开发文档:基于Python+Django的淘宝男士服装销售分析可视化系统
项目概述
该项目实现了一个基于 Django 框架的网页应用,主要用于抓取淘宝男士服装的销售数据,并进行可视化分析。用户可以查看商品的基本信息、价格、商店名称、评论数据等,并进行进一步的数据分析和图表展示。该系统结合了爬虫技术,自动化获取数据,存储到数据库中并提供数据可视化界面。
功能模块
- 爬虫模块(
spider.py)
- 从淘宝网站抓取商品信息、评论、销量、价格等数据。
- 支持抓取多个关键词的商品信息(如男士服装、裤子等)。
- 定期爬取数据,更新商品信息。
- 数据存储模块
- 使用 Django ORM 存储抓取到的商品信息和评论数据。
- 商品信息包括商品名称、价格、品牌、链接、店铺名等。
- 评论数据包括评论内容、评分、评论时间、用户名等。
- 数据分析模块
- 处理抓取到的数据,生成销售数据的统计和分析。
- 支持商品价格、销量、评分等的趋势分析。
- 使用 Django 的模板引擎和静态文件生成可视化图表。
- 用户界面
- 提供一个简单的Web界面,显示商品数据和分析结果。
- 支持通过关键词搜索商品并展示相应的数据。
- 展示商品信息,支持筛选和排序功能。
- 数据库设计
- 使用 MySQL/PostgreSQL 数据库存储抓取到的商品信息和评论数据。
- 商品信息表:包含商品的详细信息。
- 评论信息表:包含商品的评论内容。
项目架构
my_project/
│
├── my_project/ # Django 项目主目录
│ ├── __init__.py
│ ├── settings.py # 配置文件
│ ├── urls.py # URL 路由配置
│ └── wsgi.py # WSGI 启动文件
│
├── app/ # Django 应用
│ ├── migrations/ # 数据库迁移文件
│ ├── __init__.py
│ ├── admin.py # Django 管理后台配置
│ ├── apps.py # 应用配置
│ ├── models.py # 数据模型
│ ├── views.py # 视图处理文件
│ ├── spider.py # 爬虫脚本
│ ├── static/ # 静态文件目录
│ │ ├── css/
│ │ ├── js/
│ │ └── images/
│ ├── templates/ # HTML 模板文件
│ └── urls.py # 应用路由配置
│
├── manage.py # Django 项目管理工具
├── requirements.txt # 项目依赖
└── README.md # 项目说明文档
数据库设计
数据表 1:商品信息(XinXi)
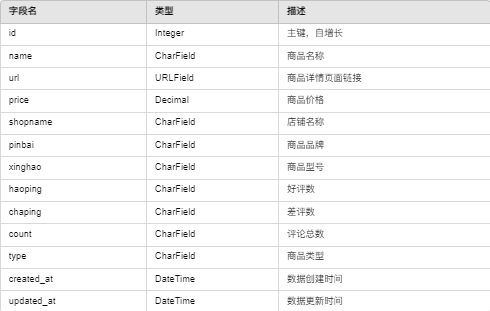
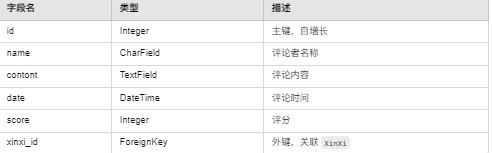
数据表 2:商品评论信息(Pinlun)
主要代码模块分析
1. 爬虫模块 (spider.py)
爬虫模块的主要任务是抓取淘宝的商品信息及其评论,并将数据存储到数据库中。
- 请求页面:爬虫通过发送 HTTP 请求获取淘宝商品页面和商品详情页面的 HTML 内容。
- 解析 HTML:使用 BeautifulSoup 解析 HTML 文档,提取商品信息,如价格、商品名称、品牌、评论数等。
- 获取评论数据:爬虫抓取每个商品的评论信息,包括好评、差评数和评论内容。
- 存储数据:爬取到的数据通过 Django 的 ORM 存储到数据库中。
2. 数据存储模块
- 商品数据存储:通过
models.XinXi.objects.create方法将商品信息存储到XinXi表中。 - 评论数据存储:通过
models.Pinlun.objects.create方法将评论信息存储到Pinlun表中。 - 数据更新:如果商品已经存在于数据库中,使用
models.XinXi.objects.filter().update()更新商品信息。
3. 数据分析模块
- 数据清洗:对爬取的数据进行清洗,处理评论数和评分等字段,转换为数字类型,去除单位(如“万”)。
