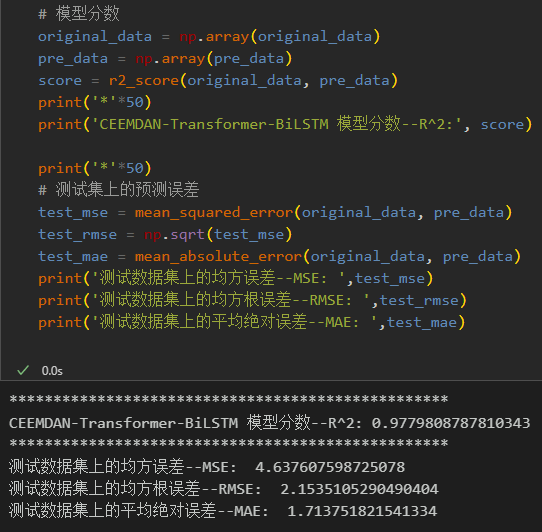
CEEMDAN+Transfromer-BiLSTM模型, 有着更小的MSE, MAE,效果特别明显,提升显著!!
包括数据预处理的和CEEMDAN分解代码,和完整CEEMDAN+Transformer-BiLSTM模型预测代码、可视化代码
环境:python 3.9 Pytorch 1.8 以上
任何环境安装或者代码问题,请联系作者沟通交流,对于购买者,作者免费解决调试问题,关注微信公众号[建模先锋],联系作者;

注意:本模型继续加入多特征变量序列预测全家桶中,之前购买的同学请及时更新下载,
