声明:对于作者的原创代码,禁止转售倒卖,违者必究!
本期代码,利用强大的python库——mealpy,实现对VMD参数的优化。
mealpy库包含了170多个智能优化算法,其中有原始算法和改进算法。关于mealpy库的详细介绍,链接在这里:https://mealpy.readthedocs.io/en/latest/
五种适应度函数分别是:最小包络熵、样本熵、信息熵、排列熵、排列熵/互信息熵,关于这五种适应度函数的介绍之前已经介绍过非常多了,也可跳转以下链接查看:
①VMD为什么需要进行参数优化,最小包络熵/样本熵/排列熵/信息熵,适应度函数到底该选哪个
②运行速度终于变快了!优化VMD参数,五种适应度函数任意切换,最小包络熵、样本熵、信息熵、排列熵、排列熵/互信息熵
Python代码示例:
第一步:读取数据
import scipy.io as scio
L = 1500 # 采样点数
STA = 1 # 采样起始位置
data1 = scio.loadmat('105.mat')
data2 = data1['X105_DE_time'] #取出X105_DE_time
data = data2[STA-1:STA-1+L]
采用的数据来自于凯斯西储大学(CWRU)的X105_DE_time数据,该数据是一个(N*1)的数据,这也意味着,只要你的数据是1列的即可,替换起来十分简单!
第二步:定义适应度函数
from objectfun import EnvelopeEntropyCost,SampleEntropyCost,PermutationEntropyCost,infoEntropyCost,compositeEntropyCost
#objectfun 是作者自己写的一个五种适应度函数的定义,在主程序调用此定义,可以方便调用这五种适应度函数!
#五种适应度函数分别为:最小包络熵,最小样本上,最小排列熵,最小信息熵,复合指标:排列熵/互信息
def x_EnvelopeEntropyCost(x): #定义最小包络熵
ff = EnvelopeEntropyCost(x,data)
return ff
def x_SampleEntropyCost(x): #定义最小样本熵
ff = SampleEntropyCost(x,data)
return ff
def x_PermutationEntropyCost(x): #定义最小排列熵
ff = PermutationEntropyCost(x,data)
return ff
def x_infoEntropyCost(x): #定义最小信息熵
ff = infoEntropyCost(x,data)
return ff
def x_compositeEntropyCost(x): #定义最小复合指标:排列熵/互信息
ff = compositeEntropyCost(x,data)
return ff
objectfun 是作者自己写的一个五种适应度函数的定义,在主程序调用此定义,可以方便调用这五种适应度函数!五种适应度函数分别为:最小包络熵,最小样本上,最小排列熵,最小信息熵,复合指标:排列熵/互信息。
第三步:调用mealpy库,实现对VMD参数的优化
problem_dict = {
"fit_func": x_EnvelopeEntropyCost, #只需要修改这里,即可改变适应度函数。比如改成x_SampleEntropyCost、x_PermutationEntropyCost等
"lb": [100,3], #分别对应惩罚因子alpha和模态分量K的下限
"ub": [2500,10], #分别对应惩罚因子alpha和模态分量K的上限
"minmax": "min", #说明此程序为求最小值
}
''' 调用优化算法 '''
epoch = 5 # 最大迭代次数
pop_size = 10 # 种群数量
''' 第一种方式,需:from mealpy.swarm_based import EOA,GWO '''
EOA_model = EOA.OriginalEOA(epoch, pop_size)
BBO_model = BBO.OriginalBBO(epoch, pop_size)
注意看上述代码的注释,明确写好了如何方便的修改适应度函数!
问题:如何调用不同的智能算法呢?
只需要在程序最前面调用算法名字,然后在程序替换这个算法名字即可!
比如:
from mealpy import EOA,GWO,BBO,BMO,EOA,IWO,TPO
这里直接调用算法名字,然后在程序中替换为相应算法即可!
问题:怎么知道mealpy库有哪些算法可以被调用?
