声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
今天给大家带来一期原创未发表的新代码,非常适合作为创新点,也能让审稿人眼前一亮。简单来说,传统的单一算法优化已经无法满足创新的需求,且单一算法容易陷入局部最优等问题。
那么,如何进行创新呢?
我们提出一种双层优化方法,这个模型也是我们独家提出,目前知网和WOS上都还没人用过,你先用,你就是创新。
以BP神经网络为例,BP神经网络的性能受到隐藏层节点数、学习率、初始权重与阈值等参数的影响,手动调参较为繁琐且不可靠。传统的单算法优化只能优化BP神经网络的初始权重与阈值,存在优化范围局限、优化精度不高等问题。而我们提出的方法,首先利用性能较优的贝叶斯优化方法优化BP神经网络的隐藏层节点数和学习率,再利用改进的优化算法对它的初始权重和阈值进行优化,从而利用双层优化进一步提高预测精度。
当然,与以往一样,小伙伴们也可以自行替换自己想要的优化算法,非常方便。
您只需做的工作:替换自己的数据,运行main文件即可!非常适合新手小白!
01
数据输入方法
本期采用的数据是经典的回归预测数据集,是为了方便大家替换自己的数据集,各个变量采用特征1、特征2…表示,无实际含义,最后一列即为输出。
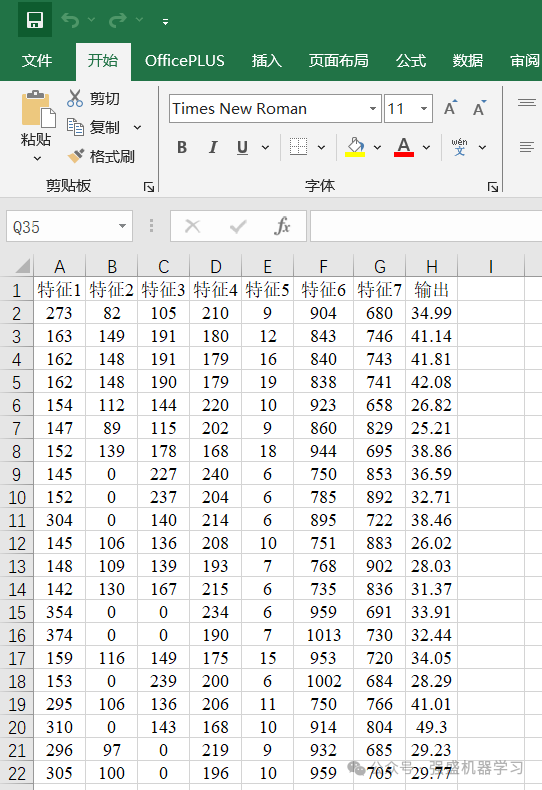
更换自己的数据时,只需最后一列放想要预测的列,其余列放特征即可(特特征数量不限),无需更改代码,非常方便!
02
原理简介
第一层优化:贝叶斯优化隐藏层节点数与学习率
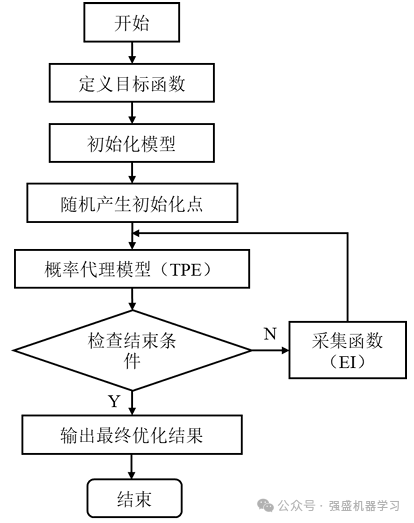
合理的超参数将会有效提高模型的性能。 在确定超参数过程中,需要对其取值进行不断调整,为了提高预测模型的预测精度,我们首先选用贝叶斯优化方法对超参数进行优化,优化过程的具体步骤如下:
(1)定义目标函数f(x)以及x的定义域。
(2)选取有限的x,求解对应的f(x) ,该值定义为观测值。
(3)根据观测值,使用概率代理模型(Probability Surrogate model)对函数进行估计,得出估计f*上的目标值。
(4)根据采集函数(Acquisition Function)规则,确定下一个需要计算的观测点。
(5)持续循环(2)至(4)步骤,检查结束条件,直到最大观测次数,输出最优结果。
流程图如下:
第二层优化:改进麻雀优化算法优化初始权重与阈值
传统的BP神经网络由于超参数、初始权值和阈值常常根据人为经验确定, 无法保证预测模型的性能要求。因此,在第二层采用改进的麻雀算法优化初始权重与阈值。本期的改进麻雀算法,采用一种自适应螺旋飞行麻雀算法!共四个改进点!