全网最低价,入门多特征变量序列预测最佳教程,模型创新度高,大家可以了解一下:
https://mbd.pub/o/bread/mbd-ZZmbmZZp
前言
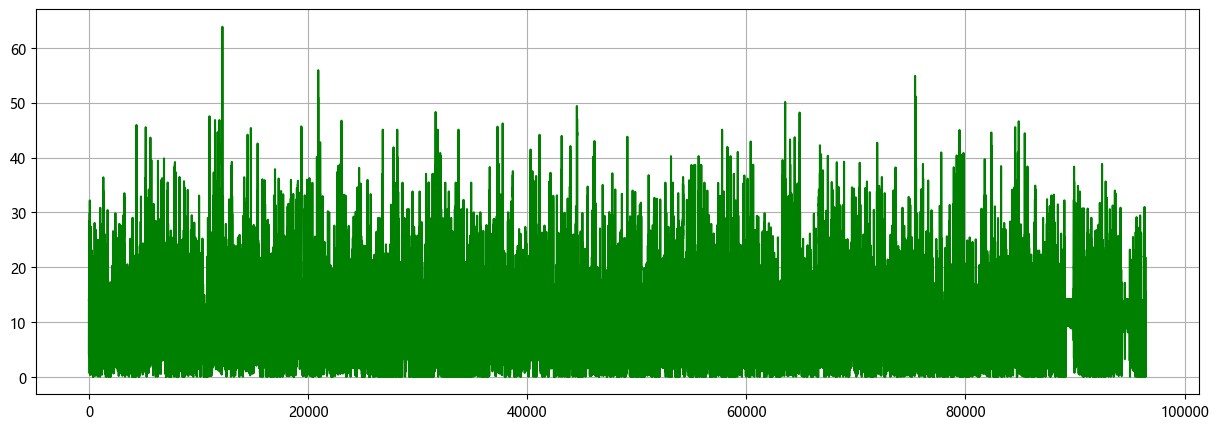
本文基于前期介绍的风速数据( 文末附数据集 ),介绍一种多特征变量序列预测模型CEEMDAN + Transformer-BiLSTM,以提高时间序列数据的预测性能。
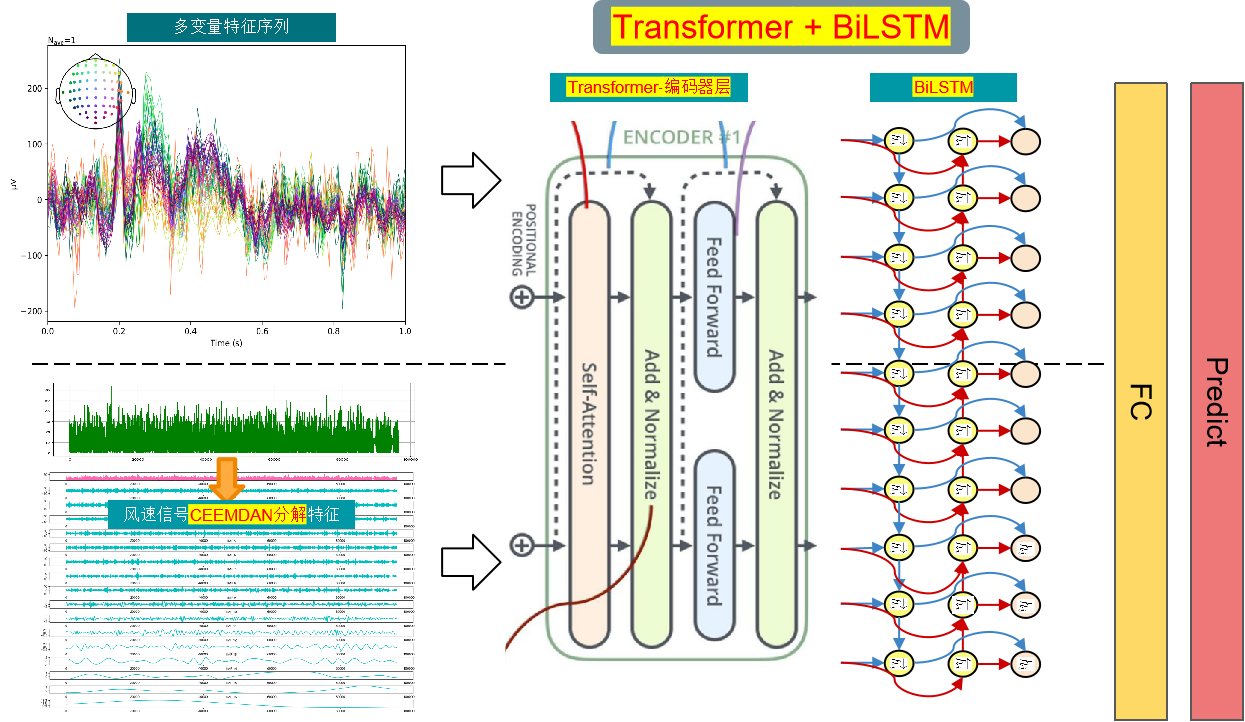
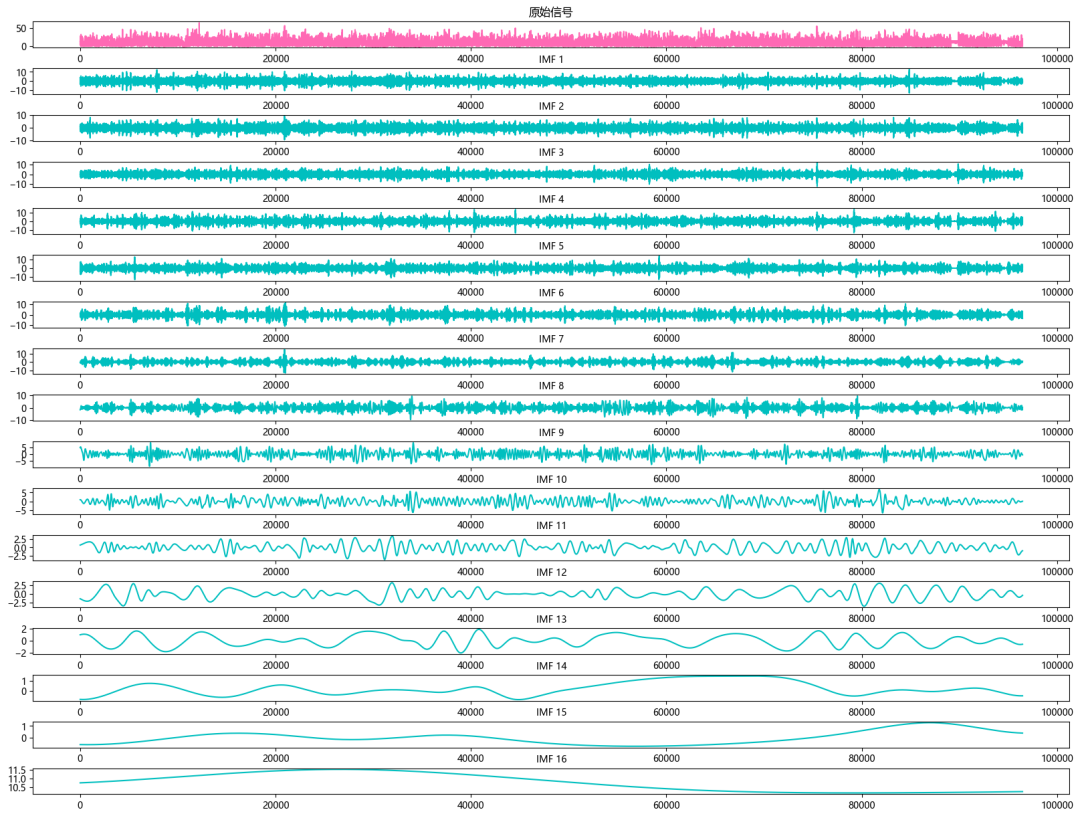
