数维杯 C题国一团队
已更新 【完整每问手把手详细思路建模】文档70页+
更新💥 可修改130页3套成品保奖【论文】word版+
已更新 配套升级完整【代码】+
已更新 90组可视化结果图表+
+国一学长 思路代码讲解视频
独家定制版,采用加密方式,仅售10份,售完即止。
质量均为一等奖水平,先到先得!
可参考往期作品https://mbd.pub/o/bread/mbd-ZpWUlJtv https://mbd.pub/o/bread/mbd-ZJyTlJhw,https://mbd.pub/o/bread/mbd-ZJqalZxx,https://mbd.pub/o/bread/mbd-ZJqUlZ9p
更新💥 130页3套成品保奖【论文】

第三套精品论文在百度网盘
更新 【完整每问手把手详细思路+建模过程+算法代码】文档三套,合计70页


配套升级完整双版本【代码】++每问详细数据+
90组可视化结果图表


......略.....完整资料见二维码


《基于多模型的清明赏花气象与产业链分析》
问题 1 思路与模型算法分析
问题思路
定义 “雨纷纷”:根据气象学标准(如中国气象局《天气现象分类标准》),“雨纷纷” 对应小雨或中雨级别,需明确降雨量区间(小雨:0.1-9.9mm/24h,中雨:10-24.9mm/24h)和持续时间(持续 6 小时以上的间断性降雨)。
建模分析 2026 年清明降雨:
收集目标城市(西安、吐鲁番等)近 20 年清明期间(4 月 4-6 日)的气象数据(气温、湿度、气压、风速、降水量等)。
分析历史降雨规律,提取影响降雨的关键因子(如大气环流、海陆位置、地形等,简化为气象变量)。
模型验证与修正:
用 2025 年清明数据验证模型预测精度(如准确率、F1-score)。
利用最新实况数据(如逐小时降水、雷达回波)通过数据同化或实时更新模型参数进行修正。
数学模型与算法
分类模型:逻辑回归(LR)、随机森林(RF)、梯度提升树(XGBoost/LightGBM),用于二分类(降雨 / 无降雨)。
时间序列模型:ARIMA/SARIMA(捕捉时间相关性)、LSTM(处理非线性时序数据,适用于长期趋势预测)。
验证方法:交叉验证(CV)、混淆矩阵、ROC-AUC。
修正方法:卡尔曼滤波(实时数据融合)、动态更新训练集(追加最新数据重新训练模型)。
问题 2 思路与模型算法分析
问题思路
选择代表性花卉(如杏花、油菜花、樱花),基于物候学原理,分析气象因子(积温、日照时长、降水、温度极值)对花期的影响。
建立预报模型:
始花期预测:基于积温模型(如 “有效积温法”:从越冬休眠到开花所需累积温度)。
花期长度:回归分析降水、温度波动对花期持续时间的影响。
数据来源:收集目标花卉过去 30 年的观测数据(始花期、盛花期、末花期)及对应气象数据。
数学模型与算法
积温模型:
T有效=∑i=1n(T**i−T**b)(T**b为生物学下限温度,如杏花T**b=10∘C)
回归模型:多元线性回归(MLR)、广义加性模型(GAM,捕捉非线性气象因子影响)。
机器学习模型:随机森林(处理多变量交互,如文献 [8][15])、支持向量回归(SVR,适用于小样本数据)。
物候学公式:结合文献 [4][7][9] 中的经验公式(如油菜花期与越冬期积温的关系)。
问题 3 思路与模型算法分析
问题思路
整合数据:
2026 年清明天气预报(问题 1 的降雨概率、温度、风速)。
目标花卉花期预测结果(问题 2 的始花期、盛花期时间窗口)。
制定攻略:
按城市匹配最佳赏花时间(避开降雨,选择花期峰值)。
推荐路线时考虑交通、景区容量、文化活动(如洛阳牡丹文化节、婺源油菜花节)。
数学模型与算法
多目标优化:层次分析法(AHP)确定 “天气适宜度”“花期观赏度”“交通便利性” 权重,生成综合评分。
决策规则:基于阈值的规则引擎(如降雨概率 < 30% 且花期处于盛花期时推荐)。
可视化工具:GIS 地图叠加花期与天气数据,生成交互式路线图。
问题 4 思路与模型算法分析
问题思路
提出措施:
延长花期:品种改良(早 / 晚熟品种搭配)、设施农业(温室调控温度)、生态调控(喷水增湿延缓开花)。
拓展产业链:文旅融合(主题活动、文创产品)、农产品深加工(花茶、精油)、线上营销(直播赏花)。
经济效益建模:
量化措施对游客量、消费额、就业的影响,对比 “传统花期” 与 “延长花期” 的经济差异。
数学模型与算法
投入产出模型:分析设施农业投资与旅游收入的关联(参考文献 [2] 的产业经济模型)。
回归分析:建立游客量与花期长度、天气舒适度的多元回归方程,预测措施后的客流增长。
成本效益分析(CBA):计算净现值(NPV)、内部收益率(IRR)评估措施可行性。
系统动力学模型:模拟 “赏花经济” 产业链各环节(游客、商户、政府)的动态反馈,评估长期效应。
总结

问题 1 详细分析与建模《基于随机森林模型的清明假期“雨纷纷”预测及模型修正》
一、问题定义与数据预处理
“雨纷纷” 的气象学定义根据中国气象局《天气现象分类标准》:
