1.资源介绍
简介:本文基于YOLOv8深度学习框架,通过7581张图片,训练了一个进行人员是否佩戴安全帽的目标检测模型,准确率高达0.95。并基于此模型开发了一款带UI界面的安全帽检测系统,可用于实时检测人员是否有佩戴安全帽,更方便进行功能的展示。该系统是基于python与PyQT5开发的,支持图片、视频以及摄像头进行目标检测,并保存检测结果。并提供了完整的Python代码和使用教程。
付费完成后面包多网站会在本页面下方自动解锁资源下载链接,滑动页面到下方就能看到了,点击下载即可。
该软件的功能及代码详细介绍见本人在CSDN上分享的博文:【基于YOLOv8深度学习的安全帽目标检测系统】
资源详情如下:
本资源包括完整的python源码、UI界面文件、数据集、训练代码、测试文件等。
【pycharm打开项目界面如下】
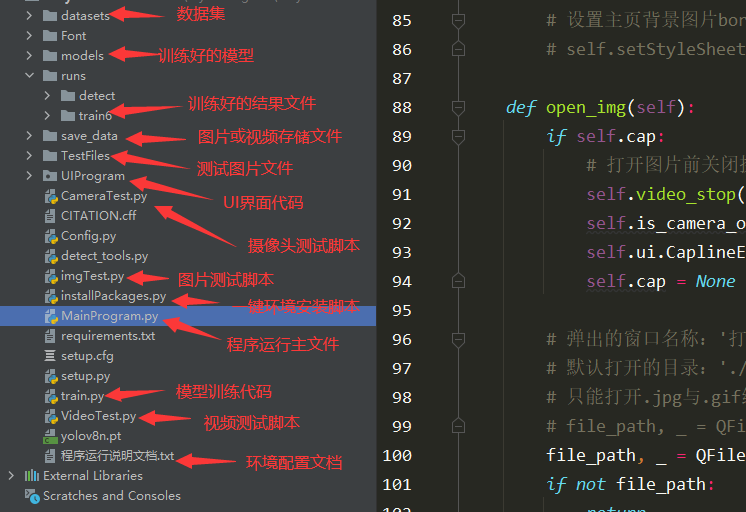