模型整体结构:数据集一共有天气、温度、湿度、气压、风速等九个变量,使用CEEMDAN算法对风速序列进行分解,然后合并所有的分量和原始数据集变量,形成一个 加强的特征输入 ,通过滑动窗口制作数据集,利用多变量来预测风速。 通过Transformer-BiLSTM提取加强后的特征,然后再送入全连接层,实现高精度的预测模型。
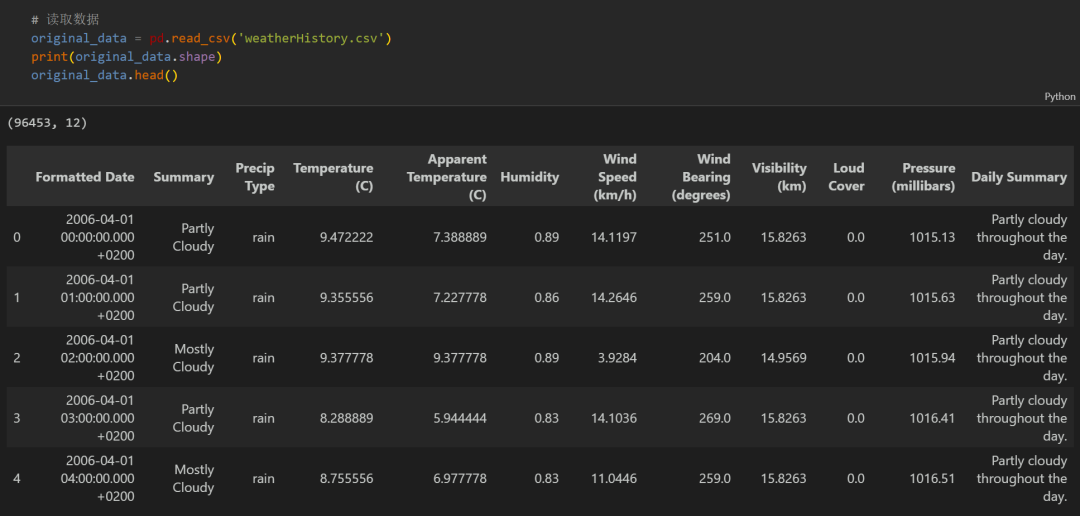
1 多特征变量数据集制作与预处理
1.1 导入数据
1.2 CEEMDAN分解
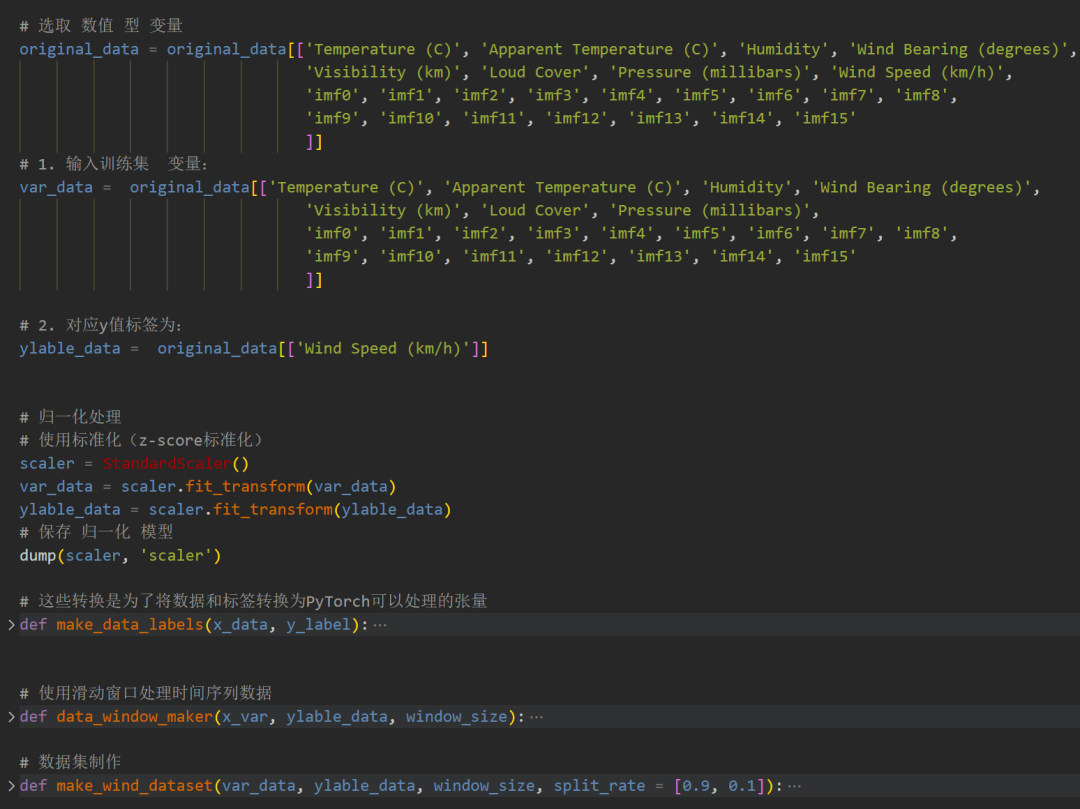
