LSTM时序预测-递归预测未来数据,基于长短期记忆神经网络(LSTM)的时间序列预测,递归预测未来数据
LSTM递归预测未来数据的实现步骤通常包括以下几个方面:
- 数据准备:
- 收集时间序列数据:根据预测任务的需求,收集相关的时间序列数据。
- 数据清洗:对收集到的数据进行预处理,包括去除噪声、缺失值填充等。
- 数据归一化:对数据进行归一化处理,以便更好地训练模型。
- 数据划分:将数据集划分为训练集、验证集和测试集。通常,70-80%的数据用于训练,剩余的数据用于验证和测试。
- 构建LSTM模型:
- 确定模型结构:包括LSTM层的层数、隐藏单元数等。这通常需要根据具体任务和数据集进行调整。
- 定义模型的输入和输出:对于时间序列预测,输入通常是过去一段时间的数据,输出则是未来某个时间点的预测值。
- 选择损失函数和优化器:损失函数用于衡量模型预测的准确性,优化器则用于调整模型的参数以最小化损失函数。
- 训练模型:
- 使用训练集数据训练LSTM模型,通过调整模型的参数和结构来优化模型的性能。
- 在训练过程中,可以使用验证集来监控模型的性能,并根据需要进行超参数调优。
- 验证模型:
- 使用测试集数据验证模型的预测效果。通过比较模型的预测值和实际值,可以评估模型的性能。
- 可以使用多种评价指标来评估模型的性能,如均方误差(MSE)、平均绝对误差(MAE)、R方值(R^2)等。
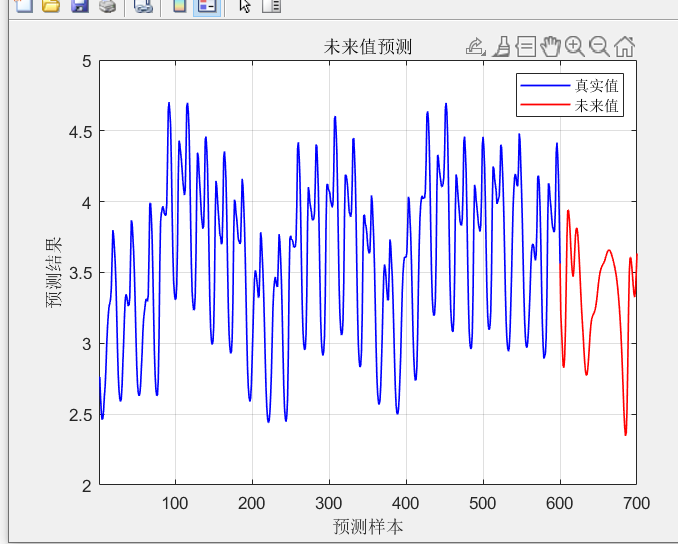
- 递归预测未来数据:
- 一旦模型训练完成并验证其性能良好后,就可以使用模型进行递归预测未来数据了。
- 具体来说,可以将已知的时间序列数据作为输入,使用训练好的LSTM模型进行预测,得到未来某个时间点的预测值。
- 然后,可以将预测值添加到已知的时间序列数据中,形成新的输入数据,再次使用模型进行预测,以此循环递归地预测未来多个时间点的数据。
以时间序列数据集为例进行展示
数据集:
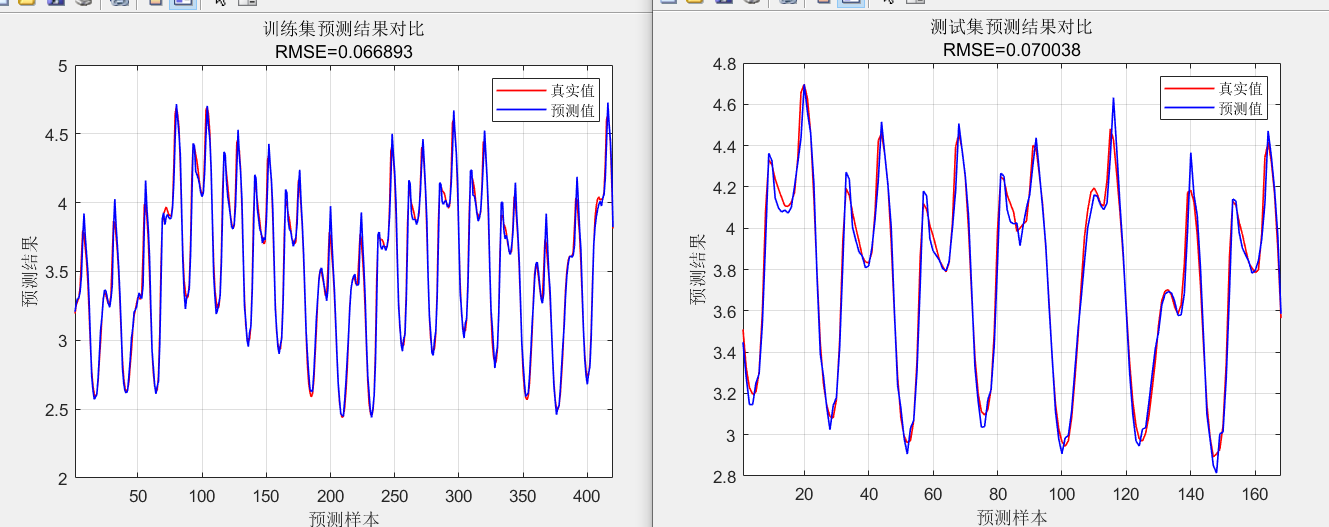
通过对神经元个数等参数进行调试后在训练集和测试集上取得最优表现后

在在训练集和测试集上取得最优表现基础上进行未来数据预测:预测效果图如下: