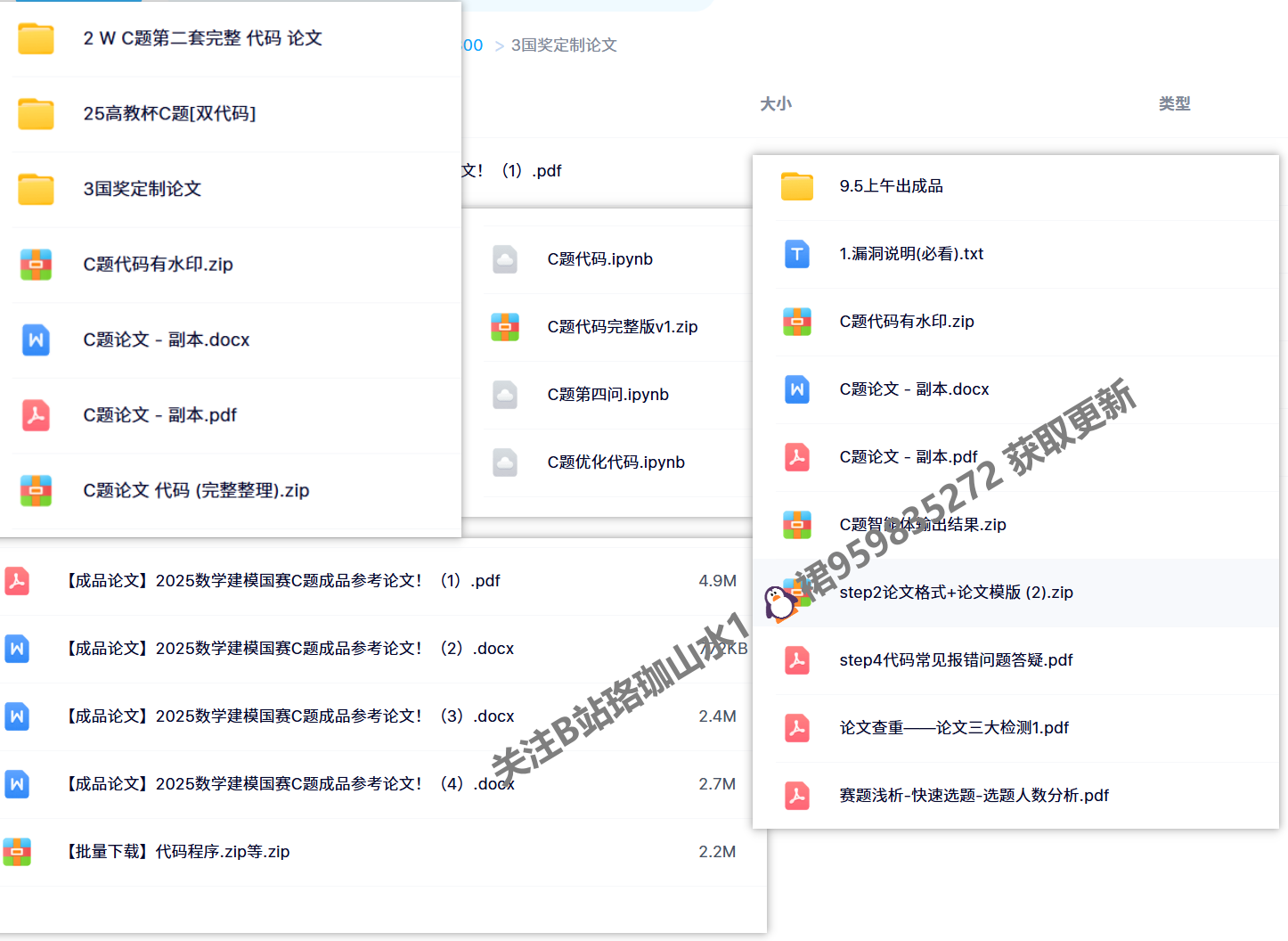
25数模国赛 C题国一团队
已更新 【完整每问手把手详细思路】60页+
!更新 💥 可修改200页4套成品保奖【论文】无水印word版+
已更新 配套升级求解【代码】总计6000多行!+
185组 各类可视化图表+
+国一学长 思路代码讲解视频+
售后群一对一答疑辅导
独家定制版,采用加密方式一对一发送,售完即止。
🔥C题限量冲奖论文,全网独家原创独一份,不是烂大街的论文可比,全网没有被泄露过🔥
点击下方链接获取
https://mbd.pub/o/bread/mbd-YZWXlZ5vaQ==
9/7 更新 💥 可修改冲国奖成品【论文】无水印word版


论文细节:






完整资料见 付费内容....
