此代码已经继续加入 二次分解——创新模型预测 全家桶:二次分解——创新模型预测全家桶 (mbd.pub)
全家桶包括以下内容:
1.VMD + CEEMDAN 二次分解,BiLSTM-Attention预测模型 (mbd.pub)
2.VMD + CEEMDAN 二次分解,CNN-LSTM预测模型 (mbd.pub)
3.VMD+CEEMDAN二次分解,Transformer-BiGRU预测模型 (mbd.pub)
4.VMD+CEEMDAN二次分解,CNN-Transformer预测模型 (mbd.pub)
创新点:二次分解 + 时空特征提取
包括 风速数据, 以及已经生成制作好的风速数据集、标签集,对应代码均可以运行
VMD + CEEMDAN二次分解,CNN-LSTM预测模型, 有着更小的MSE, MAE,效果特别明显,提升显著!!
包括数据预处理的和二次分解代码,和完整 CNN-LSTM 模型预测代码、可视化代码
环境:python 3.9 Pytorch 1.8 以上
任何环境安装或者代码问题,请联系作者沟通交流,对于购买者,作者免费解决调试问题,关注微信公众号[建模先锋],联系作者;

创新点:二次分解 + 时空特征提取
前言
本文基于前期介绍的风速数据( 文末附数据集 ),介绍一种基于VMD+CEEMDAN二次分解的CNN-LSTM预测模型,以提高时间序列数据的预测性能。
1 二次分解与数据集制作
1.1 导入数据
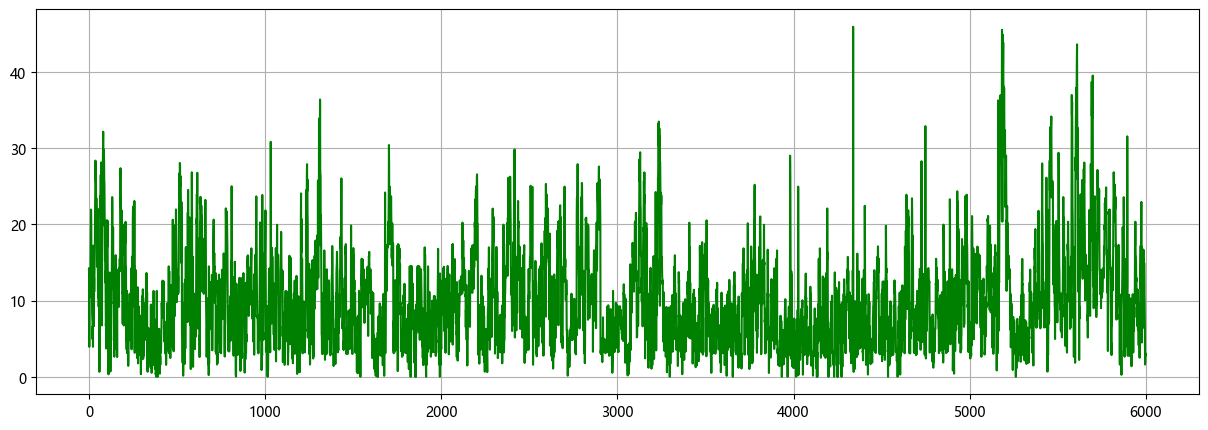
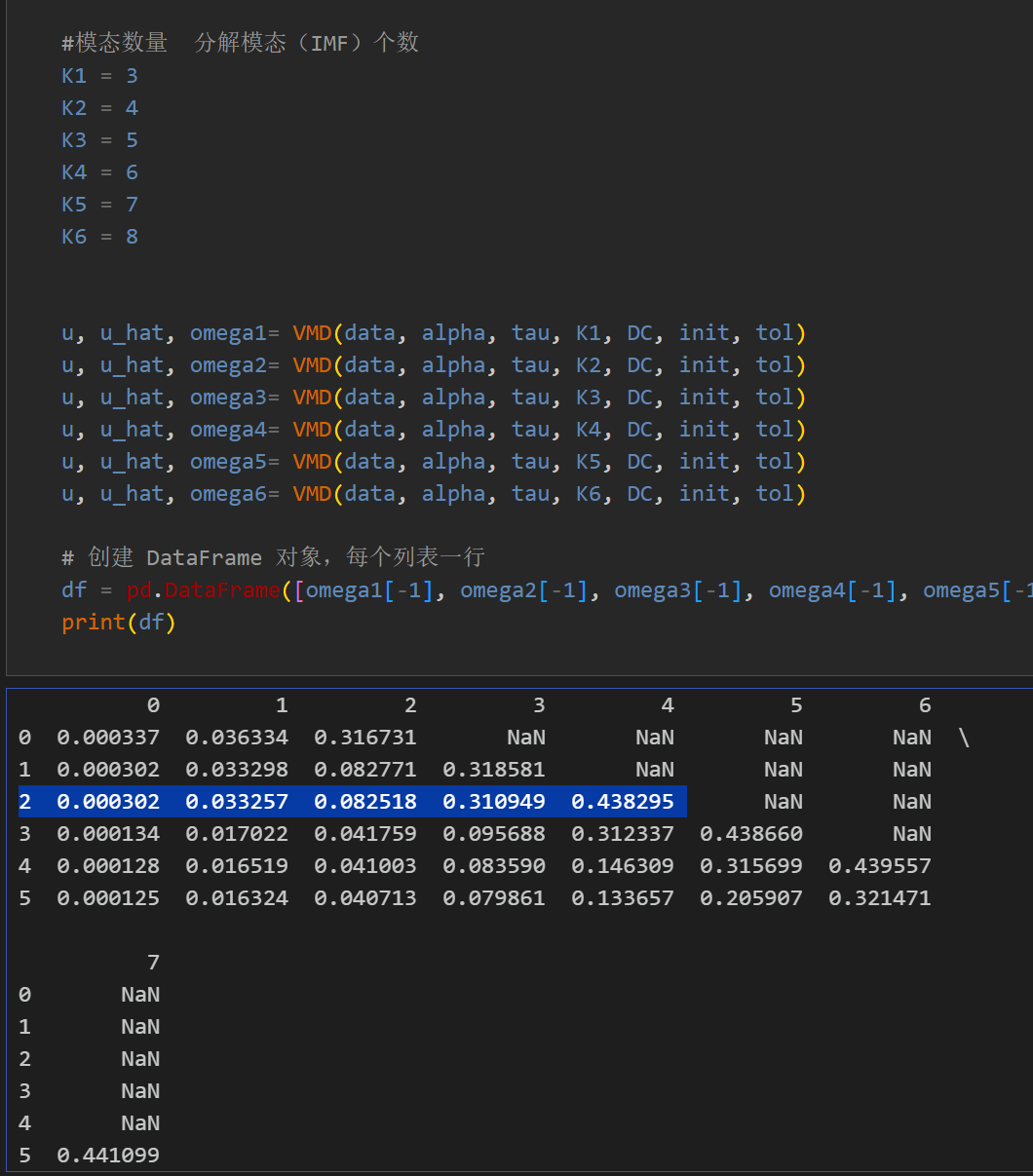
1.2 VMD分解
第一步,根据不同K值条件下, 观察中心频率,选定K值; 从K=4开始出现中心频率相近的模态,出现过分解,故模态数 K 选为4。
第二步,分解可视化