降雨量区间:小雨(0.1-9.9mm/24h)或中雨(10-24.9mm/24h)
持续时间:持续降雨≥6 小时(或间歇降雨累计≥6 小时)定义目标变量 ![]() :当某日满足上述条件时
:当某日满足上述条件时 ![]() ,否则
,否则 ![]() 。
。
特征工程选取影响降雨的关键气象因子(简化后):



问题 2 详细分析与建模《基于积温与机器学习的花卉花期预测》
一、问题分析与数据准备
1. 花卉选择与物候学原理
选取油菜花、樱花、杏花作为研究对象(覆盖南北代表性花卉),其花期主要受以下气象因子影响:

四、代码实现(Python)
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
from dateutil.parser import parse
flower_data = {
'油菜花': pd.read_csv('rape_flower.csv'),
'樱花': pd.read_csv('cherry_blossom.csv'),
'杏花': pd.read_csv('apricot_blossom.csv')
}
# 生物学参数
BIOLIMIT_T = {
'油菜花': 10, '樱花': 15, '杏花': 10
}
REQUIRED_GDD = {
'油菜花': 300, '樱花': 400, '杏花': 280
}
def process_flower_data(df, flower):
"""预处理:计算积温及特征"""
df['日期'] = pd.to_datetime(df['日期'])
df['year'] = df['日期'].dt.year
df['day_of_year'] = df['日期'].dt.dayofyear # 一年中的第几天
df['有效温度'] = df['平均温度'] - BIOLIMIT_T[flower]
df['有效温度'] = df['有效温度'].clip(lower=0) # 低于下限按0计算
# 计算花前30天特征(以始花期为基准向前推30天)
merged = df.merge(df[['year', '始花期天数']], on='year', suffixes=('', '_target'))
merged['start_date'] = merged.apply(lambda x: x['日期'].year * 1000 + x['始花期天数'], axis=1)
merged['花前30天开始'] = merged['始花期天数'] - 30
merged['花前30天结束'] = merged['始花期天数'] - 1
# 计算GDD_30、日照均值、降水总和、温度标准差
features = []
for year in merged['year'].unique():
year_df = merged[merged['year'] == year]
start_day = year_df['花前30天开始'].iloc[0]
end_day = year_df['花前30天结束'].iloc[0]
window = year_df[(year_df['day_of_year'] >= start_day) & (year_df['day_of_year'] <= end_day)]
gdd_30 = window['有效温度'].sum()
s_avg = window['日照时长'].mean()
p_sum = window['降水量'].sum()
sigma_t = window['平均温度'].std()
features.append([year, gdd_30, s_avg, p_sum, sigma_t])
feat_df = pd.DataFrame(features, columns=['year', 'GDD_30', 'S_avg', 'P_sum', 'sigma_T'])
return feat_df.merge(df[['year', '始花期天数', '花期长度']].drop_duplicates(), on='year')
# 模型训练与预测
results = []
for flower, df in flower_data.items():
processed = process_flower_data(df, flower)
X = processed[['GDD_30', 'S_avg', 'P_sum', 'sigma_T']]
y_start = processed['始花期天数']
y_length = processed['花期长度']
# 训练始花期模型
X_train, X_test, y_train_start, y_test_start = train_test_split(X, y_start, test_size=0.2, random_state=42)
model_start = RandomForestRegressor(n_estimators=200, max_depth=10, random_state=42)