1.3 数据集制作与预处理
先合并原始数据变量和分解的分量,按照9:1划分训练集和测试集

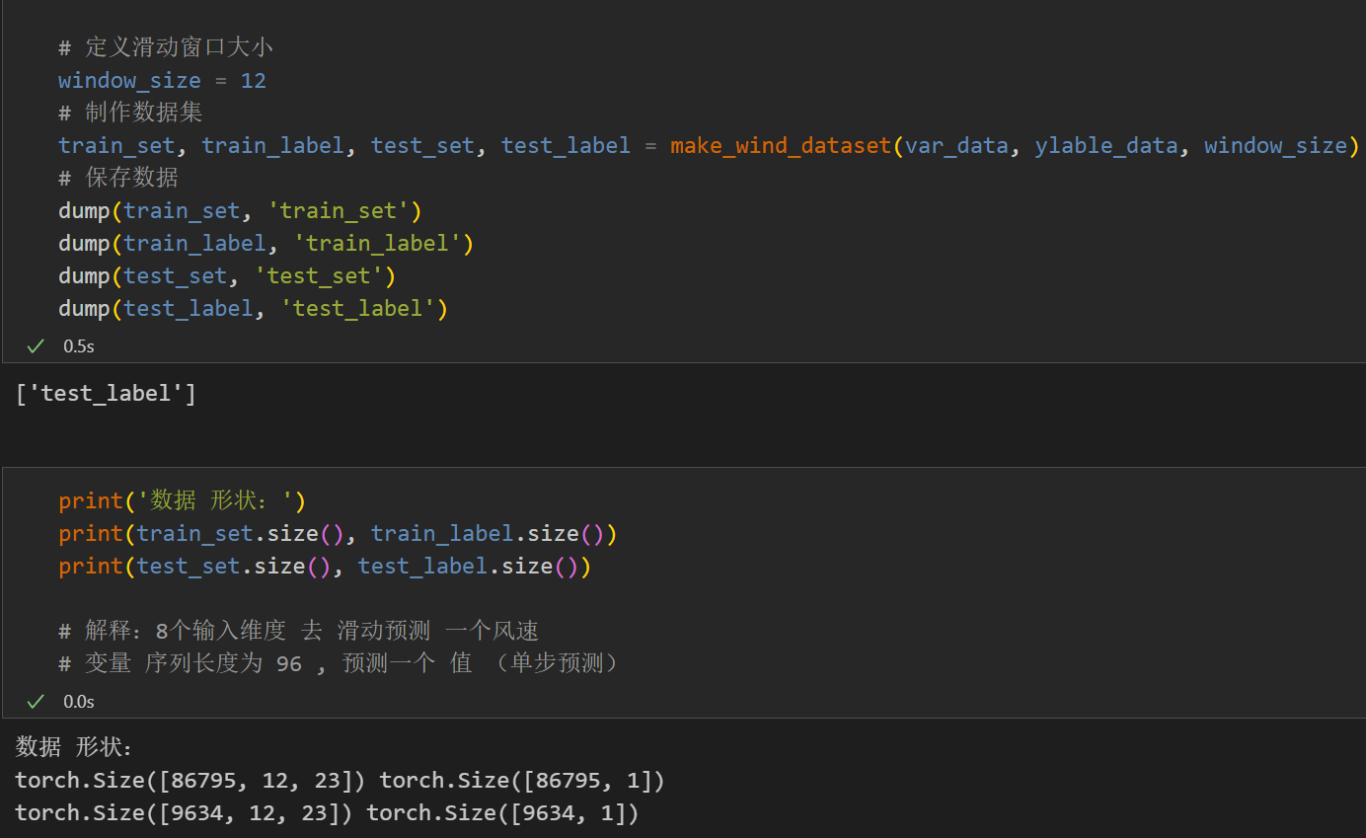
制作数据集
2 基于Pytorch的CEEMDAN + Transformer-BiLSTM 预测模型
2.1 定义CEEMDAN + Transformer-BiLSTM预测模型
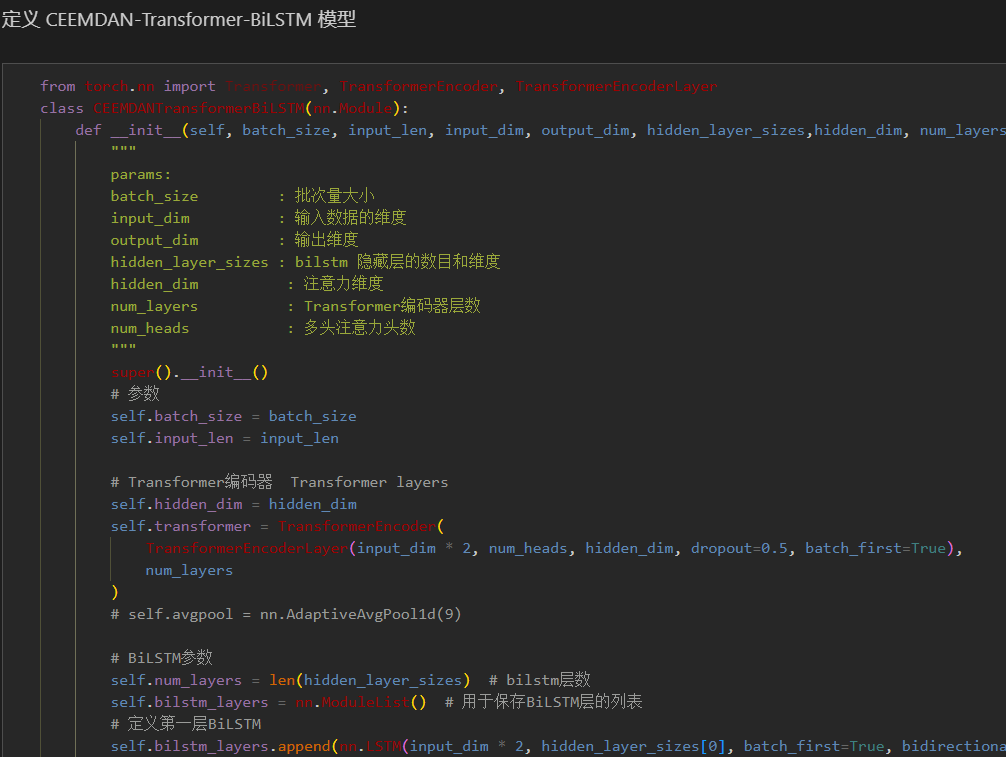
注意:输入风速数据形状为 [256, 24, 23], batch_size=256,24代表序列长度(滑动窗口取值), 维度23维代表挑选的8个变量和15个分量的维度。