注意:该代码基于Python3.9+pyqt5开发,运行界面的主程序为MainProgram.py,其他测试脚本说明见上图。为确保程序顺利运行,请按照程序运行说明文档txt配置软件运行所需环境。
软件基本界面如下图所示:

一、软件核心功能介绍及效果演示
软件主要功能
1. 可进行人员佩戴安全帽与未戴安全帽两种状态的目标检测;
2.支持图片、视频及摄像头进行检测,同时支持图片的批量检测;
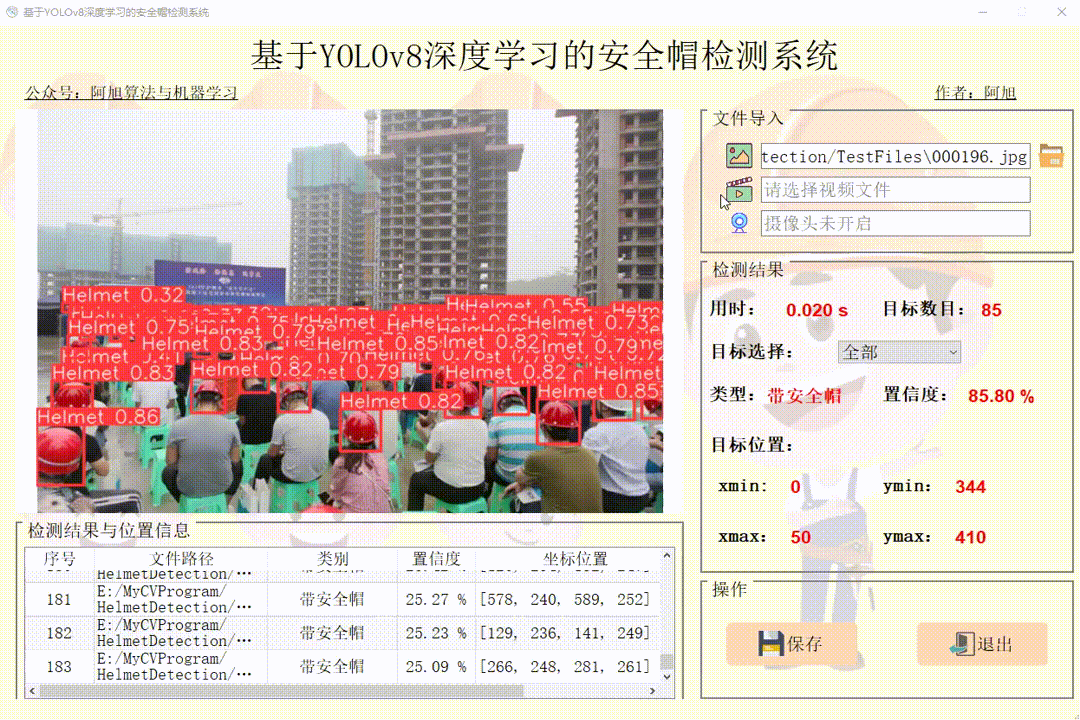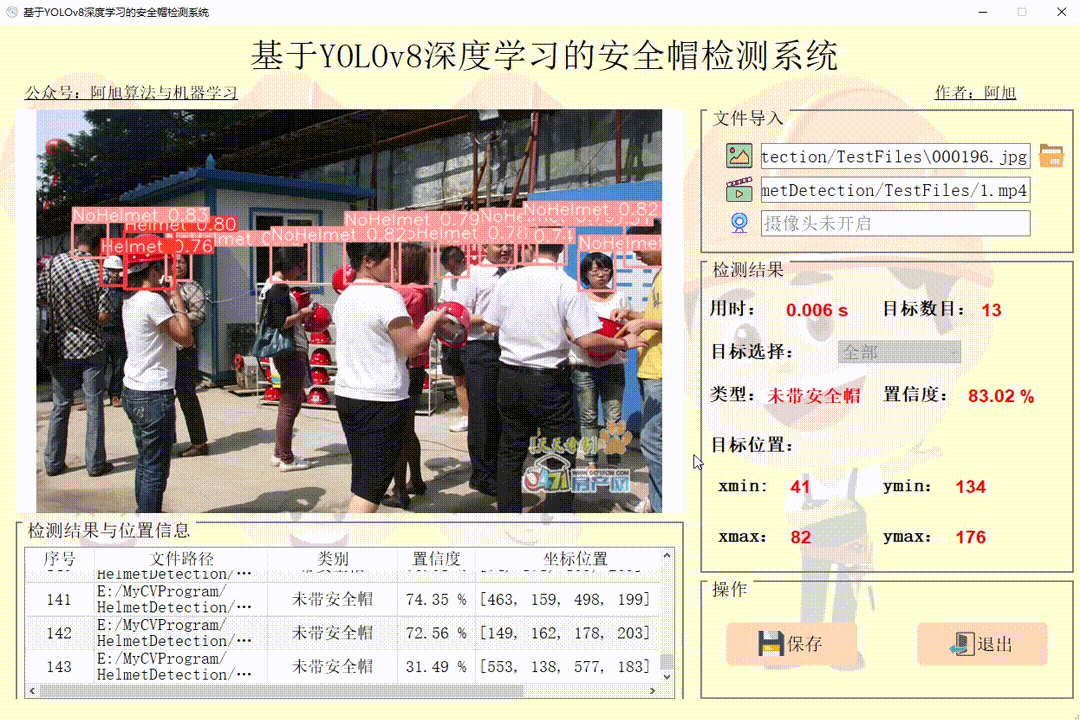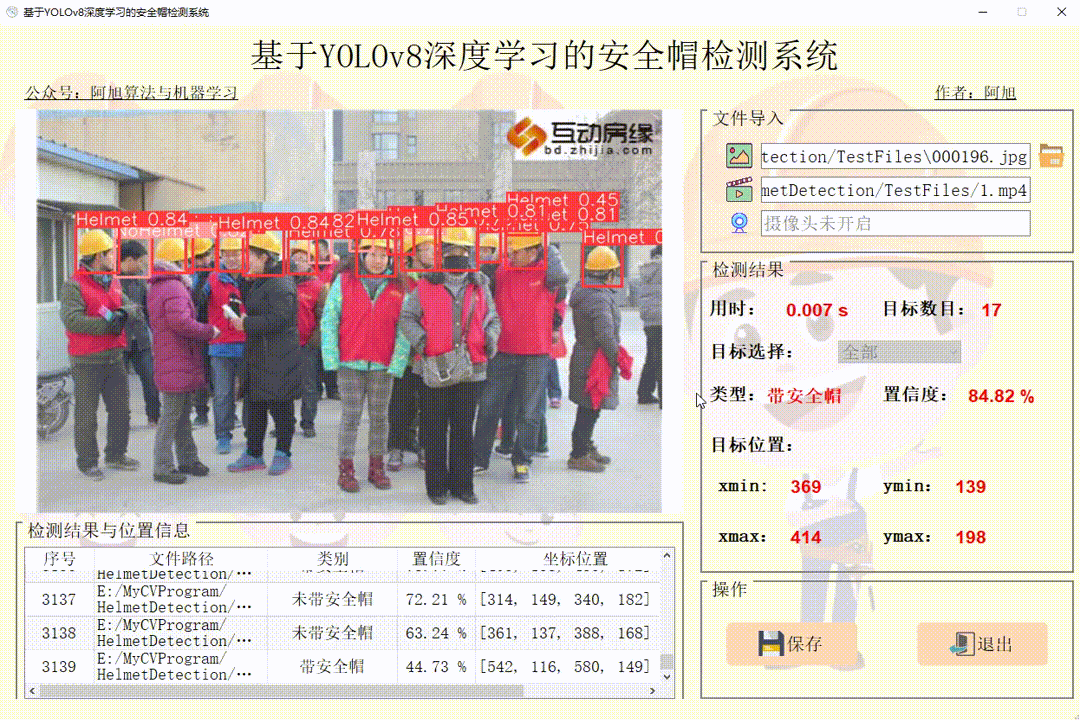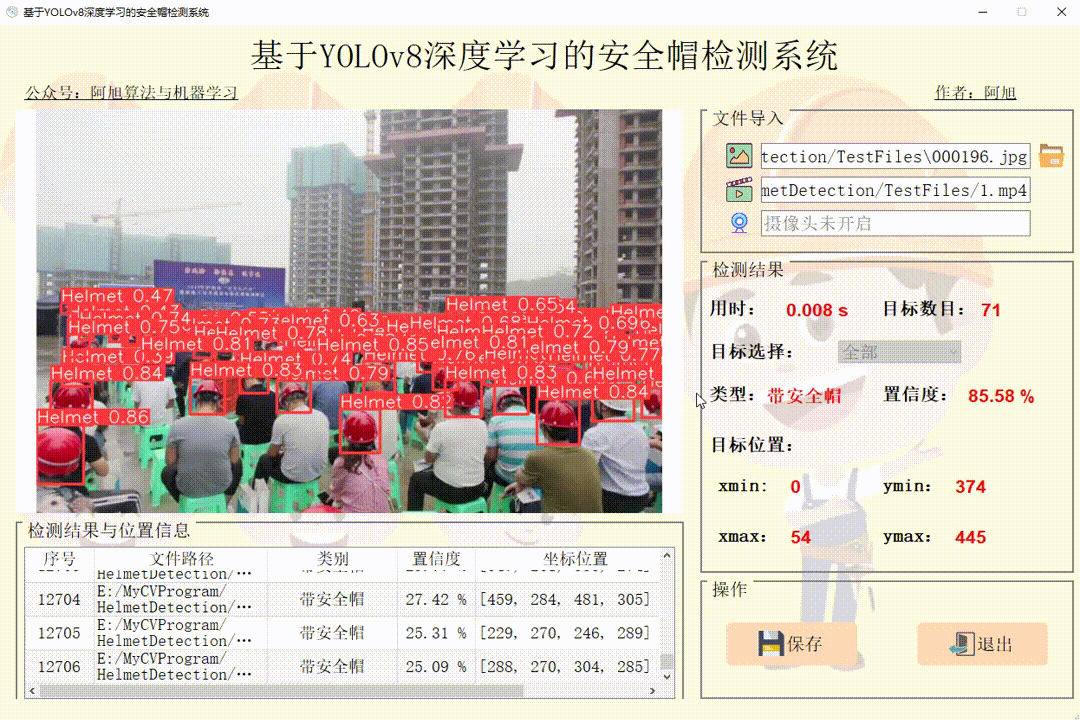
3.界面可实时显示目标位置、目标总数、置信度、用时等信息;
4.支持图片或者视频的检测结果保存;