9/5 !更新 💥 可修改150页3套成品保奖【论文】无水印word版




..................
质量均为一等奖水平,先到先得!
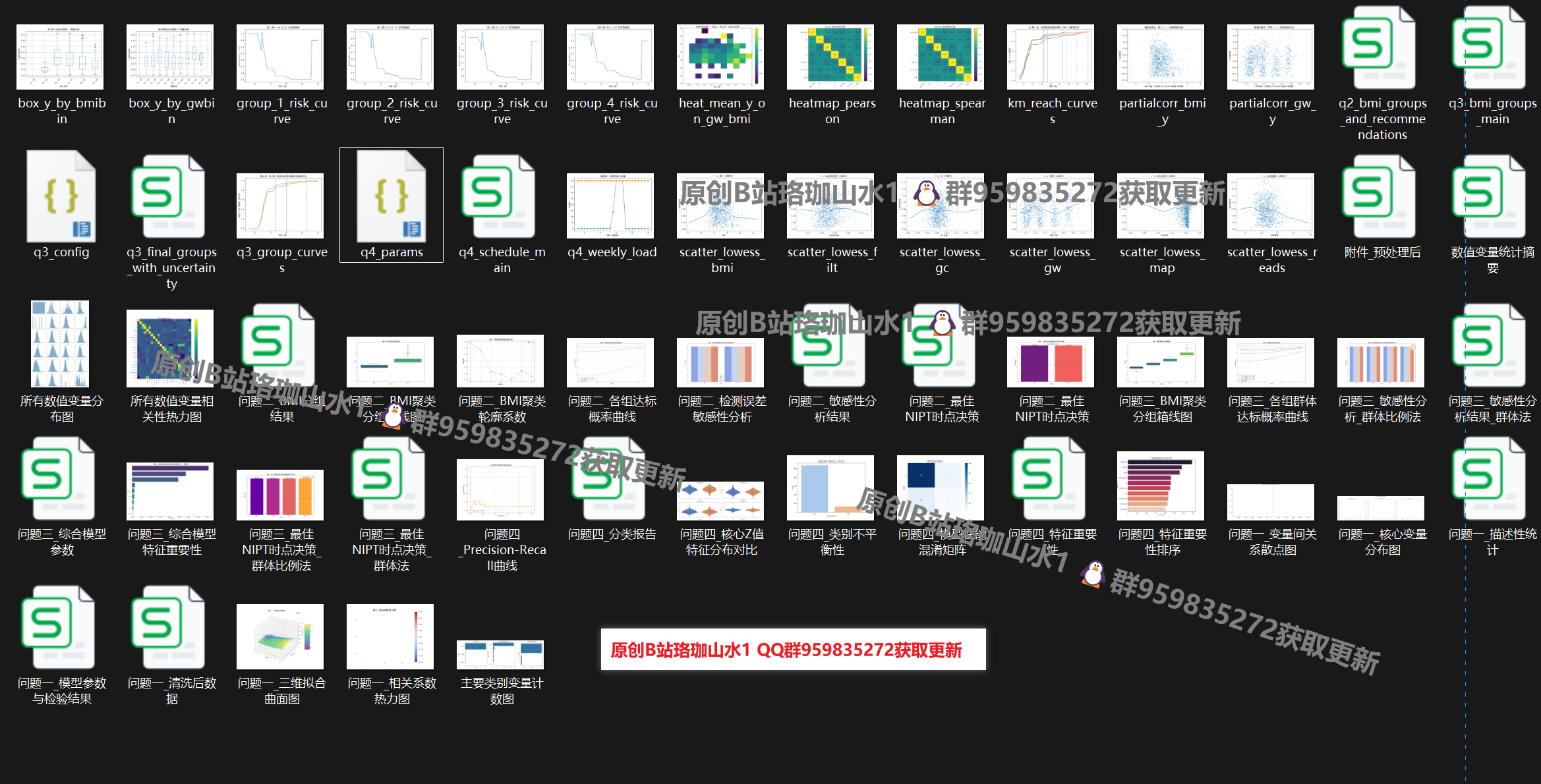
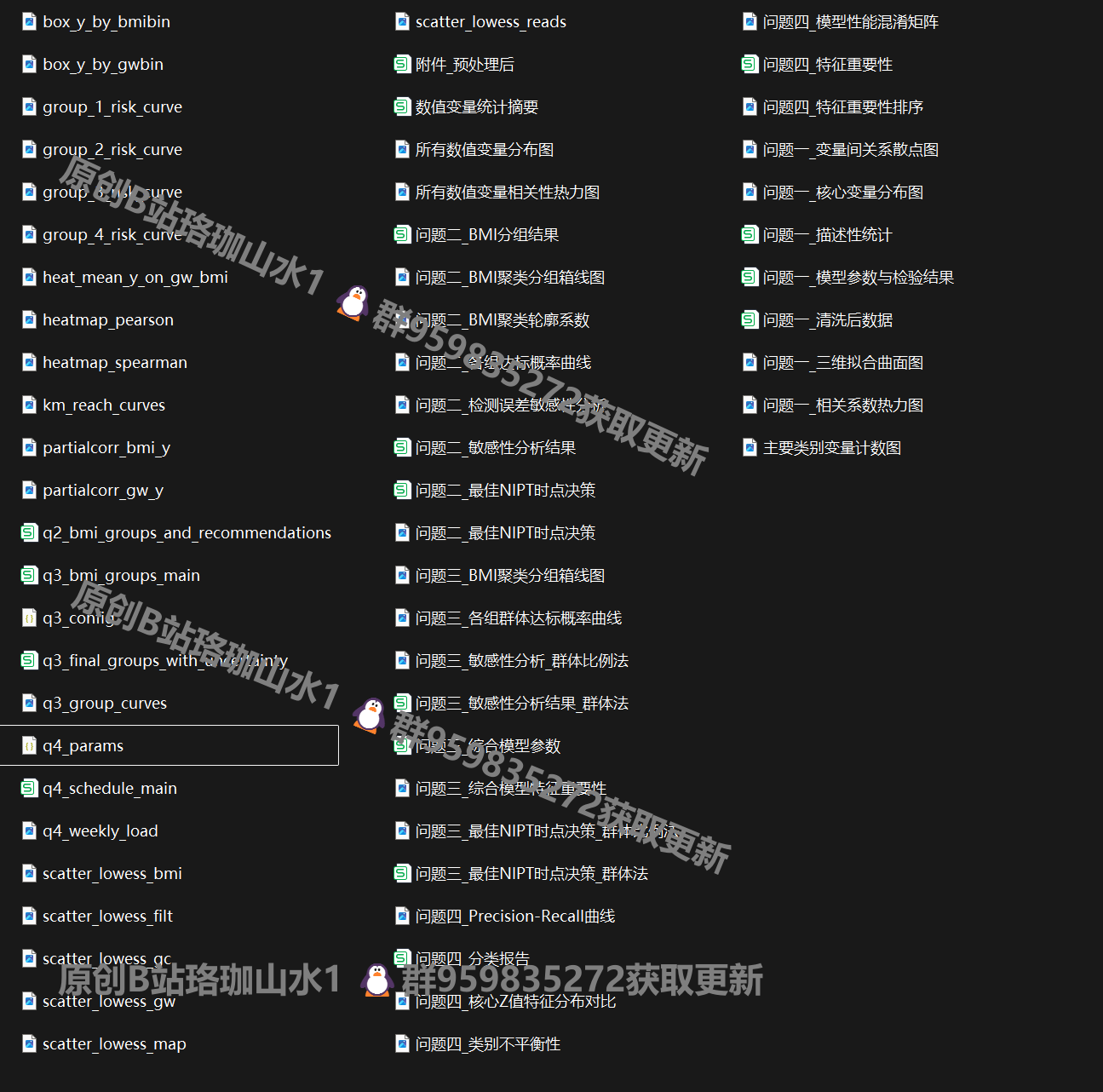
可参考往期作品https://mbd.pub/o/bread/mbd-YZWUk5xraQ== https://mbd.pub/o/bread/mbd-ZJyTlppv https://mbd.pub/o/bread/mbd-ZJyTlphr,https://mbd.pub/o/bread/mbd-ZpicmJhy,https://mbd.pub/o/bread/mbd-ZJqUlZ9p
此外,本链接提供售后服务,包括但不限于论文写作修改,模型思路,编程辅导等,全程手把手指导拿奖。会提供降重教程和可替换的思路模型文档+售后群一对一答疑辅导
C论文第一套

第二套精品


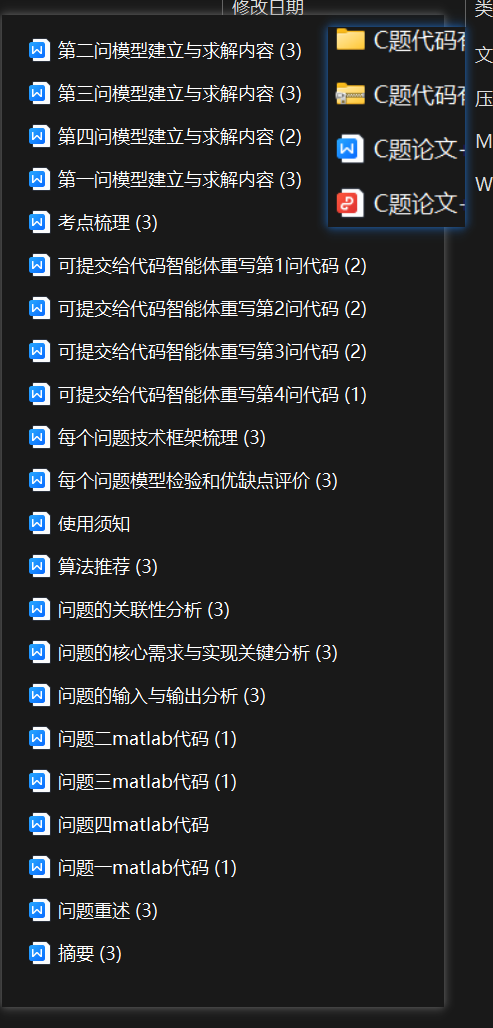
部分代码:



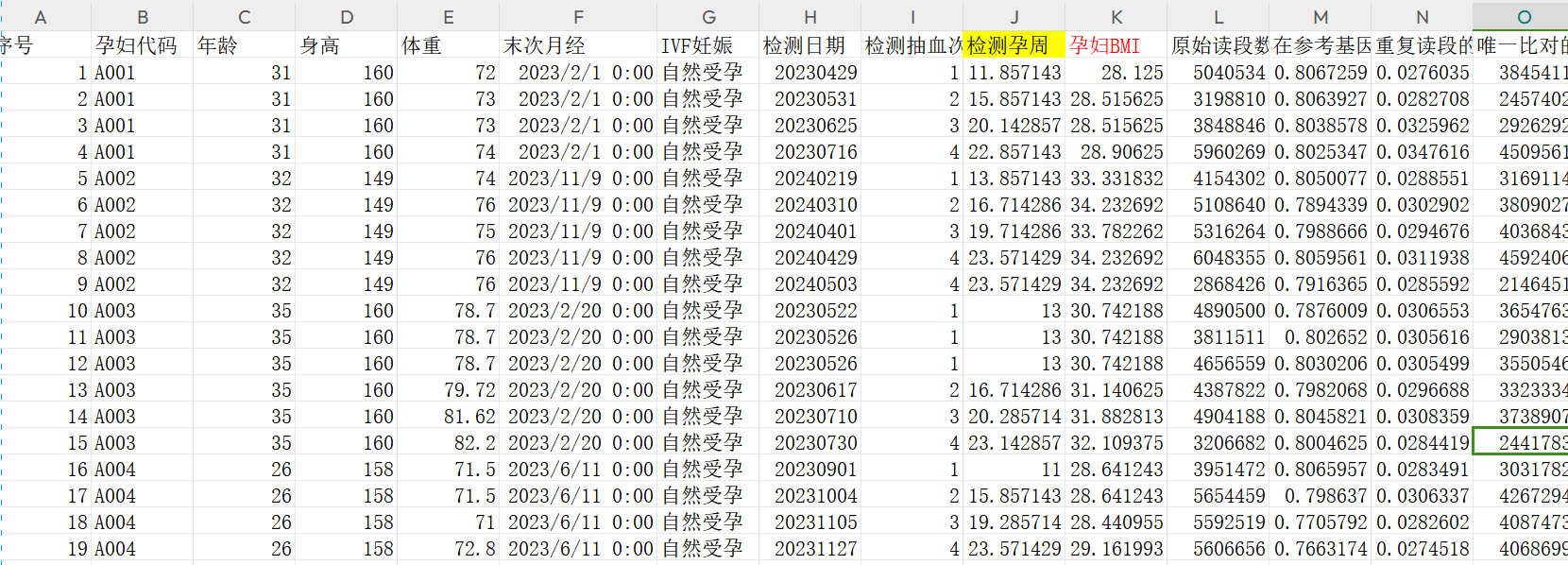
预处理后数据
% 主程序:问题一模型求解
% 功能:实现数据预处理、相关性分析、混合效应模型拟合、显著性检验及假设检验
clear; clc;
%% ------------------------------
%% 自定义函数1:转换孕周字符串为数值
%% ------------------------------
function gestation_weeks = parse_gestation(gest_str)
% 输入:孕周字符串数组(如'13w', '20w+1')
% 输出:连续型孕周数值(如13, 20.1429)
n = length(gest_str);
gestation_weeks = zeros(n, 1); % 初始化输出数组
for i = 1:n
s = gest_str{i};
% 正则表达式:匹配"Xw"(周数)或"Xw+Y"(周数+天数)