也很简单,在终端输入一句指令:
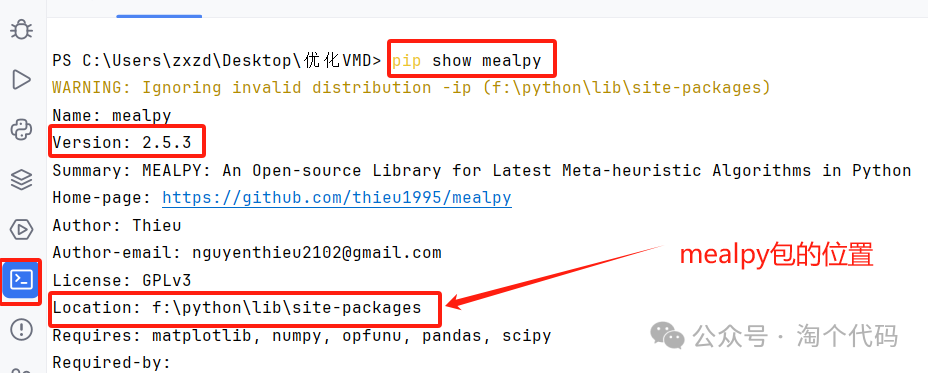
打开这个位置,找到meaply文件夹,点进去:
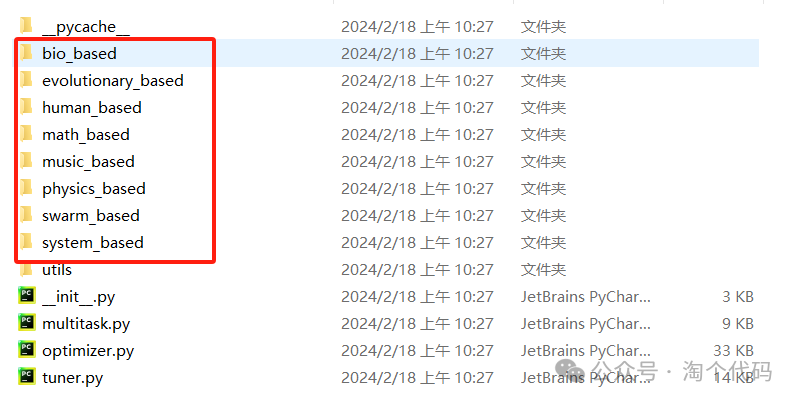
这里边都是不同的算法,任意点击一个进去,比如我点击第一个bio_based:
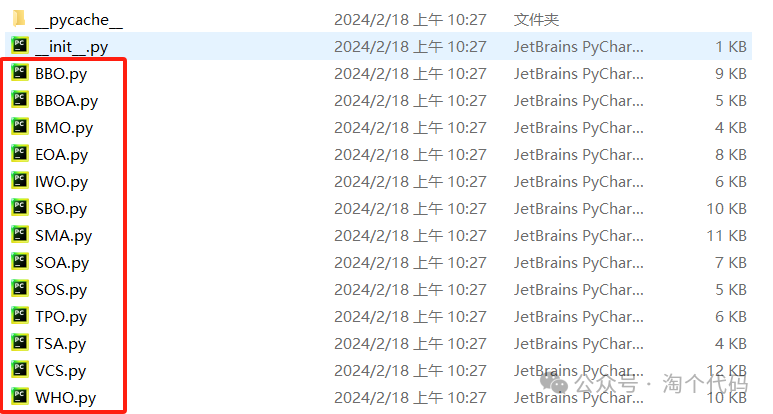
可以看到算法名字都在这里啦,然后就在程序中调用这些算法就OK!
最后看一下效果吧:
示例1
这是哈里斯鹰算法(HHO)和霜冰算法(RIME),适应度函数为最小包络熵的结果:
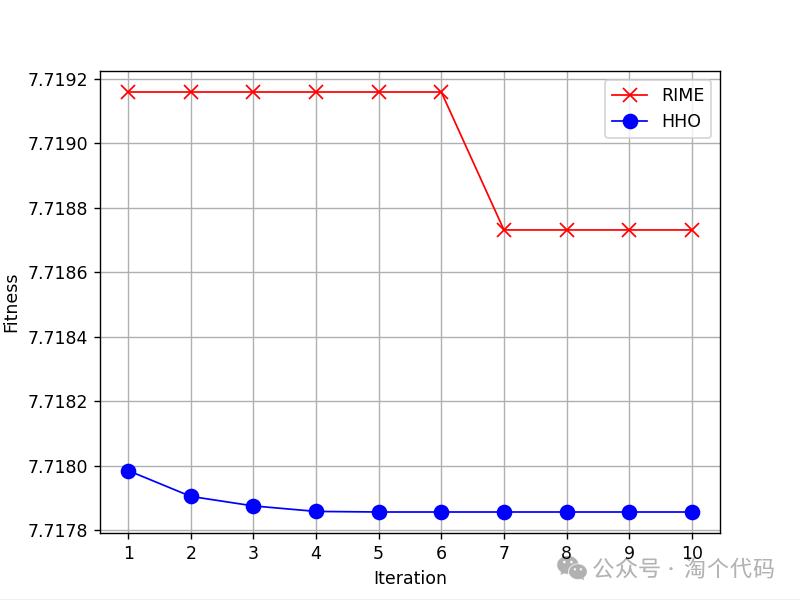
运行完后在命令行窗口会显示如下结果:
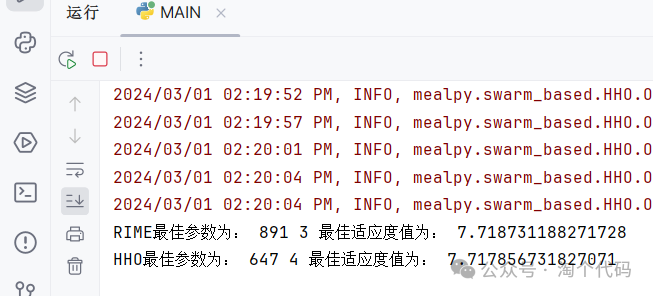
第一个参数为最佳的惩罚因子alpha,第二个为模态分量K。
示例2
不得不说,修改起来算法是真的很方便!
再来一个多元宇宙算法(MVO)和斑马算法(ZOA),适应度函数为最小排列熵的结果:
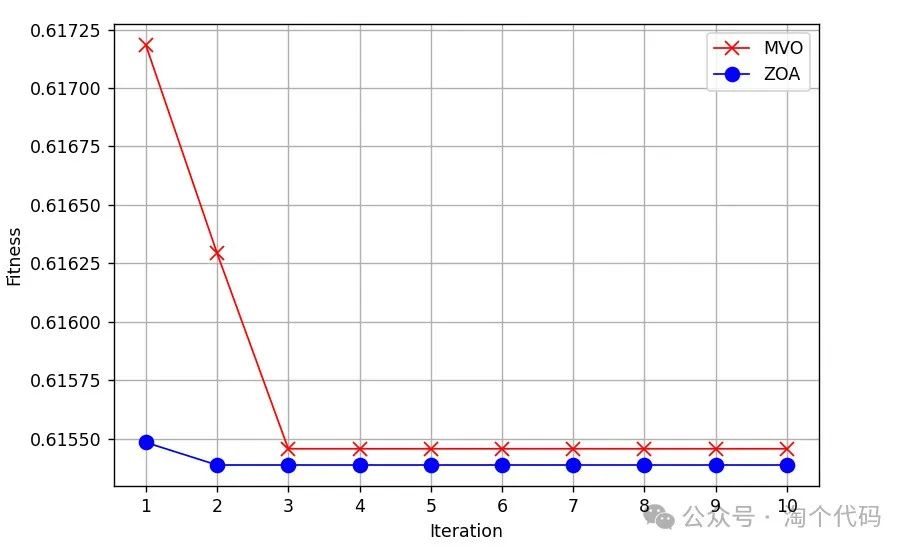
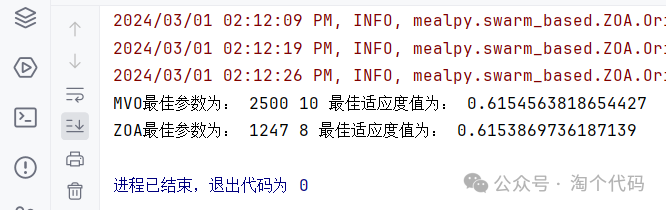
拓展功能!
