Vehicle Reid(车辆重识别)
B站效果Demo
想要加自己的模型和DIY前端界面,可以看看:说明
前言
随着transformer在多模态上强有力的对齐能力,以前都很难想象5B组图像-文本pair预训练的参数有多强。
现在告诉你,把vit大模型的参数迁移到纯视觉的下游任务,基本上都是指标猛增。
veri-776 mAP随随便便上85,以前那么多前辈辛辛苦苦设计的network不如大量数据来的直接。backbone强大才是真强大,装上v12发动机, 奥拓变法拉利。
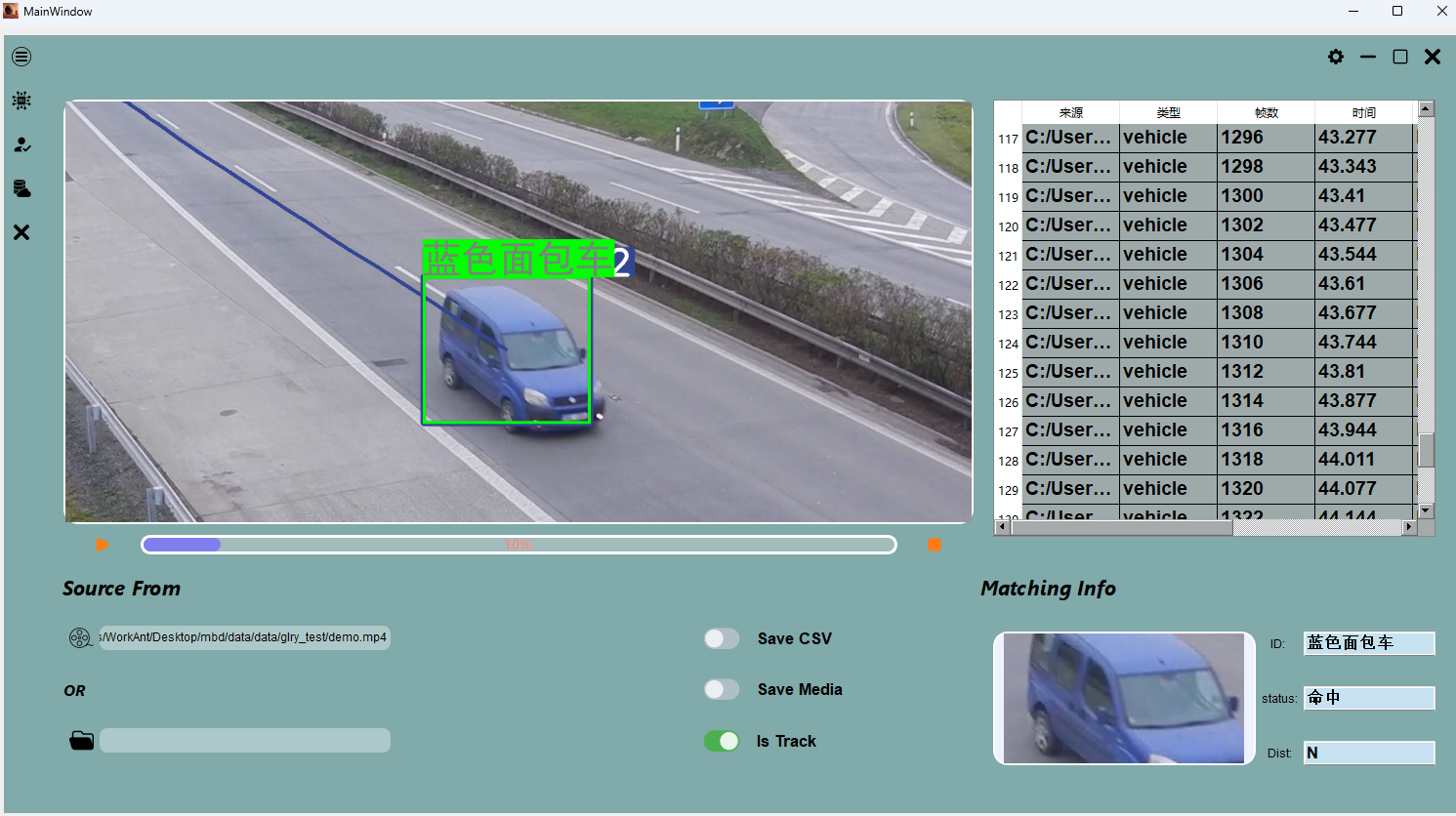
任务目的: 使用一张车的照片,在视频or图像中找到这辆出现的时刻.
问题拆分:
For image: 车辆检测-> vehicle reid -> vector search -> matching.