expr = '^(\d+)w(?:\+(\d+))?$';
tokens = regexp(s, expr, 'tokens'); % 提取匹配的数值
if ~isempty(tokens)
weeks = str2double(tokens{1}{1}); % 提取周数
if length(tokens{1}) == 2 % 存在天数
days = str2double(tokens{1}{2}); % 提取天数
gestation_weeks(i) = weeks + days/7; % 转换为连续孕周(1周=7天)
else
gestation_weeks(i) = weeks; % 无天数时直接取周数
end
else
gestation_weeks(i) = NaN; % 无效格式标记为缺失值
end
end
end
%% ------------------------------
%% 自定义函数2:Breusch-Pagan同方差检验
%% ------------------------------
function [lm_stat, p_val] = breusch_pagan(residuals, X)
% 输入:残差向量residuals,自变量矩阵X(不含截距)
% 输出:LM统计量,p值(检验残差是否同方差)
n = length(residuals);
res_sq = residuals.^2; % 残差平方(核心变量:同方差检验的因变量)
% 残差平方对自变量回归(含截距,检验残差方差与自变量的关联)
X_with_intercept = [ones(n,1), X]; % 添加截距项
b = X_with_intercept \ res_sq; % 普通最小二乘估计
res = res_sq - X_with_intercept*b; % 回归残差
% 计算决定系数R²(衡量自变量对残差平方的解释能力)
ss_total = sum((res_sq - mean(res_sq)).^2); % 总平方和
ss_res = sum(res.^2); % 残差平方和
R2 = 1 - ss_res/ss_total;
% LM统计量(n*R²,服从卡方分布,自由度=自变量个数)
lm_stat = n * R2;
df = size(X,2); % 自变量个数(自由度)
p_val = 1 - chi2cdf(lm_stat, df); % 卡方检验p值
end
%% ------------------------------
%% 自定义函数3:计算方差膨胀因子(VIF)
%% ------------------------------
function vif = vif_calculation(X)
% 输入:自变量矩阵X(每列对应一个自变量)
% 输出:每个自变量的VIF值(VIF>5表示存在严重共线性)
[n, k] = size(X);
vif = zeros(k, 1); % 初始化VIF数组
for i = 1:k
% 第i个自变量对其他自变量回归(检验该变量的线性冗余)
X_rest = X(:, [1:i-1, i+1:k]); % 排除第i个自变量
X_rest_with_intercept = [ones(n,1), X_rest]; % 添加截距项
% 计算决定系数R²(衡量其他变量对第i个变量的解释能力)
b = X_rest_with_intercept \ X(:,i); % 回归系数
res = X(:,i) - X_rest_with_intercept*b; % 回归残差
ss_total = sum((X(:,i) - mean(X(:,i))).^2); % 总平方和
ss_res = sum(res.^2); % 残差平方和
R2 = 1 - ss_res/ss_total;
% VIF公式:1/(1-R²)(R²越大,共线性越严重)
vif(i) = 1/(1 - R2);
end
end
%% ------------------------------
%% 1. 数据预处理(对应模型约束条件)
%% ------------------------------
% 读取原始数据(保留中文列名,需确保Excel文件存在且路径正确)