改进点1:tent混沌映射
麻雀搜索算法的种群位置生成具有随机性大的缺点,会导致初始种群质量差,从而减缓收敛速度。引入tent映射策略使种群初始化更加有序,增强算法的可控性,公式如下:
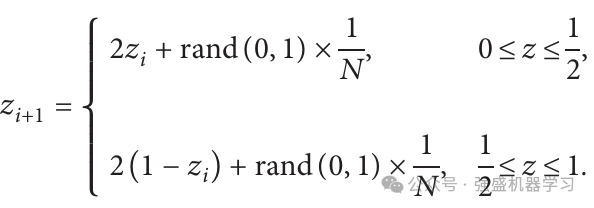
改进点2:自适应权重
引入自适应权重能够提高发现者个体位置的质量,使其他个体能够更快地收敛到最优位置,并加快收敛速度,自适应权重的公式如下:
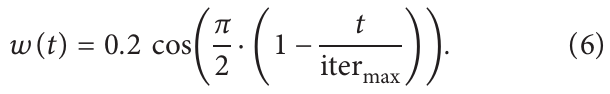
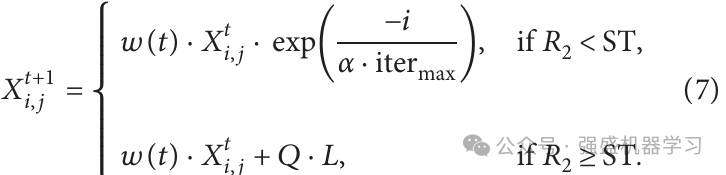
改进点3:莱维飞行机制
莱维飞行服从莱维分布,通过随机生成长距离和短距离机制来覆盖搜索空间,引入莱维飞行机制,提高所提出算法的性能,则位置更新公式如下:
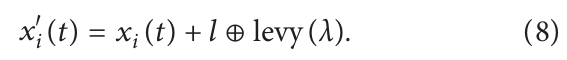
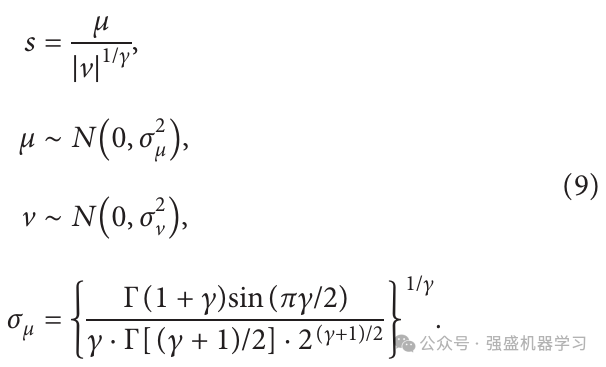
改进点4:可变螺旋搜索机制
引入可变螺旋位置更新策略,使追随者位置更新变得更加灵活,开发了各种搜索路径进行位置更新,并平衡了算法的全局搜索和局部搜索。则 可变螺旋位置更新策略的公式如下:
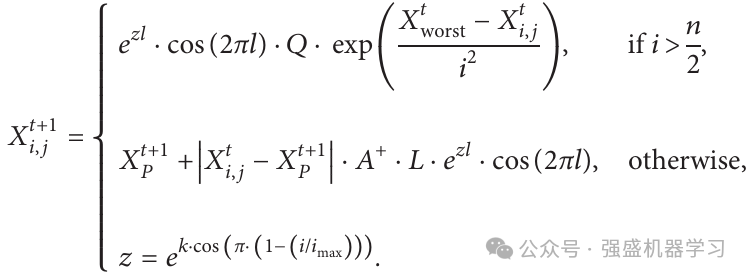
式中, z参数随操作次数而变化,螺旋线的大小和振幅根据cos函数的财产进行动态调整。k表示变化系数,k=5 ;l表示一个均匀分布随机数,l在[-1,1]的范围内 。
改进点文献如下:
[1]Ouyang C, Qiu Y, Zhu D. Adaptive spiral flying sparrow search algorithm[J]. Scientific Programming, 2021: 1-16.
03
流程图
这边给小伙伴们展示下双层优化的流程图,非常清晰!
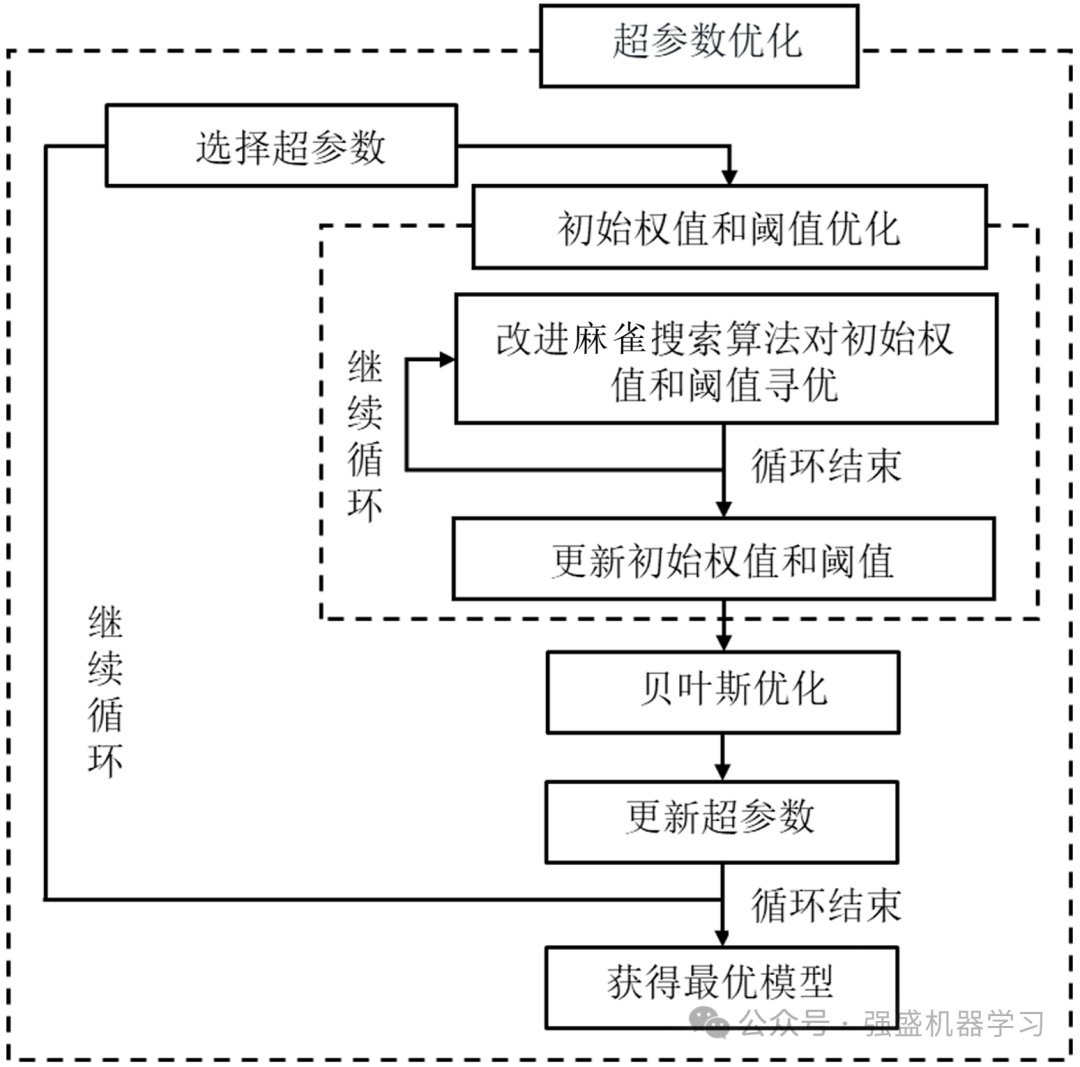
其中,较大的框架是通过贝叶斯优化方法确定BP神经网络的超参数。由于学习率和隐藏层的节点数量决定着BP神经网络模型训练的性能,选择这两个超参数进行优化可以提高预测模型的学习能力。
较小的框架是根据改进麻雀算法优化BP神经网络的初始权值和阈值。初始权重和阈值与BP神经网络的训练速度和收敛效果密切相关。传统BP神经网络的初始权值和阈值是随机设定的,在网络训练过程中,随着预测误差的减小进行不断调整。针对该问题,利用改进麻雀算法对初始权值和阈值进行优化。
04
结果展示
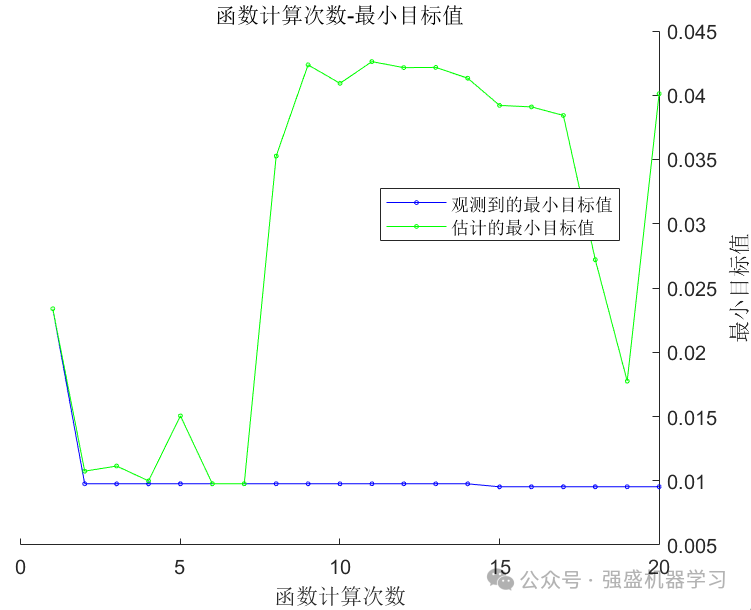