For video: 车辆检测 -> 多目标跟踪(MOT) -> vehicle reid -> vector search -> matching
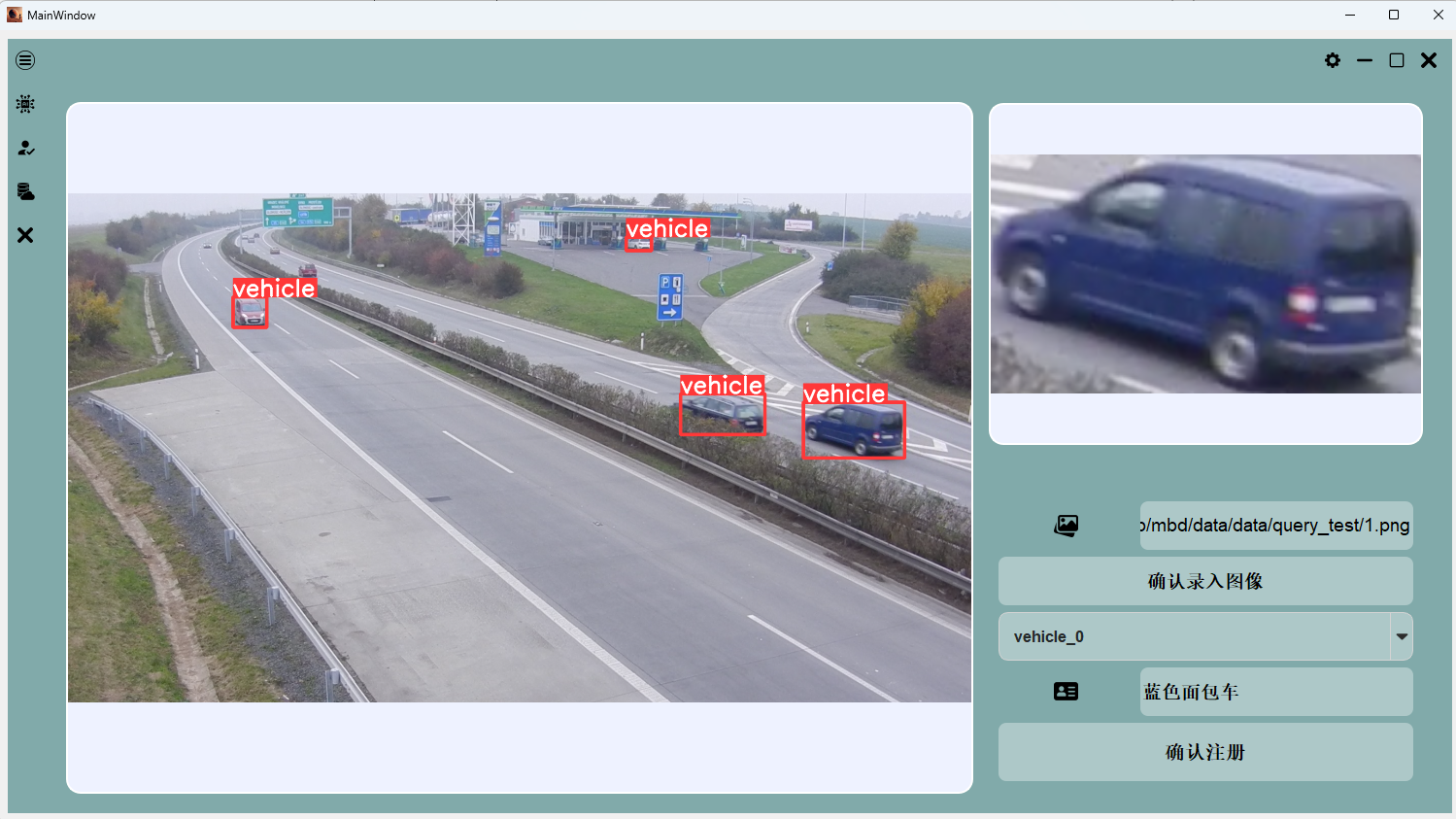
- 车辆检测: YOLO检测器 or 其他的detection模型(技术成熟).
- MOT: 使用滤波/位置等信息跟踪, 来减少调用reid 模型的次数,从而来加速(reid相对track耗时很多,技术成熟)。
- Search engine: Faiss 向量检索库支持物理加速和算法加速(有损)。
- Person Reid: 将目标图像映射到特征空间上, 即输入图像输出vector。这一类属于metric learning, 核心思想是类内相近,类间相远。
Vehicle Reid (复现详情见:[reid复现](https://blog.csdn.net/hard_level/article/details/137510732))
公开数据集
1. VehicleID 数据集由许多不重叠的监控摄像头拍摄。总共有221763张图像,来自26267辆车, 没有跨镜头和view信息。
2. VeRi-776 数据集利用了大约28个交通监控摄像头在各种条件下的图像,如不同方向、照度和遮挡。它包含了49357张图像,涉及776辆车。
指标
Note: clip_reid在VeRi-776上的指标上mAP达到84.5,Rank-1达到97.3.(同时该指标并未加re-rank), 其指标在2024年也是非常有竞争力的。
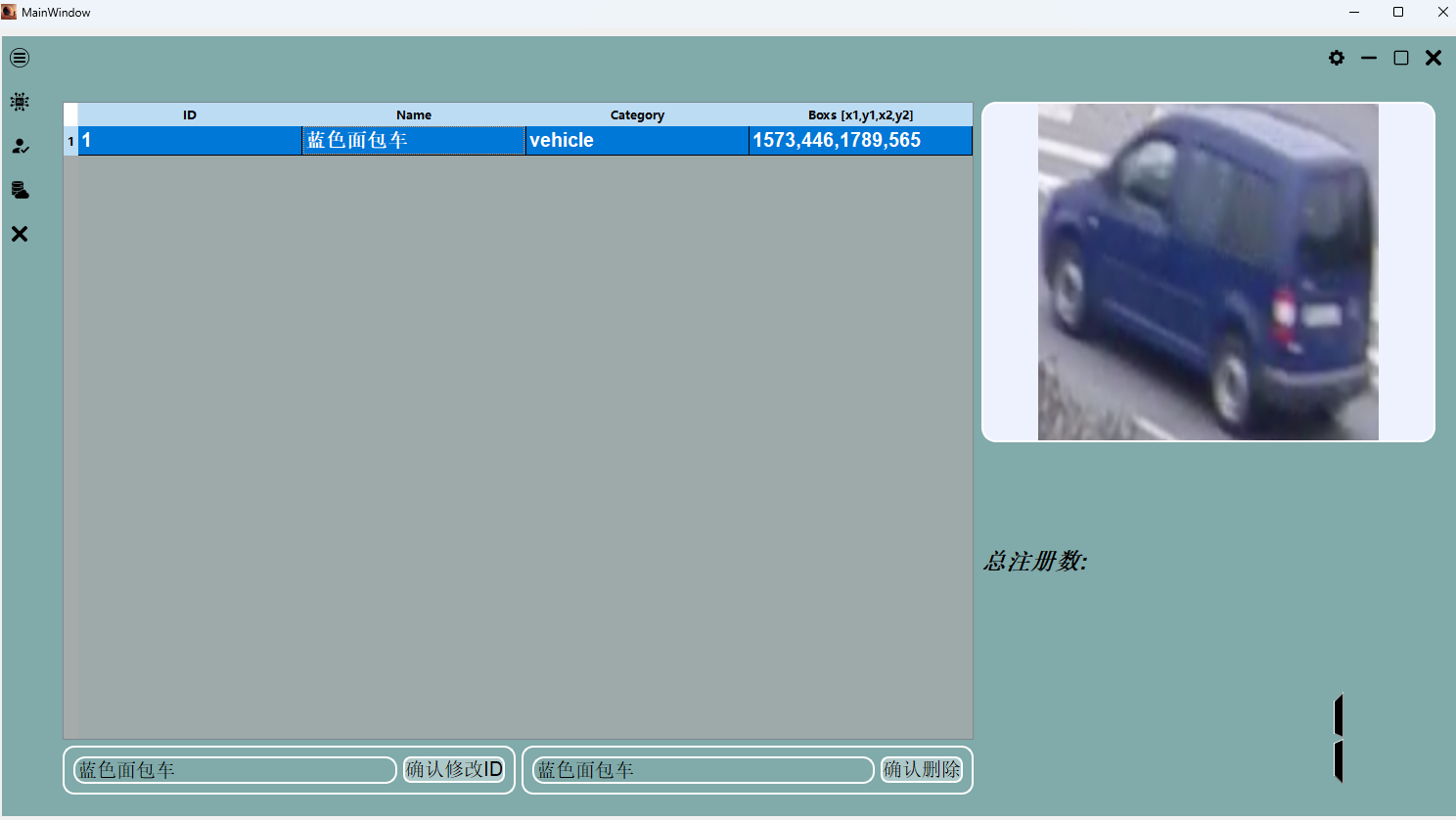
Demo Show
- 设计GUI,画交互图和UI.
- trainning的checkpoint删除梯度等信息转化为跨平台的inference模型(onnx,加速一倍)
- 串联pipeline,参考设计模式,多线程/异步/同步/数据库同步等
- 设计测试用例,测试debug
模型选择:
A. reid_vehicle_id.onnx 模型是在 VehicleID 数据集上训练的,但由于缺少跨镜头的训练数据,其在具有不同视角的车辆检索任务中表现不佳。通常,其检索阈值在约0.2左右。
B.reid_vehicle_veri.onnx 模型则是在 VeRi-776 数据集上训练的,在我们的 demo 测试中表现最佳。一般情况下,其检索阈值在约0.1左右。