基于DTW距离测度的Kmeans时间序列聚类算法(matlab)
作品简介 原理介绍
- DTW距离:
- 当两个时间序列不等长时,传统的欧氏距离难以度量它们的相似性。DTW通过调节时间点之间的对应关系,能够寻找两个任意长时间序列中数据之间的最佳匹配路径。
- DTW算法的基本思想是通过将时间序列进行弯曲、拉伸等变换,找到它们之间的最佳匹配路径,从而得到它们之间的相似度。在DTW算法中,距离越小表示两个时间序列越相似。
- DTW对噪声有很强的鲁棒性,适用于语音识别、手写体识别、生物信息学、金融时间序列分析等领域。
- K-means聚类算法:
- K-means算法基于迭代优化,旨在将数据点划分为k个簇,使得每个数据点都属于最近的簇,并且簇的中心是所有数据点的平均值。
- K-means算法的初始化阶段随机选择k个数据点作为初始簇中心,然后通过迭代将数据点分配给最近的簇中心,并更新簇中心点,直到达到收敛条件或预定的迭代次数。
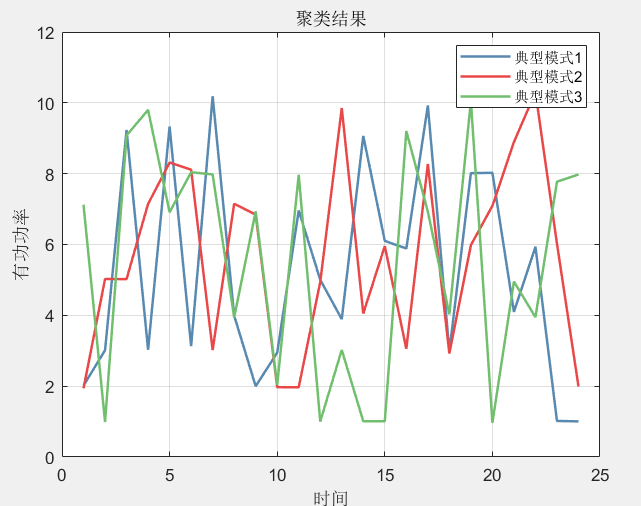
- 结合DTW和K-means:
- 在时间序列聚类中,传统的K-means算法使用欧氏距离作为相似度度量,但这对不等长的时间序列不适用。因此,基于DTW距离的K-means算法使用DTW距离取代欧氏距离,使得算法能够处理不等长的时间序列。
- 该算法首先计算所有时间序列对之间的DTW距离,然后使用这些距离作为输入来执行K-means聚类。