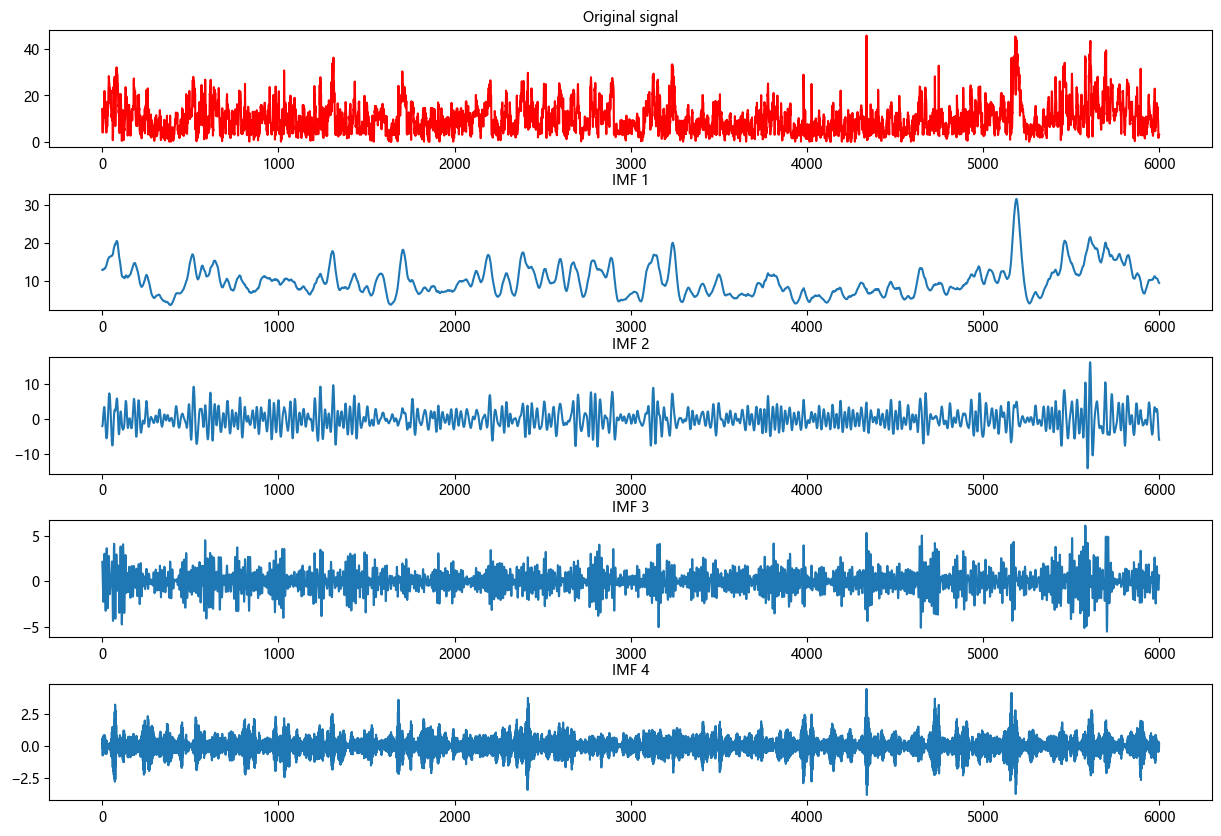
1.3 样本熵
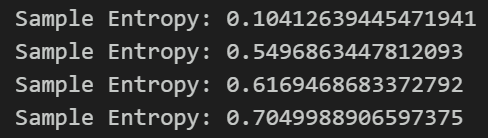
样本熵是一种用于衡量序列复杂度的方法,可以通过计算序列中的不确定性来评估其复杂性。 样本熵越高,表示序列的复杂度越大。
通过对VMD分解出四个分量的样本熵计算,残差项IMF4有着更丰富的不可控信息,为进一步提取IMF4中的有效信息,对VMD的残差项IMF4,进行CEEMDAN分解
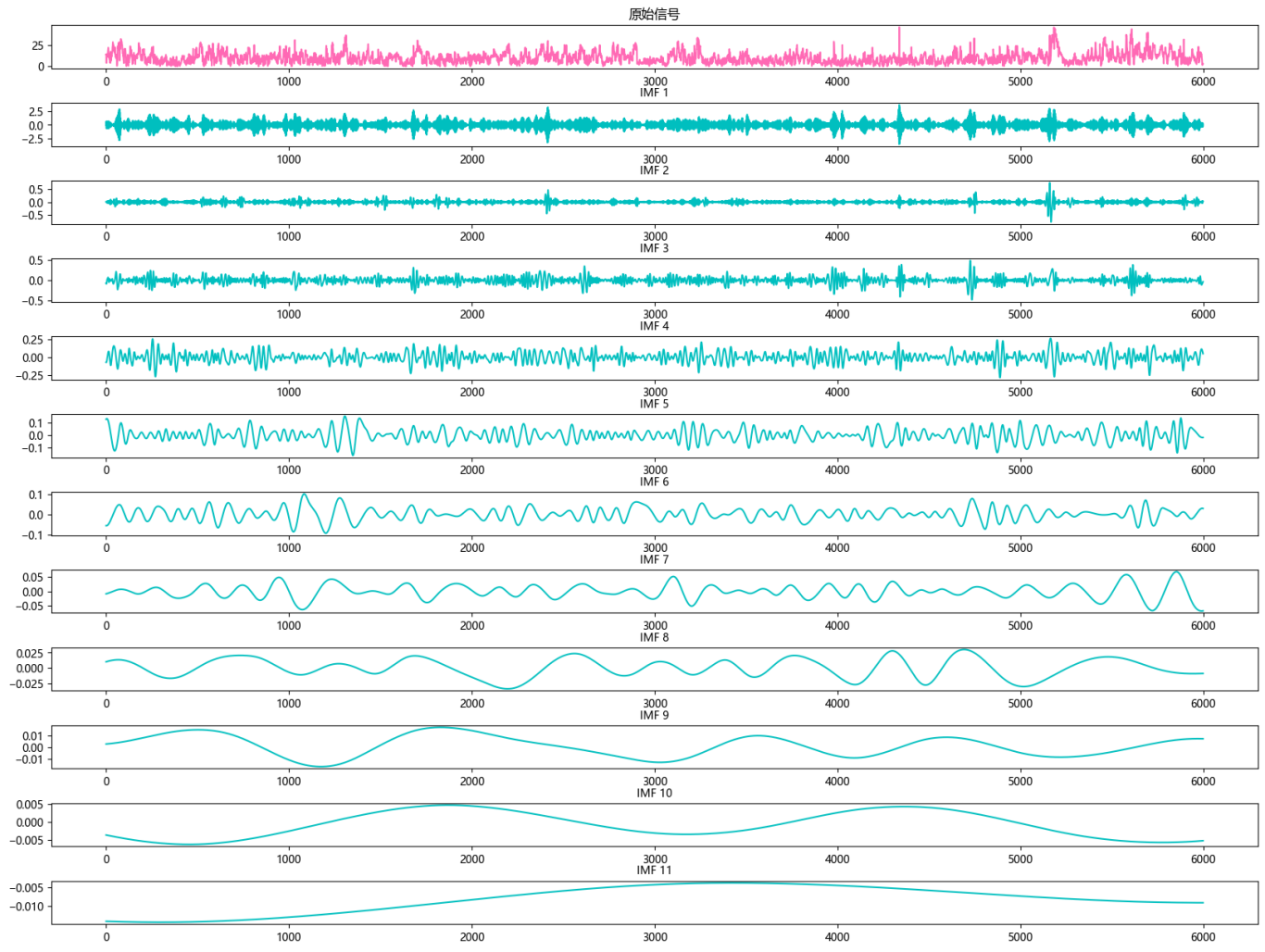
1.4 CEEMDAN分解
对 VMD分解出的 最后一个残差分量进行再分解
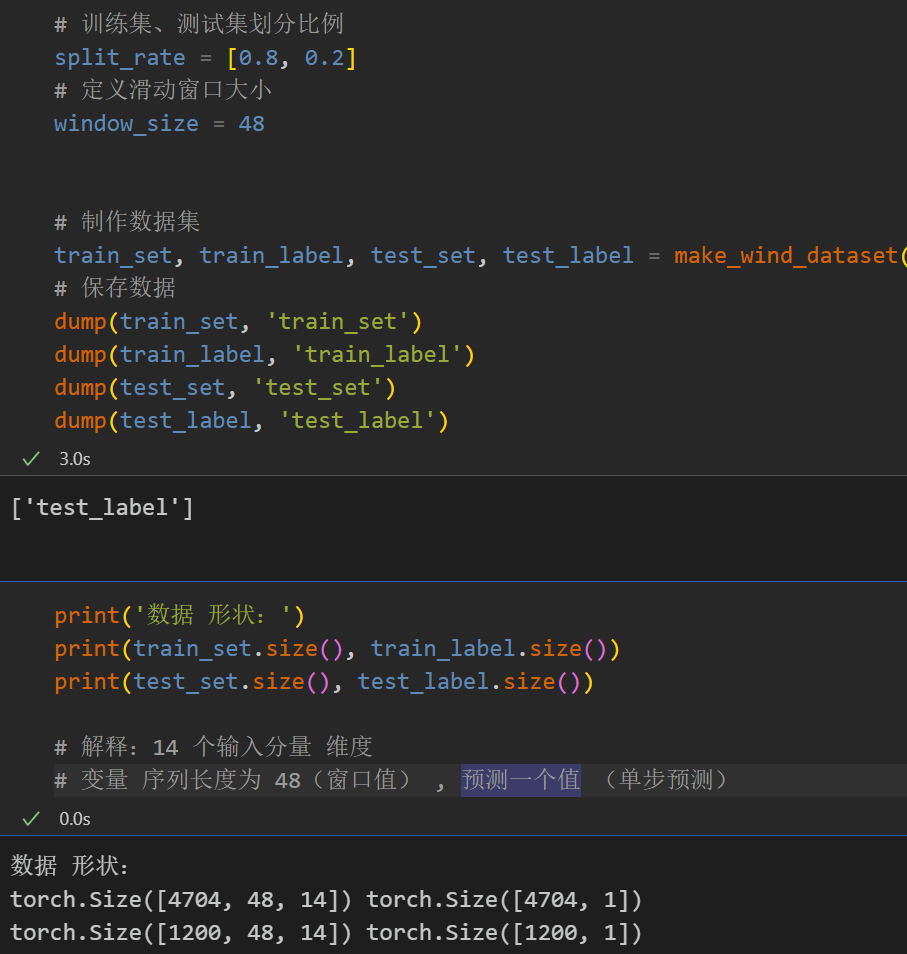
1.5 数据集制作
先合并VMD和CEEMDAN分解的分量,按照8:2划分训练集和测试集
在处理LSTF问题时,选择合适的窗口大小(window size)是非常关键的。选择合适的窗口大小可以帮助模型更好地捕捉时间序列中的模式和特征,为了提取序列中更长的依赖建模,本文把窗口大小提升到48,运用CNN-BiLSTM模型来充分提取分量序列中的时空特征信息。
2 基于Pytorch的 CNN-LSTM 预测模型