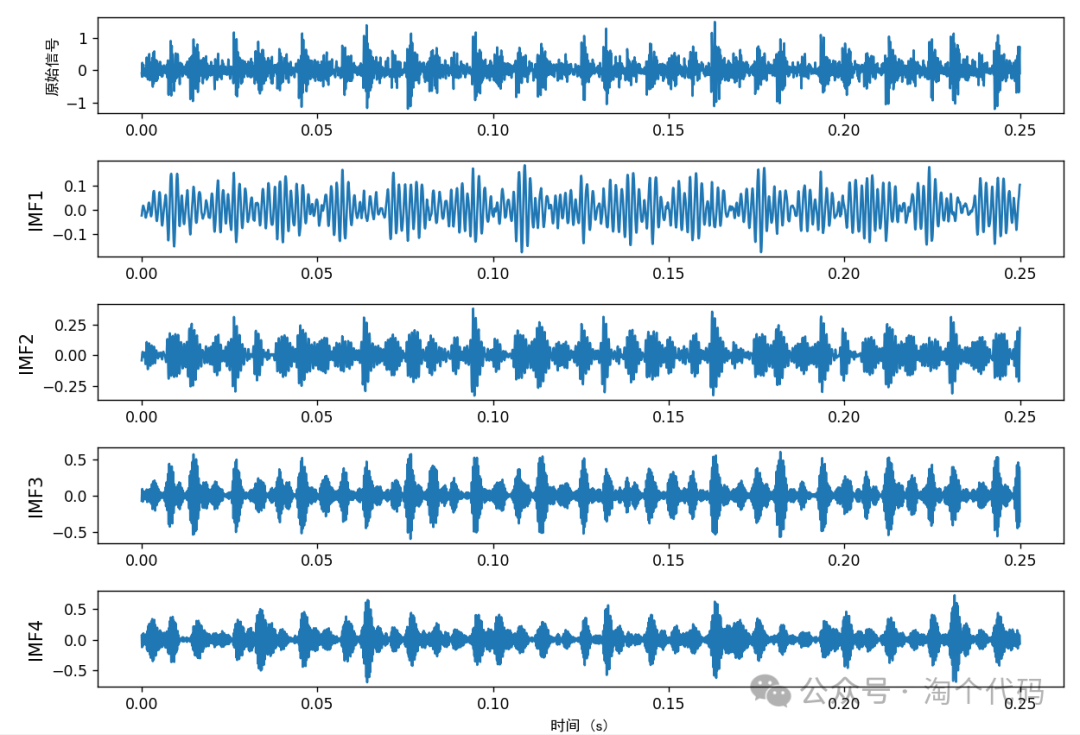
本期代码不仅有优化VMD参数的功能,还可以在优化完VMD参数后,将最佳参数回带至VMD中,从而绘制vmd分解图,包络线图,包络谱,频谱图,中心频率,峭度值,能量熵,样本熵,模糊熵,排列熵,近似熵,包络熵等所有功能!
比如,在示例1中,已经计算出最佳参数为:alpha = 647,K = 4。
此时直接将这两个参数回带,然后一键出图并统计各种指标。结果如下:
VMD分解图:
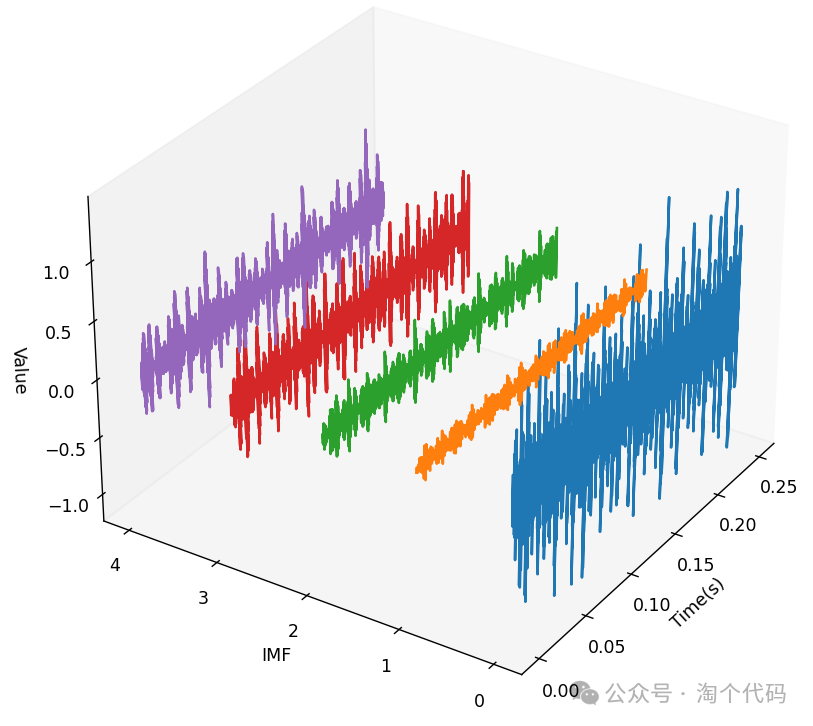
VMD分解三维图展示:
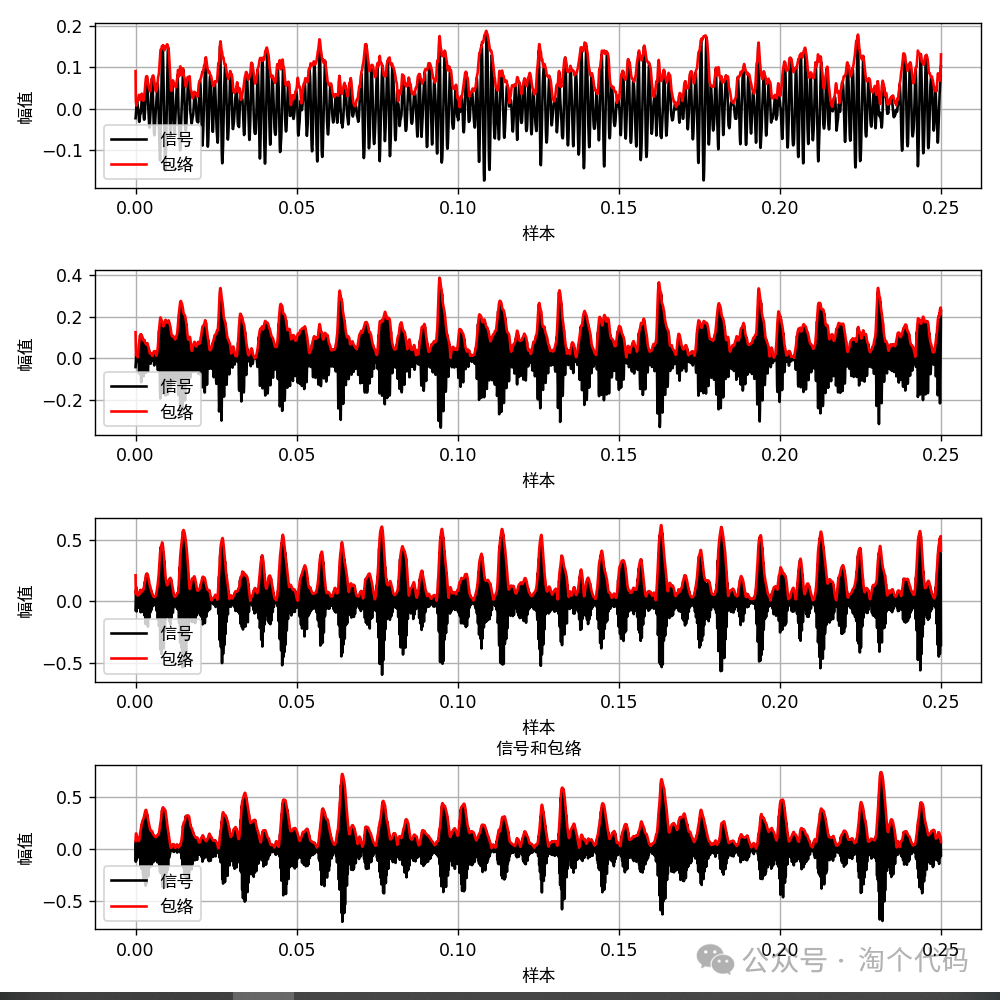
包络线图:
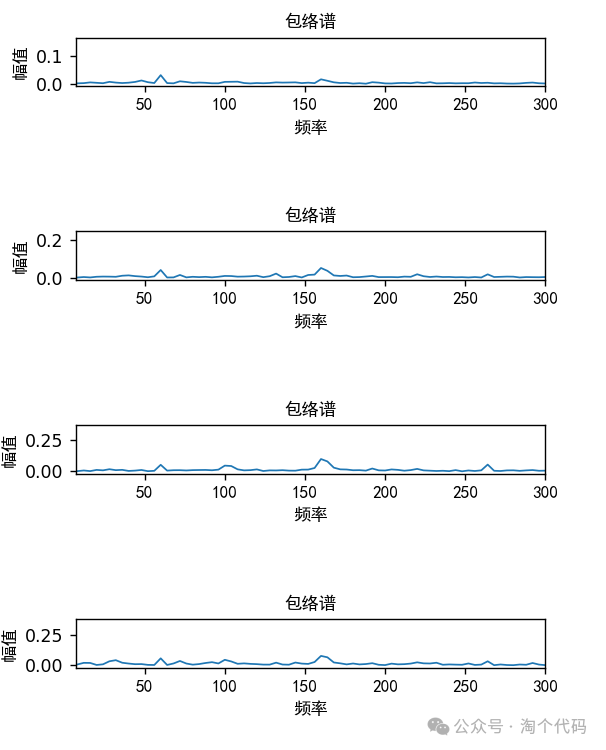
包络谱图:
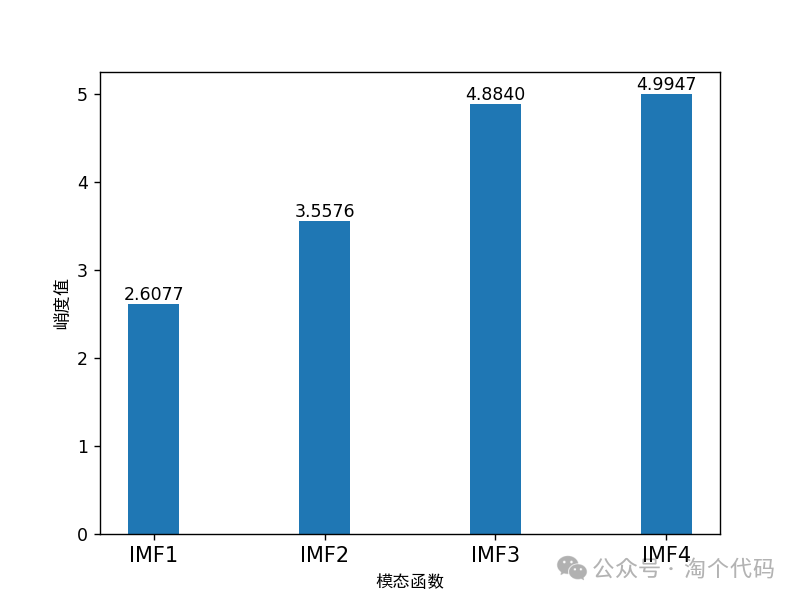
峭度值图:
频谱图:
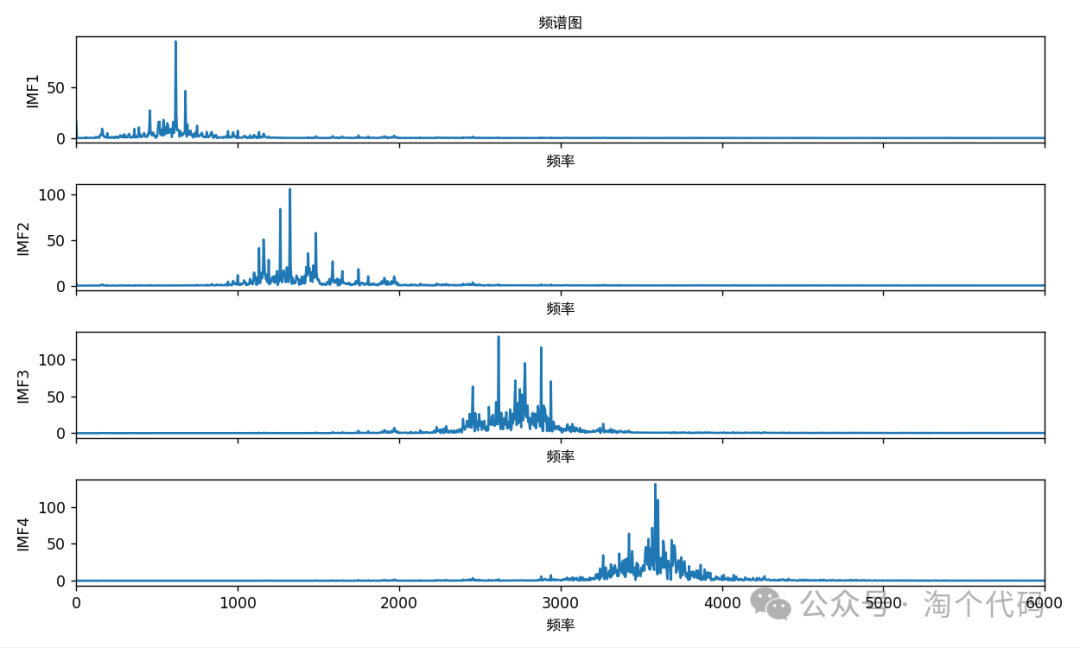
各种指标计算结果打印:

代码目录

所需包版本如下:
numpy~=1.26.3 scipy~=1.12.0 matplotlib~=3.8.2 mealpy~=2.5.3 vmdpy~=0.2 scikit-learn~=1.4.0 pandas~=2.2.0
本文代码获取链接:
https://mbd.pub/o/bread/ZZuam5hy
也可跳转二维码获取:
