基于YOLOv8的车辆行人实时检测系统(python+pyside6界面+系统源码+可训练的数据集+也完成的训练模型)
摘要:
本文提出了一种基于YOLOv8算法的大规模交通物体检测系统(SODA10M),利用9000张图片(8000张训练集,1000张验证集)进行模型训练,最终开发出一个高效的交通物体检测模型。为了方便用户操作和实时检测,本系统还开发了基于Python和PySide6的图形用户界面(GUI),实现了交通物体的实时检测功能。此外,为保障系统安全,系统还配备了用户登录界面,需通过账户和密码方可访问。完整的数据集、检测系统源代码以及已训练好的模型可通过文末链接获取。
1.主要功能:
(1)用户注册、登录与密码修改功能,确保系统的安全性。
(2)支持自定义系统标题、简介及封面,提升用户体验。
(3)检测界面具备最小化、最大化以及退出系统功能。
(4)支持对单张图片、图片文件夹、视频或摄像头进行目标检测。
(5)具备检测暂停、结果保存和检测结束功能,提升灵活性。
(6)可自由切换检测模型,满足不同场景需求。
(7)允许用户调整检测的置信度和IoU阈值。
(8)支持单类目标或特定目标的检测,适应性强。
(9)实时展示检测目标的详细信息及检测用时。
(10)自动记录所有检测目标的坐标信息,方便后续分析。
目标检测系统更多的功能介绍以及详细的操作教程请参考链接:https://blog.csdn.net/2401_85556416/article/details/142906627?fromshare=blogdetail&sharetype=blogdetail&sharerId=142906627&sharerefer=PC&sharesource=2401_85556416&sharefrom=from_link
2.意义:
目标检测是计算机视觉领域的重要组成部分,为智能交通和自动驾驶提供了核心技术支持。车辆和行人的实时检测对于实现安全的自动驾驶至关重要。因此,开发高效的目标检测算法是保障交通安全和顺畅的重要基础。
3.数据集介绍:
本系统所使用的数据集包括训练集(8000张)、验证集(1000张)和测试集(1000张)。数据标签采用YOLO模型常用的TXT格式,方便直接应用于YOLOv8模型的训练。数据集涵盖 6 种类别:Pedestrian: 行人, Cyclist: 骑行者, Car: 汽车, Truck: 卡车, Tram: 电车, Tricycle: 三轮车
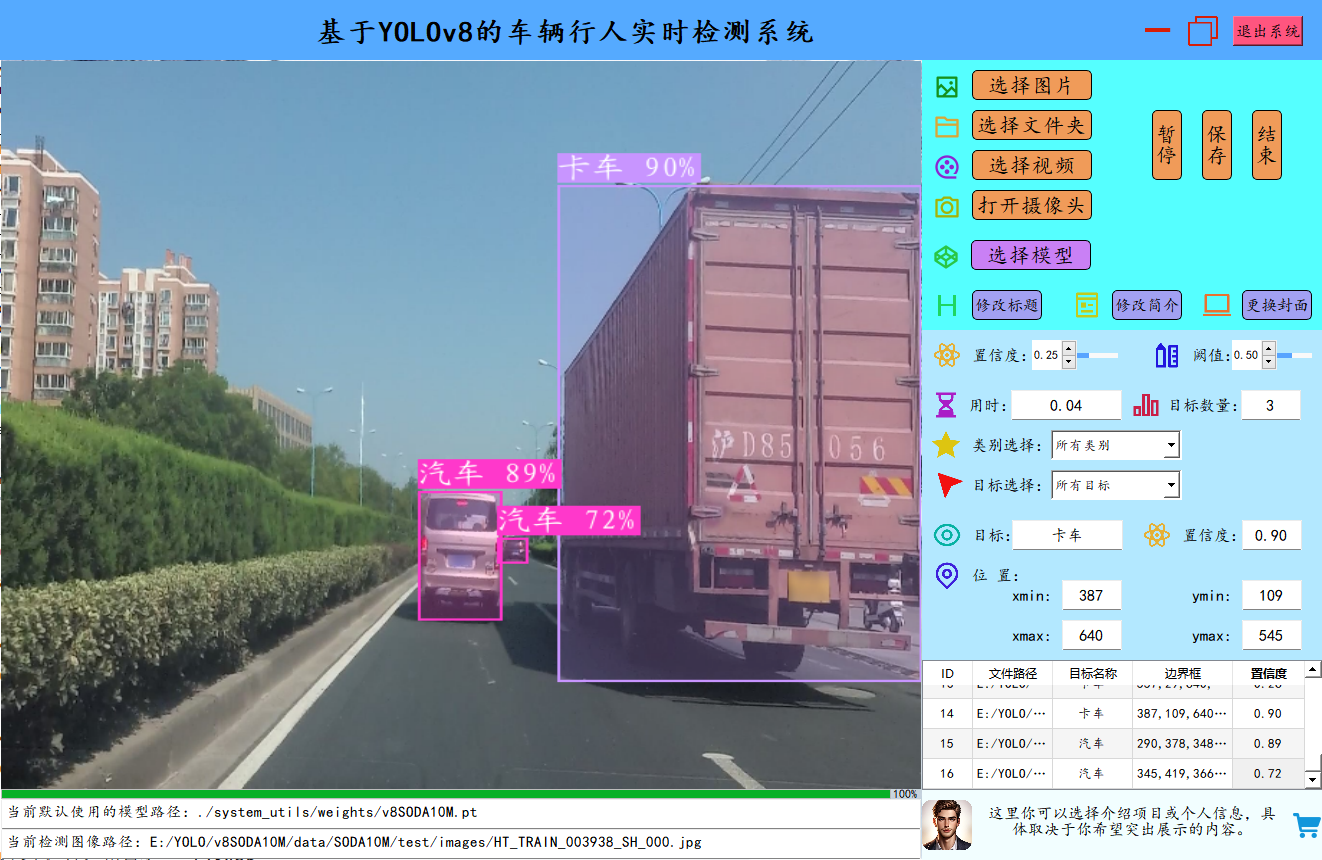
4.检测效果展示:
部分检测结果如下所示,展示了系统在不同场景下的检测表现。

5.YOLOv8模型概述:
YOLOv8的网络结构主要由四个部分组成:Input、Backbone、Neck和Head。
Input部分负责对图像进行预处理操作,包括数据增强和图像缩放等,以优化输入模型的数据。
Backbone部分利用卷积神经网络提取图像特征,包含CBS、SPPF和C2f模块。CBS模块由卷积层(Conv)、批归一化层(BN)和SiLU激活函数组成。SPPF模块通过串联三个5x5的最大池化层来减少计算量,加快处理速度。C2f模块采用梯度分流的思想,结合CBS和残差模块以获取更多的梯度信息,增强模型的特征提取与学习能力。
Neck部分使用FPN+PAN结构,通过上下双向融合多尺度特征,有效提高了模型检测不同大小目标的能力。这一结构在处理复杂背景及不同尺寸目标的图像时,显著提升了检测的准确性。
Head部分采用了解耦头结构,将分类与检测任务分离处理,并使用Anchor-Free的设计取代了传统的Anchor-Based方法。
YOLOv8保持了YOLO系列的核心优势,即高效的实时目标检测能力,同时通过一系列改进,使其在目标检测任务中的精度和速度达到新的高度,适用于更多的工业和科研应用场景。
6.模型的训练结果:
模型是已经训练好了的。训练结果保存在"runs\detect\train"目录下的。其中"runs\detect\train\best.pt"是训练过程中获得的最佳模型。
7.系统界面展示:
用户界面:
初始化界面:
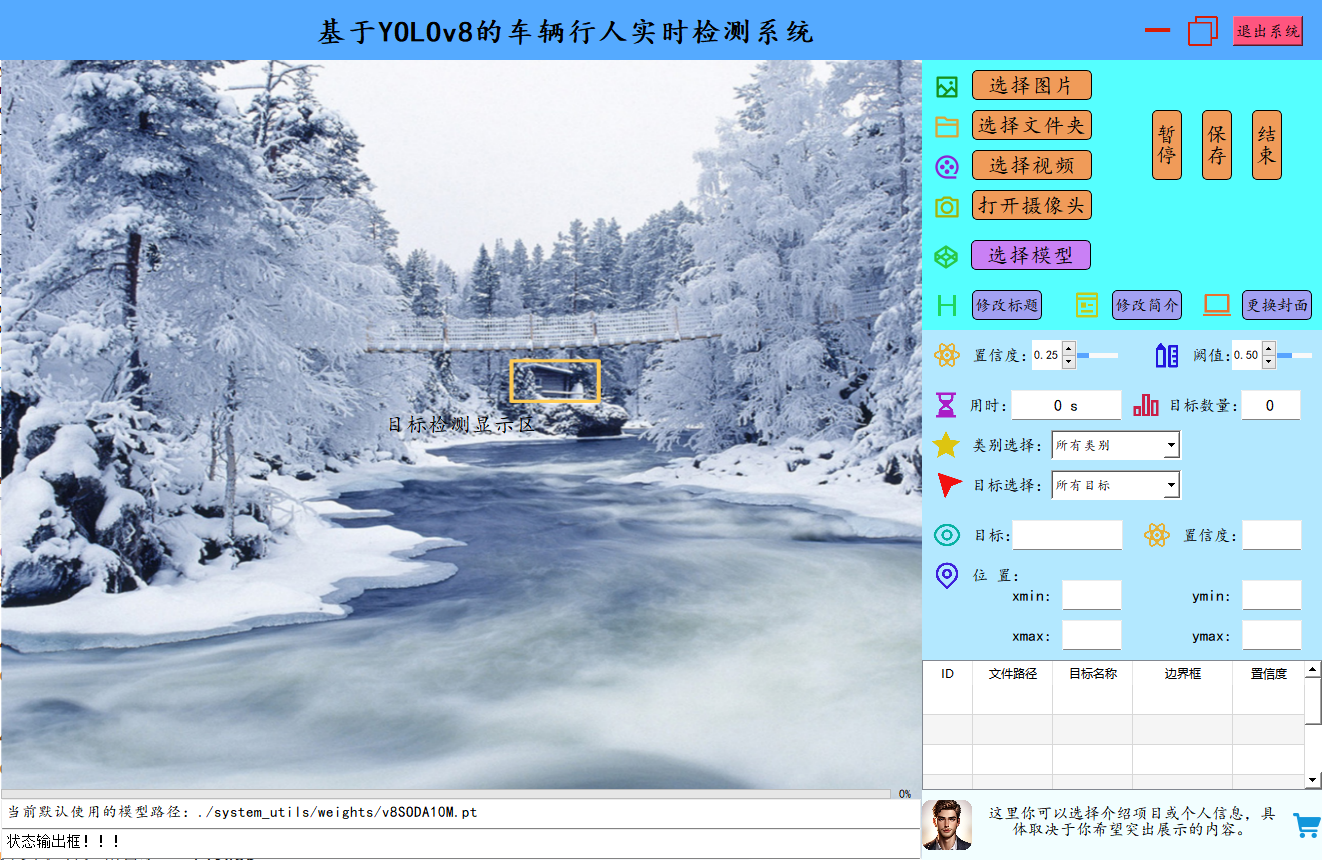
目标检测界面:
付费后可获取完整的项目文件代码!
注意事项:
虚拟产品一经售出概不退款!
版权所有,未经许可禁止盗卖或者用于商用化用途!