2.1 定义CNN-LSTM预测模型
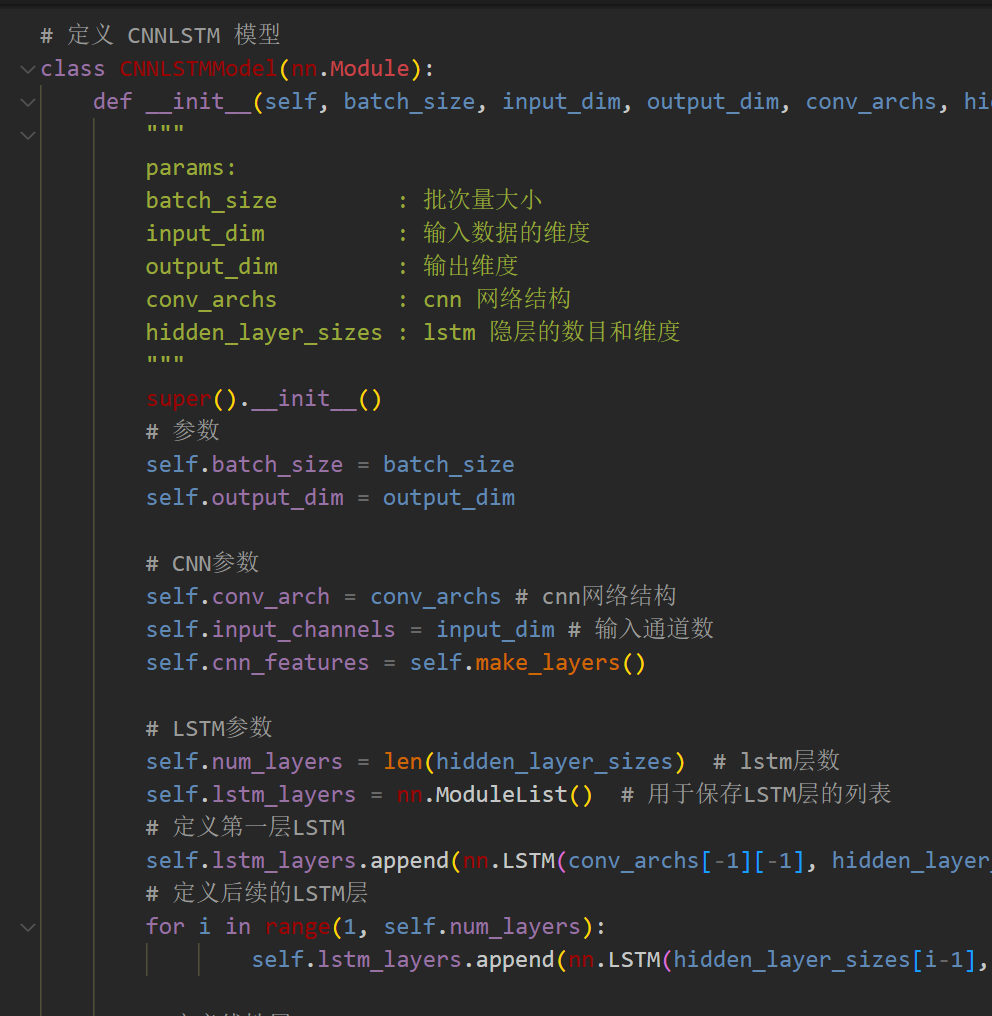
注意:输入风速数据形状为 [64, 48, 14], batch_size=64,48代表序列长度(滑动窗口取值), 维度14维代表合并分量的维度。
2.2 设置参数,训练模型
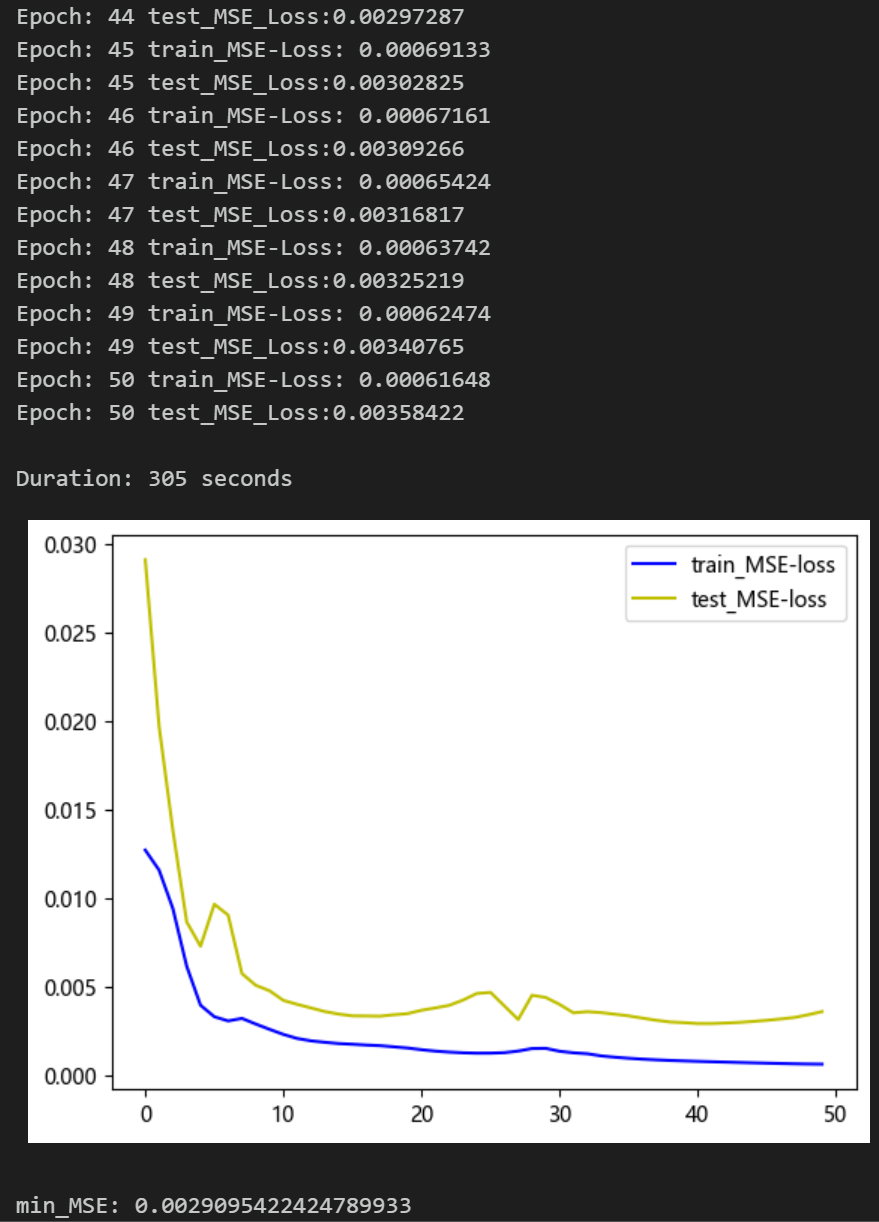
50个epoch,MSE 为0.00290,VMD+CEEMDAN二次分解的CNN-LSTM预测效果良好,二次分解后,能够提取序列中更多的信息,CNN-LSTM模型能够提取出分量特征的时空信息,预测效果提升明显,性能优越,适当调整模型参数,还可以进一步提高模型预测表现。
注意调整参数:
- 可以修改CNN层数和每层维度数;
- 调整LSTM隐藏层、维度数,增加更多的 epoch (注意防止过拟合)
- 可以改变滑动窗口长度(设置合适的窗口长度)
3 模型评估与可视化
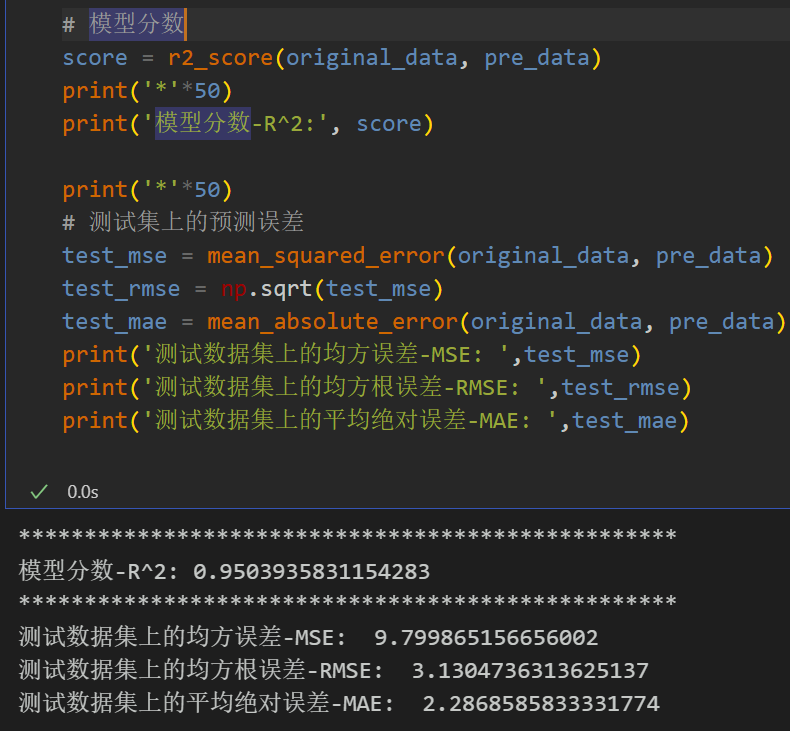
3.1 结果可视化
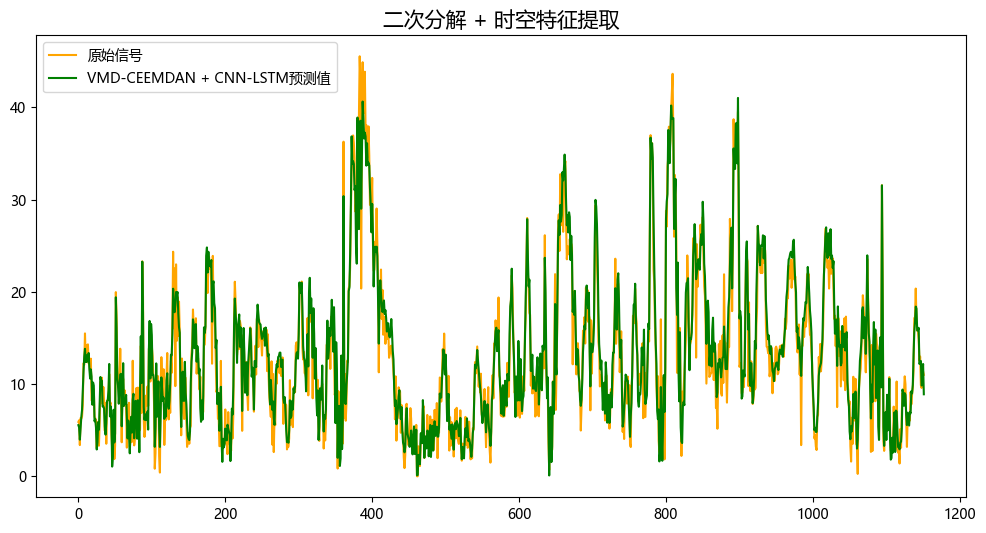
3.2 模型评估