在使用Transformer模型中的多头注意力时,输入维度必须能够被num_heads(注意力头的数量)整除。因为在多头注意力机制中,输入的嵌入向量会被分成多个头,每个头的维度是embed_dim / num_heads,因此embed_dim必须能够被num_heads整除,以确保能够均匀地分配给每个注意力头。
因为此时输入特征为23个,本文采用对数据进行对半切分堆叠,使输入形状为[256, 12, 46]。
2.2 设置参数,训练模型
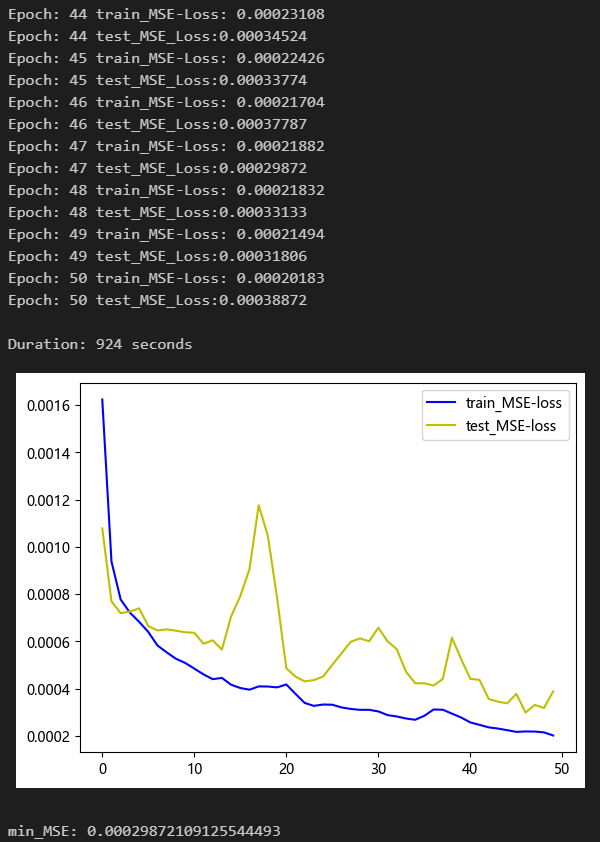
