背景
随着互联网经济的蓬勃发展,金融领域的海量营销数据已然成为一项特殊资产,其经济价值受到金融机构的高度关注,如何基于数据挖掘技术有效利用金融产品营销数据是目前金融领域关注的重要问题。科学分析金融产品营销数据不仅可以提高金融行业的服务水平和整体收益,也能降低管理风险,促进金融创新。
技术路线图
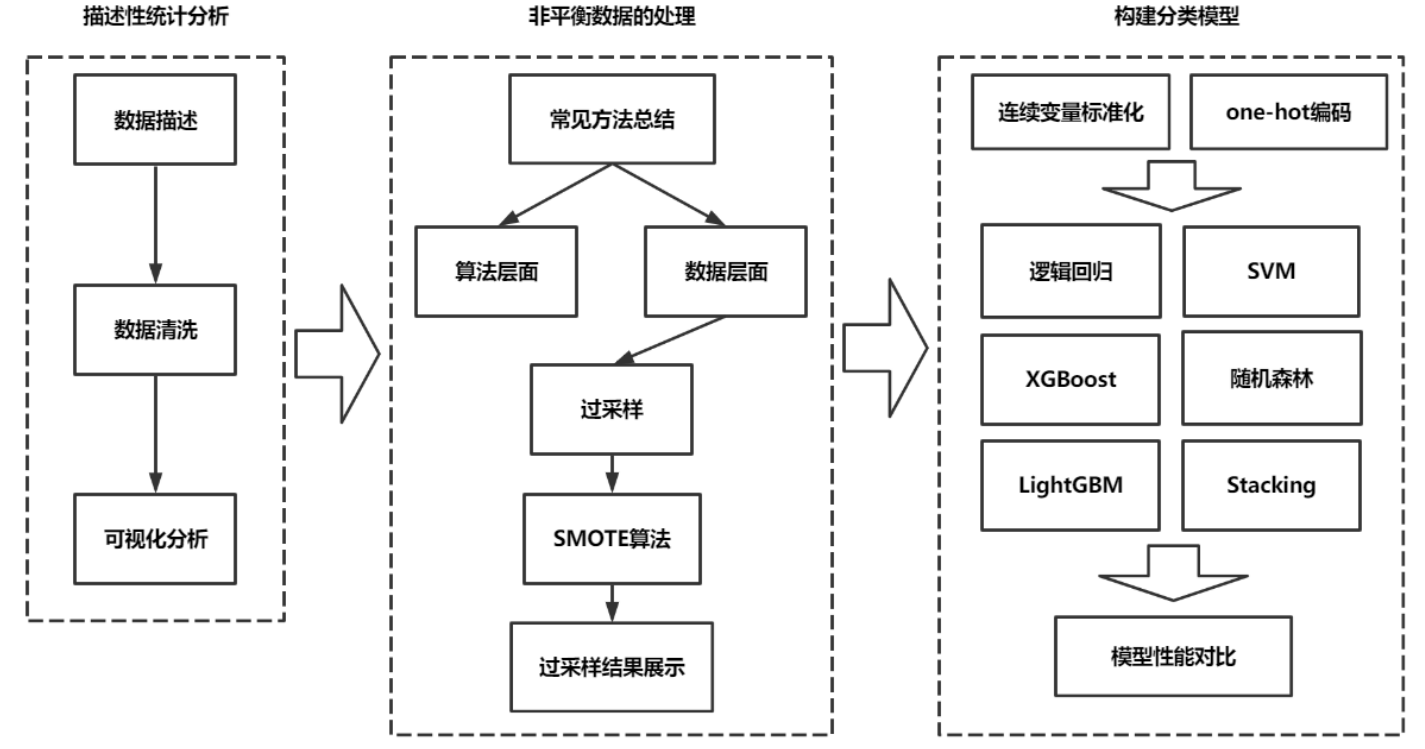
本文首先对数据集进行初步描述与数据清洗,包括缺失值、重复值以及异常值的处理,在此基础上对数据集进行可视化分析。针对数据集的非平衡性,基于 SMOTE 算法进行样本过采样以实现数据集的平衡。解决数据集的不平衡问题后, 将连续变量标准化,离散变量做 one-hot 编码处理以供后续建模。最后则是构建金融产品购买的分类预测模型,基于处理后的数据集分别构建逻辑回归、SVM、 随机森林、XGBoost、LightGBM、Stacking 融合分类模型并进行性能对比。
总结
本文主要研究了客户购买金融产品的影响因素,并构建了金融产品认购的分类模型。具体来讲,首先对原始数据做预处理并进行可视化分析,之后针对数据集的非平衡性使用基于 SMOTE 算法的过采样技术平衡正负样本,最后基于逻辑回归、支持向量机、随机森林、XGBoost 以及 LightGBM 分别构建了金融产品认购的分类模型以预测客户是否会购买该类金融产品,并对模型分类性能进行评价与对比。为了进一步提升分类器的性能,基于 Stacking 算法构建组合分类器,并使用 5 折交叉验证增强模型的稳健性。结果显示,客户信息、客户联系以及社会经济环境的相关特征都会在不同程度上影响客户购买金融产品的意愿,在分类模型构建上,LightGBM 的分类性能最佳,算法的执行效率最高,支持向量机的分类性能最差,基于 Stacking 算法的组合分类器的性能较单个分类器而言有了一定的提升。

付费内容
论文全文+数据+代码