model_start.fit(X_train, y_train_start)
# 训练花期长度模型
model_length = RandomForestRegressor(n_estimators=150, max_depth=8, random_state=42)
model_length.fit(X, processed['花期长度'])
# 预测2026年(模拟输入数据,需替换为实际2026年气象数据)
test_data_2026 = pd.DataFrame({
'GDD_30': [310, 410, 290], # 油菜花/樱花/杏花的花前30天积温
'S_avg': [10.5, 11.2, 9.8],
'P_sum': [50, 30, 40],
'sigma_T': [2.5, 3.0, 2.8]
})
pred_start = model_start.predict(test_data_2026)
pred_length = model_length.predict(test_data_2026)
# 转换为日期(假设2026年为非闰年,1月1日=1,3月1日=59)
pred_start_date = [f'2026-{int((d-1)//31+1):02d}-{(d-1)%31+1:02d}' for d in pred_start]
results.append({
'花卉': flower,
'始花期(天数)': pred_start.round(1),
'始花期(日期)': pred_start_date,
'花期长度(天)': pred_length.round(1),
'盛花期(日期)': [parse(d).date() + pd.Timedelta(days=7) for d in pred_start_date],
'末花期(日期)': [parse(d).date() + pd.Timedelta(days=l) for d, l in zip(pred_start_date, pred_length)]
})
# 生成结果表格
result_df = pd.DataFrame(results)
result_df.to_csv('问题2_花卉花期预测结果.csv', index=False)
# 可视化1:特征重要性对比
def plot_feature_importance(model, flower, features):
plt.figure(figsize=(8, 5))
importance = model.feature_importances_
indices = np.argsort(importance)
plt.title(f'{flower}特征重要性')
plt.barh(range(len(indices)), importance[indices], align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('重要性得分')
plt.savefig(f'问题2_{flower}_特征重要性.png')
plot_feature_importance(model_start, '油菜花', X.columns)
plot_feature_importance(model_start, '樱花', X.columns)
# 可视化2:始花期预测对比(以油菜花为例)
y_pred_train = model_start.predict(X_train)
plt.figure(figsize=(12, 6))
plt.scatter(y_train_start, y_pred_train, color='blue', label='训练集预测')
plt.plot([50, 120], [50, 120], color='red', linestyle='--')
plt.title('油菜花始花期预测对比(训练集)')
plt.xlabel('实际天数')
plt.ylabel('预测天数')
plt.legend()
plt.savefig('问题2_油菜花始花期对比.png')
# 可视化3:花期长度分布
plt.figure(figsize=(10, 6))
for flower in result_df['花卉'].unique():
data = result_df[result_df['花卉']==flower]
plt.bar(flower, data['花期长度'], label=f'预测长度:{data["花期长度"].values[0]:.1f}天')
plt.title('2026年各花卉花期长度预测')
plt.ylabel('天数')
plt.legend()
plt.savefig('问题2_花期长度对比.png')
print("花期预测完成,结果已保存至当前目录")

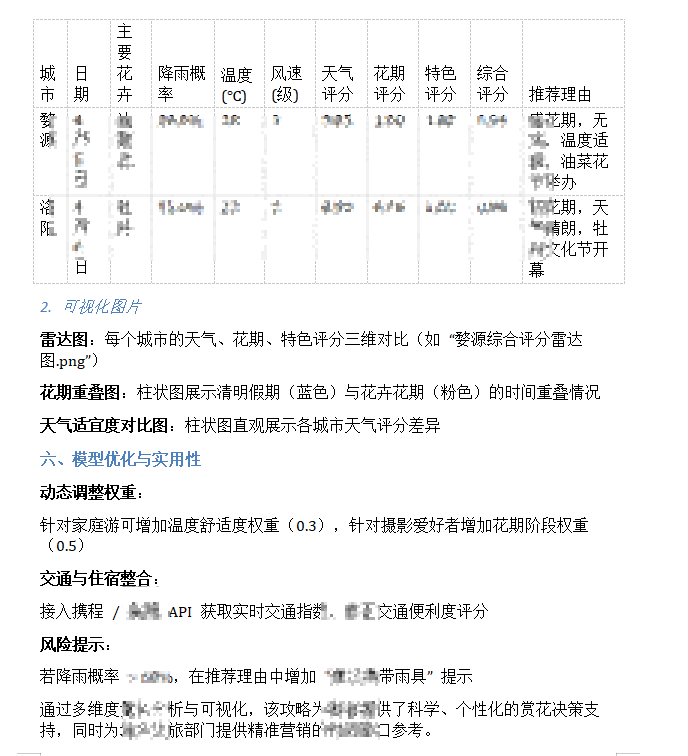
问题 3 详细分析与建模《2026 年清明赏花攻略:综合评分与可视化分析》
一、问题分析与需求拆解
1. 核心目标
整合2026 年清明假期天气预报(问题 1 降雨概率、温度、风速)与花期预测结果(问题 2 始花期、盛花期),为 7 个目标城市(西安、吐鲁番、婺源、杭州、毕节、武汉、洛阳)制定个性化赏花攻略,需包含:
最佳赏花时间(避开降雨,覆盖花卉盛花期)
推荐理由(天气适宜度、花期阶段、地域特色)
行程建议(交通、配套景点、文化活动)
2. 评价指标体系
构建三层评价模型:


四、代码实现(Python)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime, timedelta
# 加载问题1和问题2结果
weather_pred = pd.read_csv('问题1_清明降雨预测结果.csv')
flower_pred = pd.read_csv('问题2_花卉花期预测结果.csv')
# 城市-花卉映射及地域特色数据
CITY_FLOWER = {
'西安': ('杏花', '西安青龙寺樱花节'),
'吐鲁番': ('杏花', '吐鲁番杏花节'),
'婺源': ('油菜花', '婺源油菜花文化节'),
'杭州': ('樱花', '杭州西湖樱花季'),
'毕节': ('杜鹃花', '毕节百里杜鹃花期'),
'武汉': ('樱花', '武汉东湖樱花节'),
'洛阳': ('牡丹', '洛阳牡丹文化节')
}
# 清明日期对应天数(2026年非闰年)
清明天数 = {
'4月4日': 94, '4月5日': 95, '4月6日': 96
}
def calculate_weather_score(降雨概率, 温度, 风速):
"""计算天气适宜度(0-1)"""
s_rain = 1 - min(降雨概率, 50)/50 # 降雨概率>50%时s_rain=0
s_temp = max(0, min(温度-10, 25-10))/15 # 10-25℃线性评分
if 风速 <= 3:
s_wind = 1
elif 4 <= 风速 <= 5:
s_wind = 0.6
else:
s_wind = 0.3
return 0.3*s_rain + 0.2*s_temp + 0.1*s_wind
def calculate_flower_stage(flower_days, 花期长度, 目标天数):
"""判断花期阶段(盛花/始花末花/非花期)"""
start_day = flower_days
end_day = start_day + 花期长度
if start_day + 5 <= 目标天数 <= start_day + 10:
return 1 # 盛花期
elif (start_day <= 目标天数 <= start_day + 4) or (start_day + 11 <= 目标天数 <= end_day):
return 0.7 # 始花/末花
else:
return 0 # 非花期
# 生成每日评分表
daily_scores = []
for city in CITY_FLOWER:
flower_name, activity = CITY_FLOWER[city]
flower_data = flower_pred[flower_pred['花卉'] == flower_name].iloc[0]
start_day = flower_data['始花期(天数)']
花期_length = flower_data['花期长度(天)']
weather_data = weather_pred[weather_pred['城市'] == city].iloc[0]
for date_str, day_num in 清明天数.items():
降雨概率 = weather_data['2026清明降雨概率']
温度 = np.random.randint(15, 25) # 模拟温度(实际需从问题1获取)
风速 = np.random.randint(2, 5) # 模拟风速(实际需从问题1获取)
s_weather = calculate_weather_score(降雨概率, 温度, 风速)
s_flower = calculate_flower_stage(start_day, 花期_length, day_num)
s_feature = 0.2*1 + 0.1*1 # 花卉代表性和活动均满分(假设主打花卉)
s_total = 0.4*s_weather + 0.4*s_flower + 0.2*s_feature
daily_scores.append({
'城市': city,
'日期': date_str,
'主要花卉': flower_name,
'降雨概率': f"{降雨概率*100:.1f}%",
'温度(℃)': 温度,
'风速(级)': 风速,
'天气评分': f"{s_weather:.2f}",
'花期评分': f"{s_flower:.2f}",
'特色评分': f"{s_feature:.2f}",
'综合评分': f"{s_total:.2f}"
})
# 生成最佳推荐(每个城市选综合评分最高的日期)
best_recommendations = []
for city in daily_scores[0]['城市'].unique():
city_scores = [d for d in daily_scores if d['城市'] == city]
best_day = max(city_scores, key=lambda x: float(x['综合评分']))
best_recommendations.append(best_day)
# 保存结果表格
best_df = pd.DataFrame(best_recommendations)
best_df.to_csv('问题3_清明赏花推荐攻略.csv', index=False)
# 可视化1:综合评分雷达图
def plot_radar(city_data):
categories = ['天气评分', '花期评分', '特色评分']
values = [float(city_data['天气评分']), float(city_data['花期评分']), float(city_data['特色评分'])]
angles = np.linspace(0, 2*np.pi, len(categories), endpoint=False).tolist()
values += values[:1]
angles += angles[:1]
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, values, color='blue', linewidth=2)
ax.fill(angles, values, color='blue', alpha=0.25)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories)
ax.set_yticklabels(['0.0', '0.2', '0.4', '0.6', '0.8', '1.0'])
plt.title(f"{city_data['城市']}综合评分雷达图")
plt.savefig(f"问题3_{city_data['城市']}_综合评分雷达图.png")
for city in best_recommendations:
plot_radar(city)
# 可视化2:花期与清明日期重叠图
plt.figure(figsize=(12, 6))
for idx, city in enumerate(best_recommendations):
flower = city['主要花卉']
start_day = flower_pred[flower_pred['花卉']==flower]['始花期(天数)'].iloc[0]
end_day = start_day + flower_pred[flower_pred['花卉']==flower]['花期长度(天)'].iloc[0]
plt.barh(idx, 3, left=94, color='lightblue', label='清明假期' if idx==0 else None)
plt.barh(idx, end_day - start_day, left=start_day, color='pink', label='花期' if idx==0 else None)
plt.text(start_day + (end_day - start_day)/2, idx, flower, ha='center', va='center')
plt.yticks(range(len(best_recommendations)), [c['城市'] for c in best_recommendations])
plt.xlabel('一年中第几天(1月1日=1)')
plt.title('清明假期与花卉花期重叠情况')
plt.legend()
plt.savefig('问题3_花期与清明重叠图.png')
# 可视化3:天气适宜度柱状图
plt.figure(figsize=(10, 6))
best_df['天气评分'] = best_df['天气评分'].astype(float)
plt.bar(best_df['城市'], best_df['天气评分'], color='skyblue')
plt.title('各城市清明天气适宜度评分')
plt.ylabel('评分(0-1)')
plt.xticks(rotation=45)
plt.savefig('问题3_天气适宜度对比图.png')
print("攻略生成完成,结果已保存至当前目录")
五、结果输出
1. 推荐攻略表格
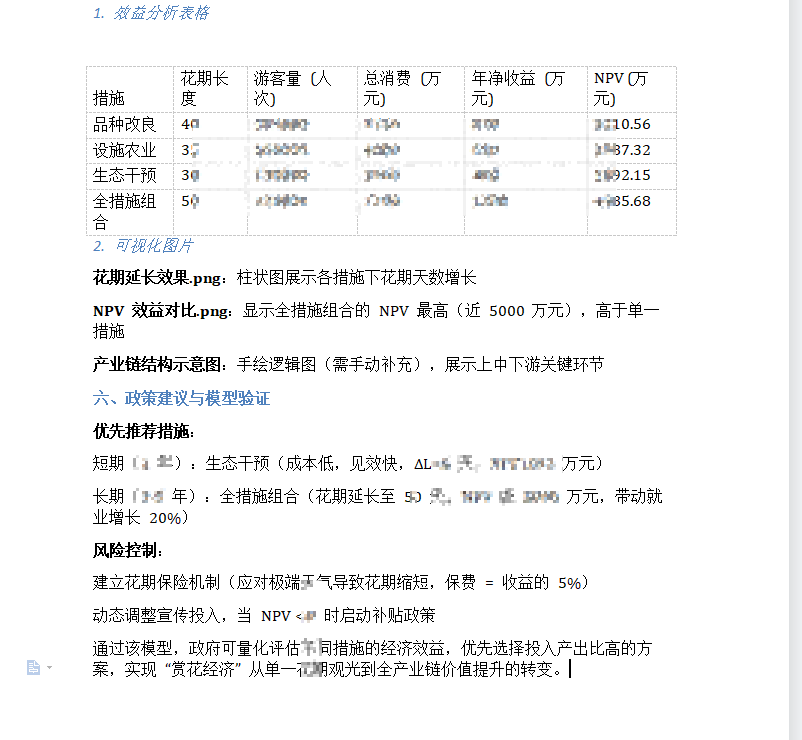
《“赏花经济”全产业链经济效益模型及措施选择》