50个epoch,MSE 为0.000298,多变量特征CEEMDAN + Transformer-BiLSTM预测效果良好,加入CEEMDAN分解后,多变量预测效果提升明显,性能优越,适当调整模型参数,还可以进一步提高模型预测表现。
注意调整参数:
- 可以适当增加Transformer编码器层数和维度数,微调学习率;
- 调整BiLSTM层数和每层维度数,增加更多的 epoch (注意防止过拟合)
- 可以改变滑动窗口长度(设置合适的窗口长度)
3 模型评估与可视化
3.1 结果可视化
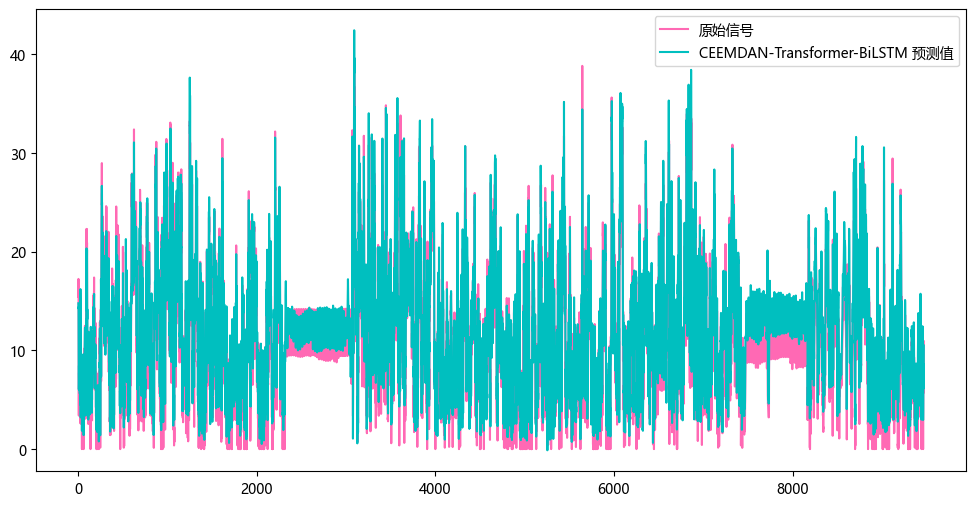
3.2 模型评估