- 统计分析:计算商品的好评率、评论数等基本统计信息。
- 趋势分析:基于时间数据,计算商品价格、销量、评论数等的变化趋势,并生成相应的图表(可以使用
matplotlib或plotly等库)。
4. 用户界面
- 展示商品信息:通过 Django 的模板引擎,将商品信息展示在网页上,用户可以查看商品的详细信息和评论。
- 可视化展示:通过前端页面展示数据分析结果,例如价格趋势图、评论分布图等。
- 搜索功能:用户可以根据关键词(如“男士外套”)进行商品搜索,系统会显示相关商品的详细信息。
5. 定时任务(可选)
使用 schedule 库或 Celery 定时任务框架,定期爬取商品信息并更新数据库中的数据。
数据库操作示例
商品数据存储示例:
if not models.XinXi.objects.filter(name=dicts1['name']).filter(url=dicts1['url']):
data1 = models.XinXi.objects.create(
name=dicts1['name'],
url=dicts1['url'],
price=dicts1['price'],
shopname=dicts1['shopname'],
pinpai=dicts1['pinbai'],
xinghao=dicts1['xinghao'],
haoping=dicts1['haoping'],
chaping=dicts1['chaping'],
count=dicts1['count'],
type=key
)
# 保存评论
pingluns = json_info['comments']
for pinlun in pingluns:
name = pinlun['nickname']
contnt = pinlun['content']
date = pinlun['creationTime']
score = pinlun['score']
models.Pinlun.objects.create(
name=name,
contont=contnt,
date=date,
score=score,
xinxi=data1
)
评论数据存储示例:
for pinlun in pingluns:
name = pinlun['nickname']
contnt = pinlun['content']
date = pinlun['creationTime']
score = pinlun['score']
models.Pinlun.objects.create(
name=name,
contont=contnt,
date=date,
score=score,
xinxi=data1
)
依赖库
requests:发送 HTTP 请求抓取网页。BeautifulSoup:解析 HTML 页面。json:解析 JSON 格式的评论数据。Django:后台框架,用于存储数据并渲染网页。schedule:定时任务框架,用于定期执行爬虫任务。
运行与部署
- 安装依赖:
pip install -r requirements.txt
- 配置数据库:在
settings.py中配置数据库连接信息。 - 运行 Django 开发服务器:
python manage.py runserver
- 执行爬虫脚本进行数据抓取:
python spider.py
总结
该系统结合了爬虫技术与 Django 后端开发,实现了对淘宝男士服装商品的自动化抓取、数据存储、分析和可视化功能。用户可以方便地查看商品数据,分析销售趋势和评论分布。
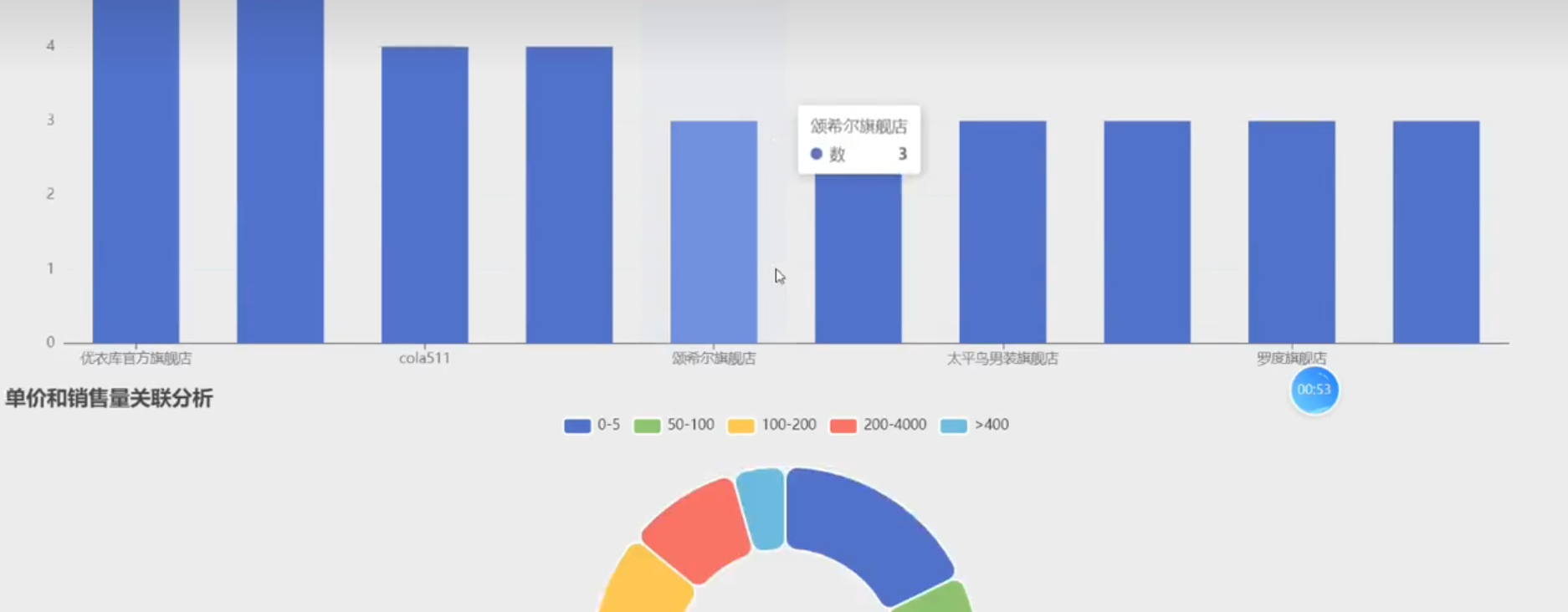
具体项目演示效果:
【S2023064基于python+Django爬虫的淘宝男装销售数据可视化系统】 https://www.bilibili.com/video/BV11s4y1o7Z5/?share_source=copy_web&vd_source=3d18b0a7b9486f50fe7f4dea4c24e2a4
项目配套代码百度云链接已放在付费区,有需要自行下载即可