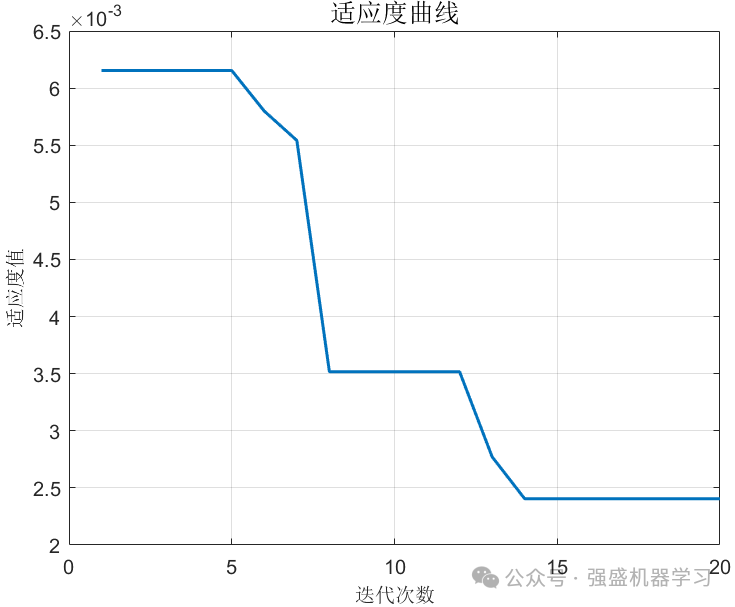
根据经验,将误差作为目标函数,隐藏层节点数的寻优范围为[5,20],学习率的寻优范围为[1e-5,1e-2],贝叶斯算法迭代20次,麻雀算法种群数为10,最大迭代次数为20,得到的结果如下所示:
贝叶斯优化图:
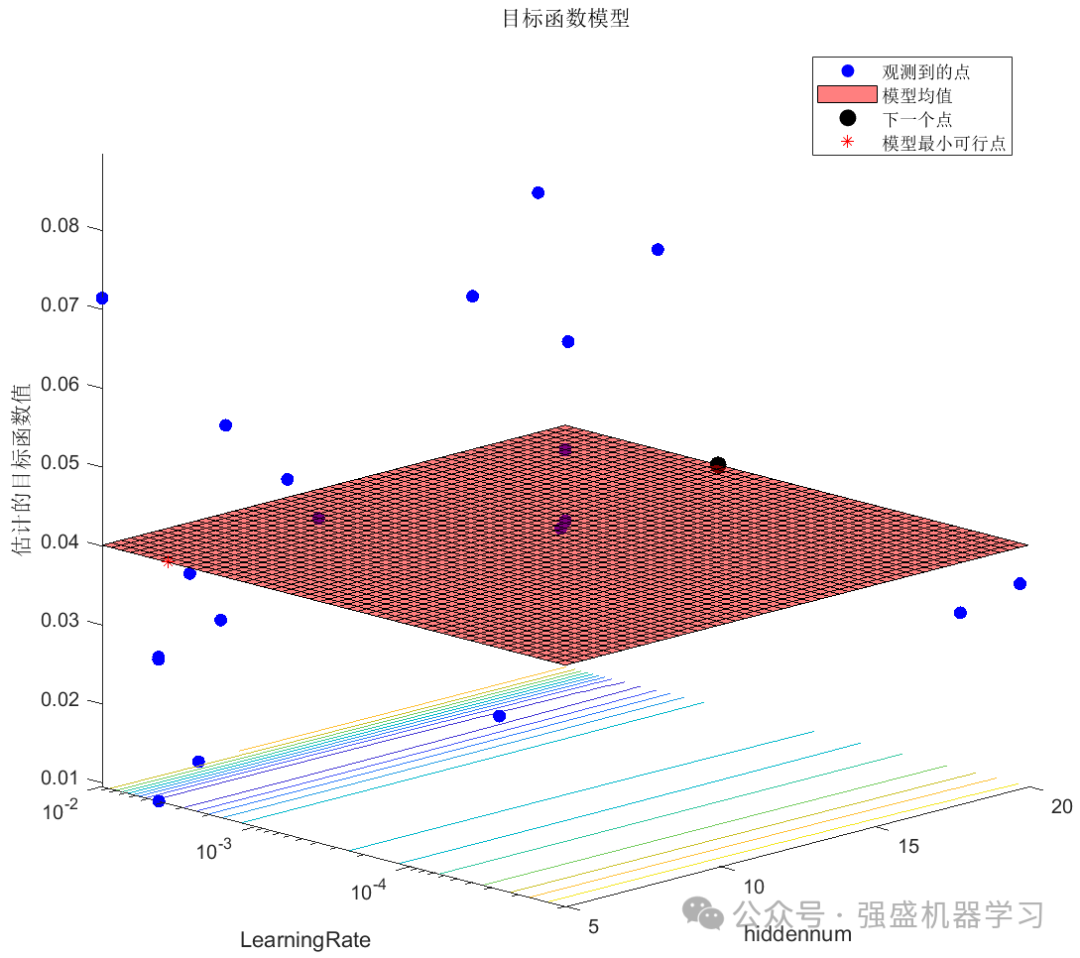
回归拟合图:
麻雀算法适应度曲线:
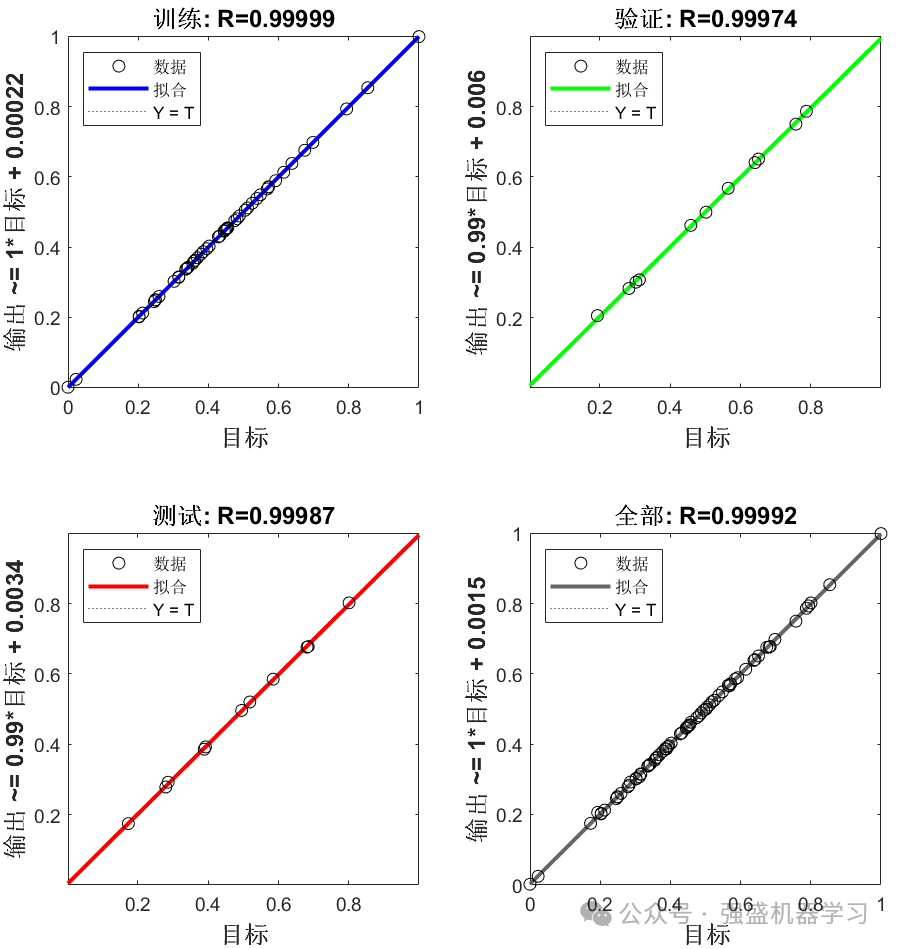
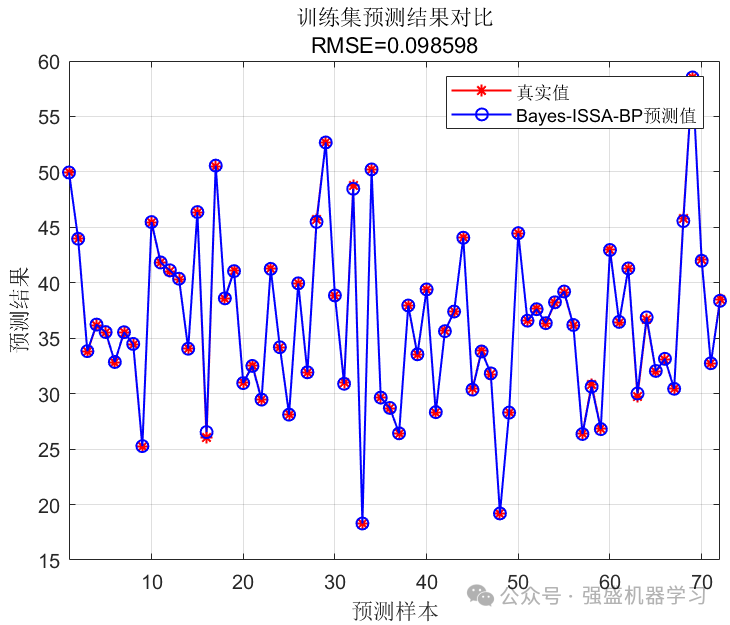
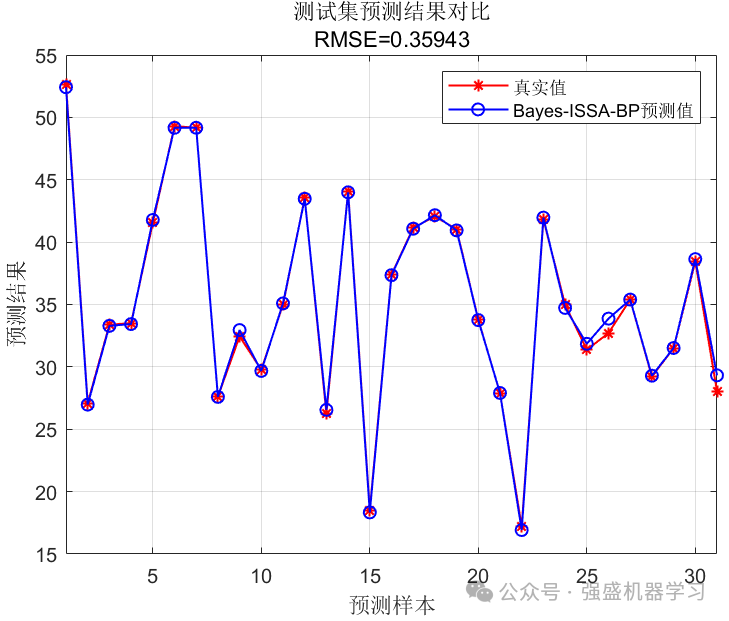
训练集和测试集拟合图:
最后控制台也会输出完整的误差指标结果:
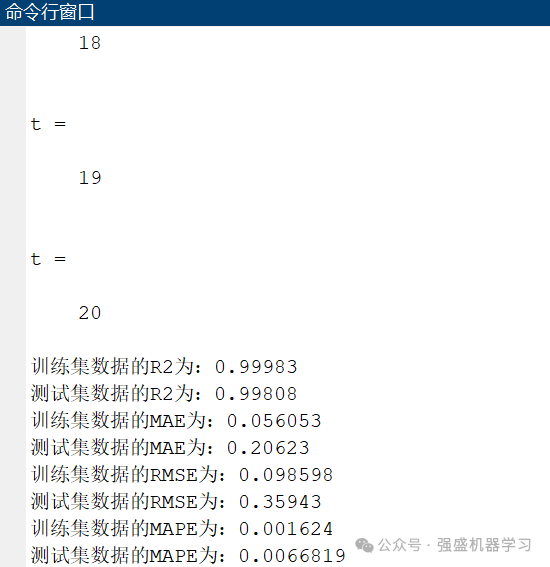
可以看到,我们的Bayes-ISSA-BP模型在该回归数据集上的预测精度还是不错的,R2达到了0.99808,基本和真实值完全对应!MAPE指标仅为0.006,其他指标也都非常非常低!
不同数据集效果不同,可按照上文数据替换方法将自己的数据集替换到程序内查看效果~
以上结果展示中所有图片,作者都已精心整理过代码,都可以一键运行main直接出图!
不同数据集效果不同,可按照上文数据替换方法将自己的数据集替换到程序内查看效果~
05
部分代码展示
%% 清空环境变量warning off % 关闭报警信息close all % 关闭开启的图窗clear % 清空变量clc % 清空命令行%% 导入数据res = xlsread('数据集.xlsx');%% 数据分析num_size = 0.7; % 训练集占数据集比例outdim = 1; % 最后一列为输出num_samples = size(res, 1); % 样本个数res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)num_train_s = round(num_size * num_samples); % 训练集样本个数f_ = size(res, 2) - outdim; % 输入特征维度%% 划分训练集和测试集P_train = res(1: num_train_s, 1: f_)';T_train = res(1: num_train_s, f_ + 1: end)';M = size(P_train, 2);P_test = res(num_train_s + 1: end, 1: f_)';T_test = res(num_train_s + 1: end, f_ + 1: end)';N = size(P_test, 2);%% 数据归一化[p_train, ps_input] = mapminmax(P_train, 0, 1);p_test = mapminmax('apply', P_test, ps_input);[t_train, ps_output] = mapminmax(T_train, 0, 1);t_test = mapminmax('apply', T_test, ps_output);%% 贝叶斯优化隐藏层节点数与学习率