data = readtable('男胎检测数据.xlsx', 'VariableNamingRule', 'preserve');
% (1) 孕周字符串转连续数值
gest_str = data.('孕妇本次检测时的孕周'); % 读取孕周字符串(cell数组)
gestation_weeks = parse_gestation(gest_str); % 转换为连续孕周
data.('检测孕周') = gestation_weeks; % 添加到数据表
% (2) Y染色体浓度修正(负值设为0,符合生物学意义)
Y_conc_raw = data.('Y染色体浓度'); % 原始Y浓度
Y_conc = max(Y_conc_raw, 0); % 非负约束
data.('Y染色体浓度修正') = Y_conc;
% (3) 孕妇身高转换为米(便于后续模型计算)
height_cm = data.('孕妇身高'); % 身高(厘米)
height_m = height_cm / 100; % 转换为米
data.('孕妇身高米') = height_m;
% (4) 样本筛选(严格质控:无缺失+GC正常+孕周有效+测序质量达标)
GC_content = data.('GC含量'); % GC含量
mapping_rate = data.('总读段数中在参考基因组上比对的比例'); % 比对比例
duplicate_rate = data.('总读段数中重复读段的比例'); % 重复比例
filter_rate = data.('被过滤掉的读段数占总读段数的比例'); % 过滤比例
% 筛选逻辑:所有条件必须同时满足(&表示“且”)
valid_sample = ~isnan(gestation_weeks) & ~isnan(data.('孕妇BMI指标')) & ~isnan(data.('孕妇年龄')) ...
& ~isnan(height_m) & ~isnan(data.('孕妇体重')) & ~isnan(GC_content) & ~isnan(Y_conc) ...
& (GC_content >= 0.4) & (GC_content <= 0.6) & (gestation_weeks >= 10) & (gestation_weeks <= 25) ...
& (mapping_rate >= 0.7) & (duplicate_rate <= 0.05) & (filter_rate <= 0.03);
data_clean = data(valid_sample, :); % 筛选后的数据表
n_sample = height(data_clean); % 有效样本量
完整4问代码:

问题1:相关特性分析与关系模型
思路步骤:
- 数据预处理与探索性分析 (EDA):
- 筛选数据:仅保留男胎样本数据(Y染色体浓度 V > 0)。
- 数据清洗:处理缺失值和明显的异常值。
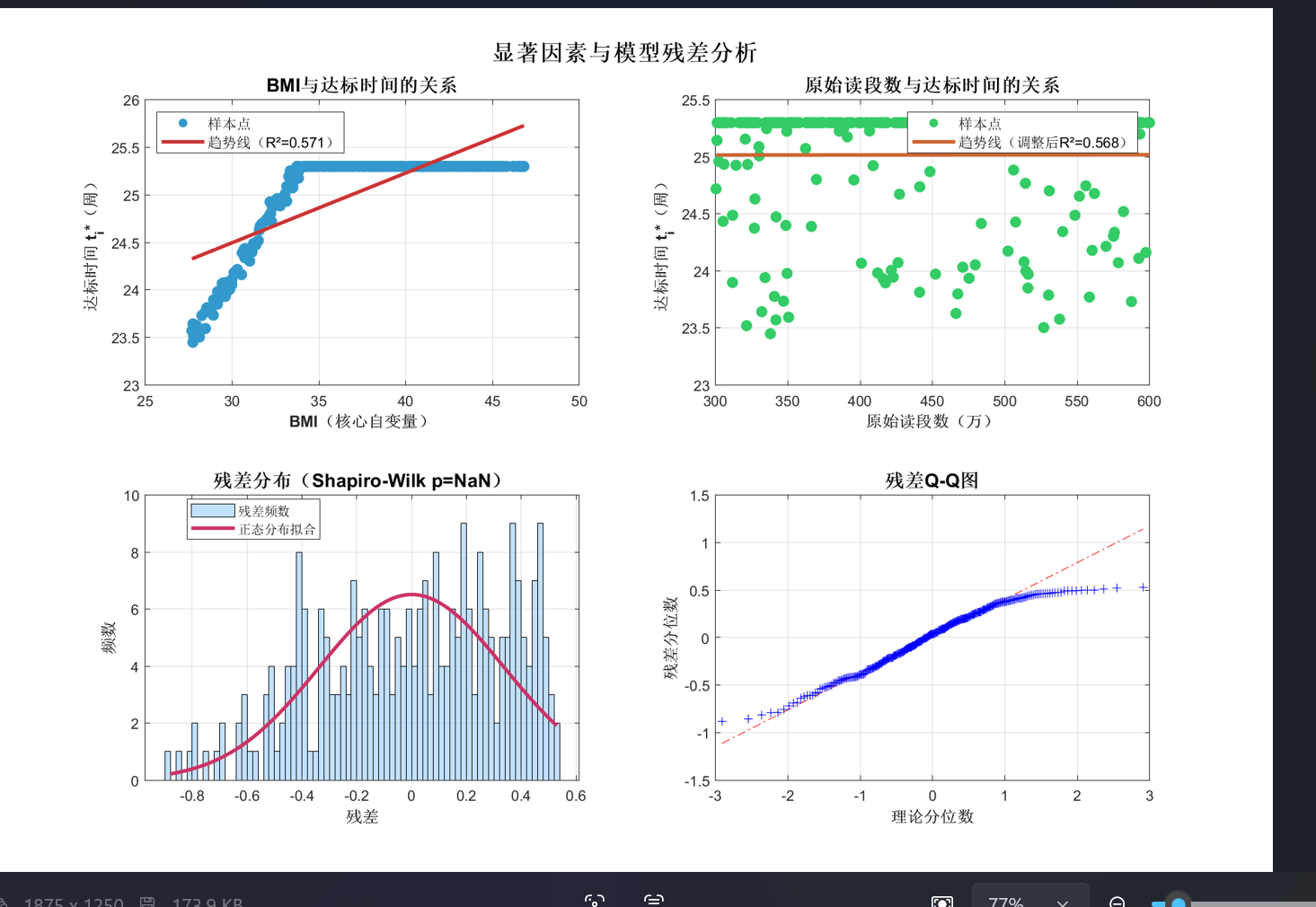
- 可视化分析:绘制Y染色体浓度(V)关于孕周数(J)和BMI(K)的散点图、热力图或三维曲面图,初步判断它们之间的相关性趋势(线性、非线性、单调性等)。
- 模型建立:
- 基于EDA的观察,选择合适的模型。首选多元线性回归模型,建立 V 与 J 和 K 的关系:
V = β₀ + β₁ * J + β₂ * K + ε- 如果线性关系不显著,可以考虑非线性模型,例如引入J和K的二次项、交叉项构建多项式回归模型,或对变量进行对数、指数等变换。
- 模型检验:
- 显著性检验: 对模型的回归系数(β₁、β₂)进行t检验,判断孕周数和BMI是否为显著影响因素。对整个模型进行F检验,判断模型的整体显著性。
- 拟合优度检验: 计算决定系数R²和调整后R²,评估模型对数据的解释能力。
- 残差分析: 检验残差是否满足正态性、独立性和方差齐性等回归模型的基本假设。
问题2:基于BMI分组的最佳NIPT时点
思路步骤:
- 孕妇BMI分组:
- 方法一(经验分组): 直接采用题目中给出的示例区间
[20,28), [28,32), [32,36), [36,40), 40+进行分组。 - 方法二(数据驱动分组): 使用聚类算法(如K-均值聚类)对BMI数据进行聚类,通过轮廓系数或肘部法则确定最佳分组数,从而得到更具数据特性的分组区间。
- 定义“潜在风险”与“最佳时点”:
- 风险量化: 根据题意,将不同孕周发现异常的风险进行量化。例如,定义一个风险函数
Risk(J): J ≤ 12(早期),Risk = 1(低)13 ≤ J ≤ 27(中期),Risk = 2(高)J ≥ 28(晚期),Risk = 3(极高)- 目标函数: “最佳时点”是在保证检测准确性(Y染色体浓度V ≥ 4%)的前提下,使得风险函数
Risk(J)最小化的孕周J。我们可以构建一个目标函数,例如,对于每个BMI分组,寻找一个孕周J,使得该分组内绝大多数孕妇(如95%)的Y染色体浓度预测值能够达到4%,同时Risk(J)最小。
- 求解最佳时点:
- 对于每个BMI分组,利用问题1建立的模型
V = f(J, K)。 - 对于一个给定的孕周
J,可以计算出该组内所有孕妇的Y染色体浓度预测值,并统计达标(V ≥ 4%)的比例P(J)。 - 建立优化模型:
min Risk(J),约束条件为P(J) ≥ 达标率阈值(例如95%)。 - 通过遍历可能的孕周
J(例如从第10周到第25周),找到满足约束条件的、风险最小的J作为该组的最佳NIPT时点。
- 检测误差分析:
- 引入误差项:假设Y染色体浓度的检测存在一个随机误差
ε_test(例如,服从均值为0的正态分布)。 - 进行敏感性分析或蒙特卡洛模拟:在预测的Y染色体浓度上叠加随机误差,重复进行数千次数万次模拟实验,观察在不同误差水平下,原先计算出的“最佳时点”的达标率
P(J)会如何波动,从而评估结果的稳健性。
问题3:考虑多因素的优化模型
思路步骤:
- 扩展回归模型:
- 在问题1模型的基础上,引入更多影响因素,如孕妇年龄(C)、身高(D)、体重(E)等。注意身高和体重与BMI存在多重共线性,通常选择BMI或身高体重其一即可。模型可扩展为:
V = f(J, BMI, Age, ...)。 - 使用多元回归或机器学习模型(如随机森林、梯度提升树)来捕捉更复杂的非线性关系和特征间的交互作用。
- 构建综合优化模型:
- 这是一个多目标优化问题。目标是:1)最小化潜在风险
Risk(J);2)最大化Y染色体浓度达标比例P(J)。 - 方法一(约束规划): 将其中一个目标作为约束。即
min Risk(J),约束条件P(J) ≥ 阈值(如95%)。 - 方法二(加权求和): 将多目标转化为单目标,构建一个效用函数,例如
Minimize [w * Risk(J) - (1-w) * P(J)],其中w是权重系数,反映了对风险和达标率的重视程度。
- 分组与求解:
- 根据题目要求,仍然基于BMI进行分组。
- 对每个BMI分组,利用新的、更复杂的模型来预测
P(J)。 - 求解上述优化模型,为每个分组找到最佳的NIPT时点。
- 误差分析:
- 方法与问题2类似,但由于模型更复杂,误差可能来自更多变量。可以重点分析模型预测误差和关键变量(如V)的测量误差对最终决策(最佳时点J)的影响。
问题4:女胎异常的判定方法
思路步骤:
- 问题定性:
- 这是一个典型的监督学习分类问题。目标是根据一系列生理指标,将女胎样本分为“异常”(AB列非空)和“正常”(AB列为空)两类。
- 特征工程:
- 核心特征: 21、18、13号染色体的Z值(S, R, Q)。根据医学常识,Z值是判断染色体非整倍体的关键指标,通常Z值大于3被认为是高风险。
- 辅助特征: 题目要求综合考虑的其他因素,如X染色体Z值(T)、GC含量(X, Y, Z)、总读段数(L)、比对率(M)、BMI(K)等。这些特征可能反映了测序质量或母体背景,可以帮助模型处理边界情况或提高准确性。
- 模型构建与选择:
- 方法一(规则阈值模型):
- 建立一个基于Z值的简单逻辑规则:
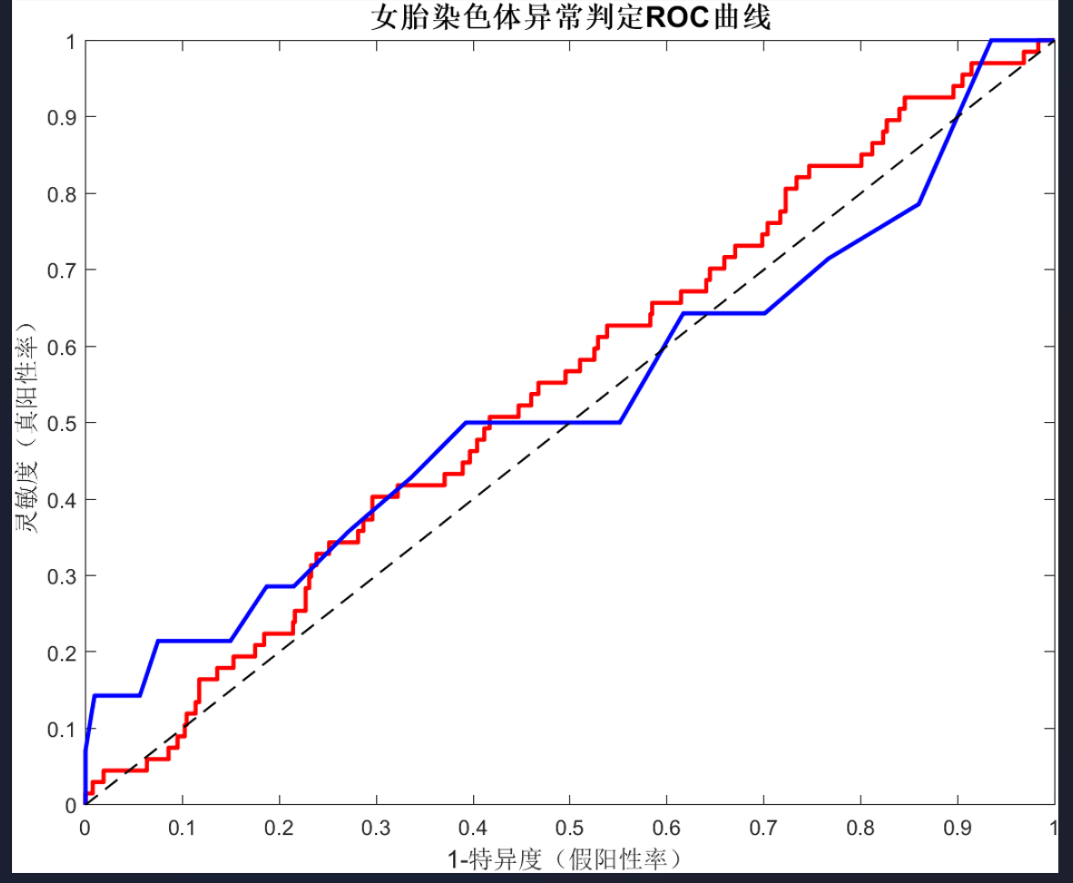
IF (Z_21 > T₁ OR Z_18 > T₂ OR Z_13 > T₃) THEN "异常" ELSE "正常"。 - 可以使用ROC曲线分析来为 T₁, T₂, T₃ 寻找最佳阈值,以平衡真阳性率(召回率)和假阳性率。
- 方法二(机器学习分类模型):
- 将所有选定特征作为输入,将是否异常(0或1)作为输出。
- 适用的算法包括:逻辑回归(提供概率解释)、支持向量机(SVM)(处理高维数据)、决策树/随机森林(可解释性好,能处理特征交互)、XGBoost/LightGBM(性能强大)。
- 模型评估与验证:
- 将数据集划分为训练集和测试集。
- 使用混淆矩阵来评估模型性能,计算准确率、精确率、召回率(灵敏度)和F1分数。在医疗诊断场景中,召回率尤为重要,因为它关系到能否成功检出所有异常样本(即减少漏诊)。
- 绘制ROC曲线并计算AUC值,综合评估模型的整体分类能力。