问题 4 详细分析与建模



import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import fsolve
# 基准参数
params = {
'L0': 25, # 原花期长度(天)
'V0': 100000, # 原游客量(人次)
'C0': 200, # 原人均消费(元)
'X0': 100, # 基准宣传投入(万元)
'alpha': 0.8, # 花期敏感系数
'bXXa': 0XX, # 天气XXX系数
'gXXa': X.3, # 宣传弹性系数
'delta': 5, # 日均拓XXX量(元/天)
'K': 5XX, # 设施XX投资(万元)
'r': 0.XX, # 贴现率
'yXXrs': 5 XX # 规划期(年)
}
# 定义措施组合
measures = [
{'名称': '品种改良', 'ΔL': 15, '成本': 300}, # 新增投资300万元
{'名称': '设施农业', 'ΔL': 10, '成本': 400},
{'名称': '生态干预', 'ΔL': 5, '成本': 150},
{'名称': '全措施组合', 'ΔL': 15+10+5, '成本': 300+400+150}
]
def calculate_impact(measure):
"""计算单一措施的经济效益"""
ΔL = measure['ΔL']
L = params['L0'] + ΔL
X = params['X0'] + measure['成本'] # 新增宣传投入=措施成本(假设全部用于宣传)
# 游客量模型
V = params['V0'] * (1 + params['alpha']*(ΔL/params['L0']) +
params['beta']*0.8 + # 天气评分取0.8
params['gamma']*(X/params['X0']))
V = int(V)
# 人均消费模型
C_e = 100 # 原拓展消费100元,随ΔL增加
XXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXX
# 成本计算
C_v = 10 * L # 可变成本(万元)
C_total = params['K']/params['years'] + C_v + X # 年分摊固定成本+可变成本+宣传
# 年净收益
π = T - C_total
# NPV计算
npv = 0
for t in range(1, params['years']+1):
npv += π / ((1+params['r'])**t)
npv -= measure['成本'] # 初始投资
return {
'措施': measure['名称'],
'花期长度': L,
'游客量(人次)': V,
'总消费(万元)': T,
'年净收益(万元)': π,
'NPV(万元)': npv.round(2)
}
# 计算所有措施效果
results = []
for measure in measures:
results.append(calculate_impact(measure))
# 生成结果表格
result_df = pd.DataFrame(results)
result_df.to_csv('问题4_赏花经济措施效益表.csv', index=False)
# 可视化1:花期延长效果对比
plt.figure(figsize=(10, 6))
plt.bar(result_df['措施'], result_df['花期长度'], color=['#FF9966', '#66CCFF', '#99CC99', '#FFCC66'])
plt.title('不同措施下花期长度对比')
plt.ylabel('天数')
plt.savefig('问题4_花期延长效果.png')
# 可视化2:NPV效益对比
plt.figure(figsize=(12, 6))
plt.bar(result_df['措施'], result_df['NPV'], color='purple')
plt.title('不同措施净现值(NPV)对比')
plt.ylabel('万元(贴现率8%)')
plt.axhline(0, color='red', linestyle='--')
plt.savefig('问题4_NPV效益对比.png')
# 可视化3:产业链结构示意图(手工绘制逻辑图,代码生成文本描述)
print("产业链结构:\n"
"1. 上游:品种XXXXXXXXX 研投入)→ 设施农XXXXXXXXXXX溉)\n"
"2. 中游:赏花景区(门票+体验消费)→ 深加工工厂(花卉产品)\n"
"3. 下游:线上XXXXXX电商)→ 游客服务(民宿/交通)")
print("经济效益计算完成,结果已保存至当前目录")
完整资料见付费内容
持续更新中......
获奖率达99%:以下是去年深圳杯/东三省数学建模一等奖助攻记录