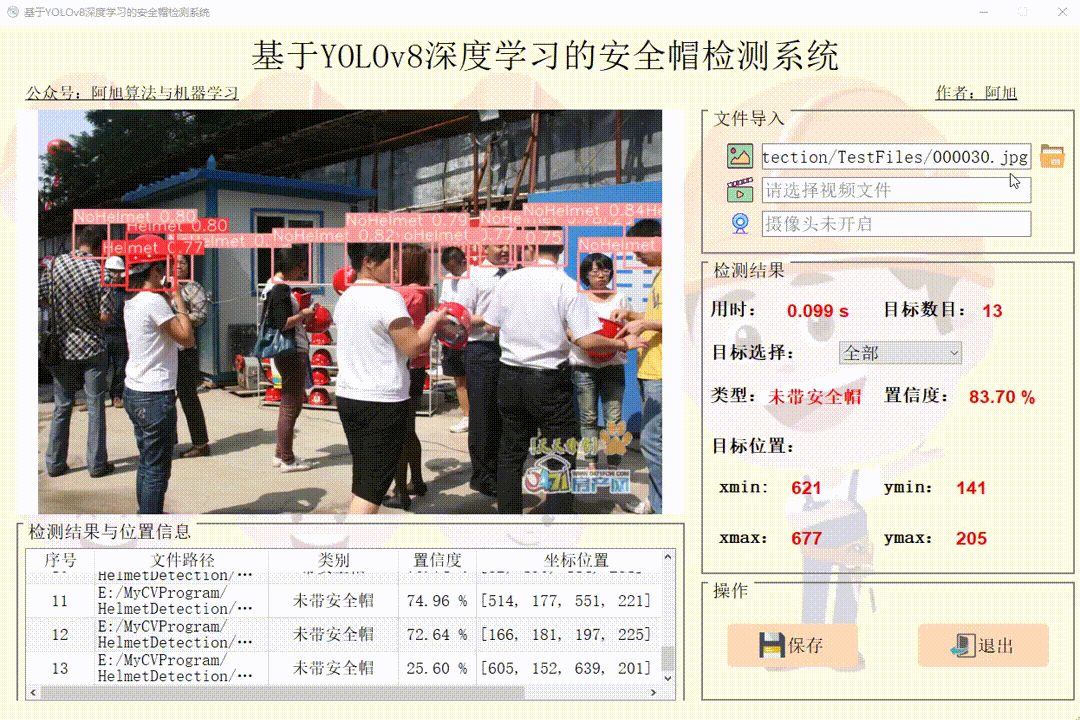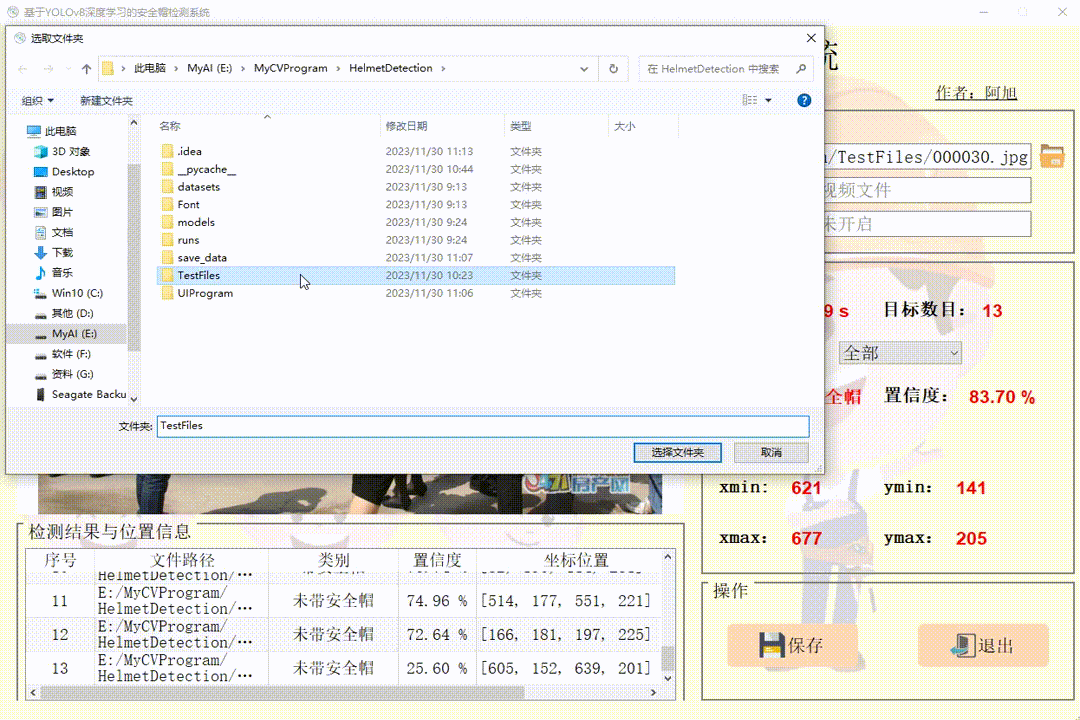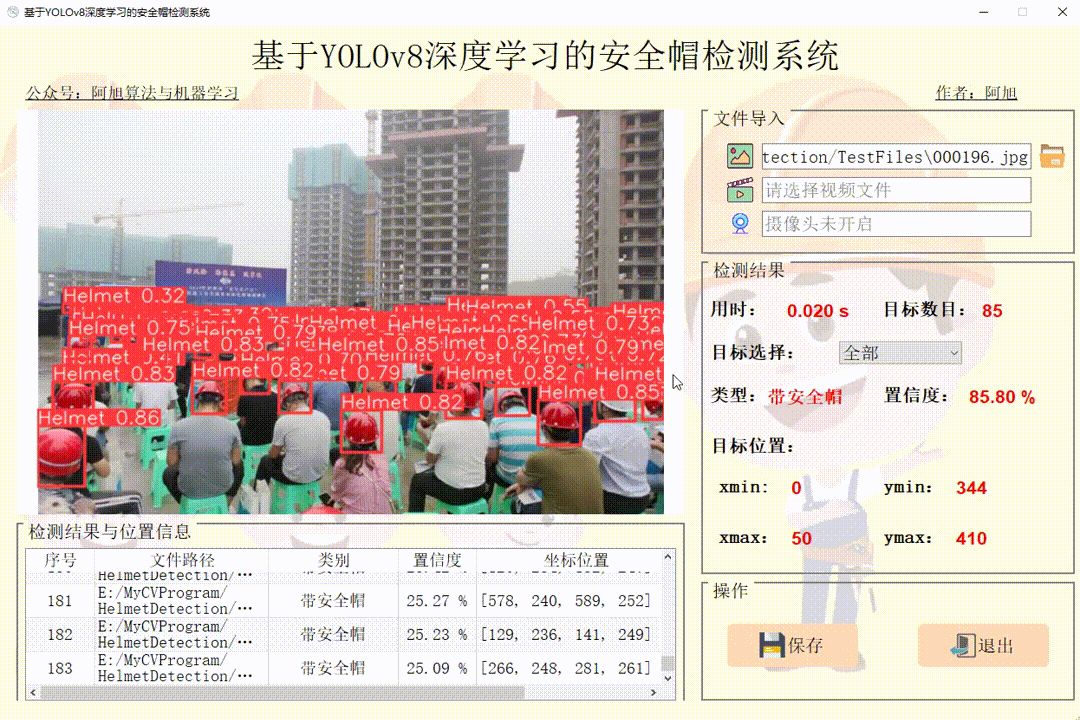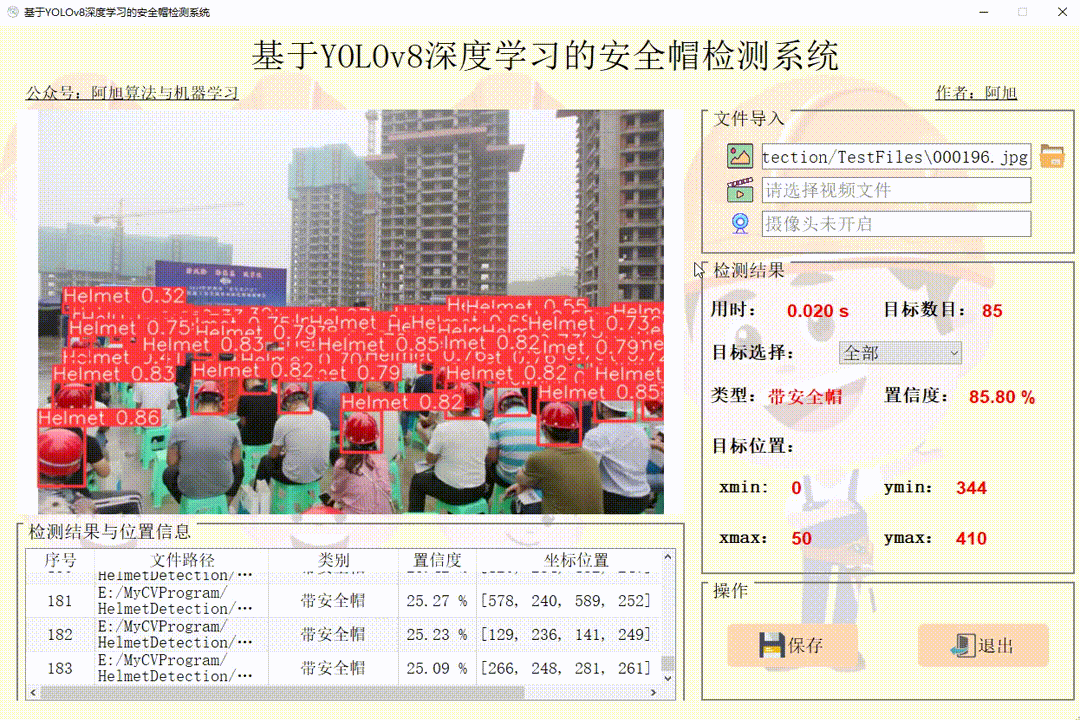
(1)图片检测演示
点击图片图标,选择需要检测的图片,或者点击文件夹图标,选择需要批量检测图片所在的文件夹,操作演示如下:
点击目标下拉框后,可以选定指定目标的结果信息进行显示。 点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。
注:1.右侧目标位置默认显示置信度最大一个目标位置。所有检测结果均在左下方表格中显示。
单个图片检测操作如下:

批量图片检测操作如下:
(2)视频检测演示
点击视频图标,打开选择需要检测的视频,就会自动显示检测结果。点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。
(3)摄像头检测演示
点击摄像头图标,可以打开摄像头,可以实时进行检测,再次点击摄像头图标,可关闭摄像头。
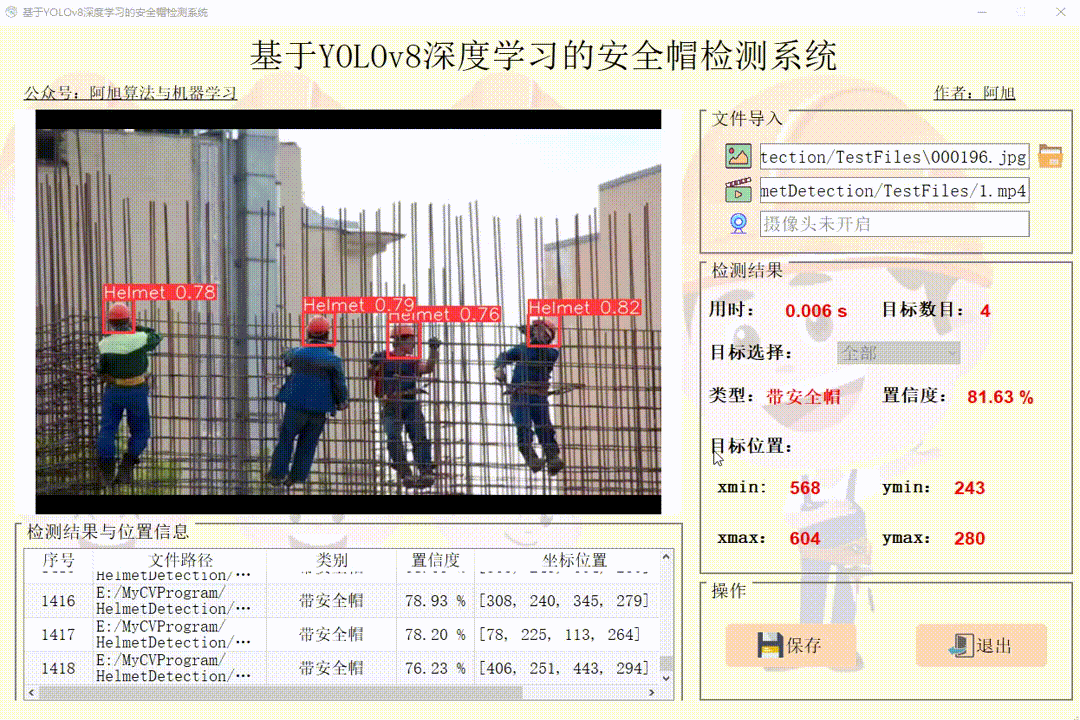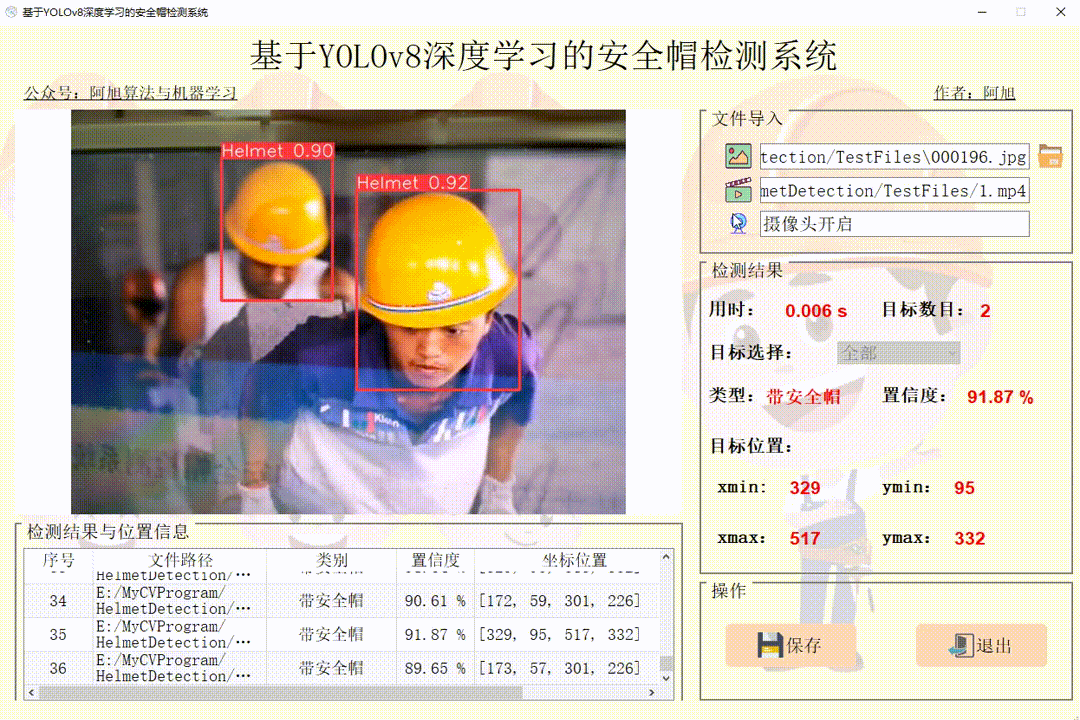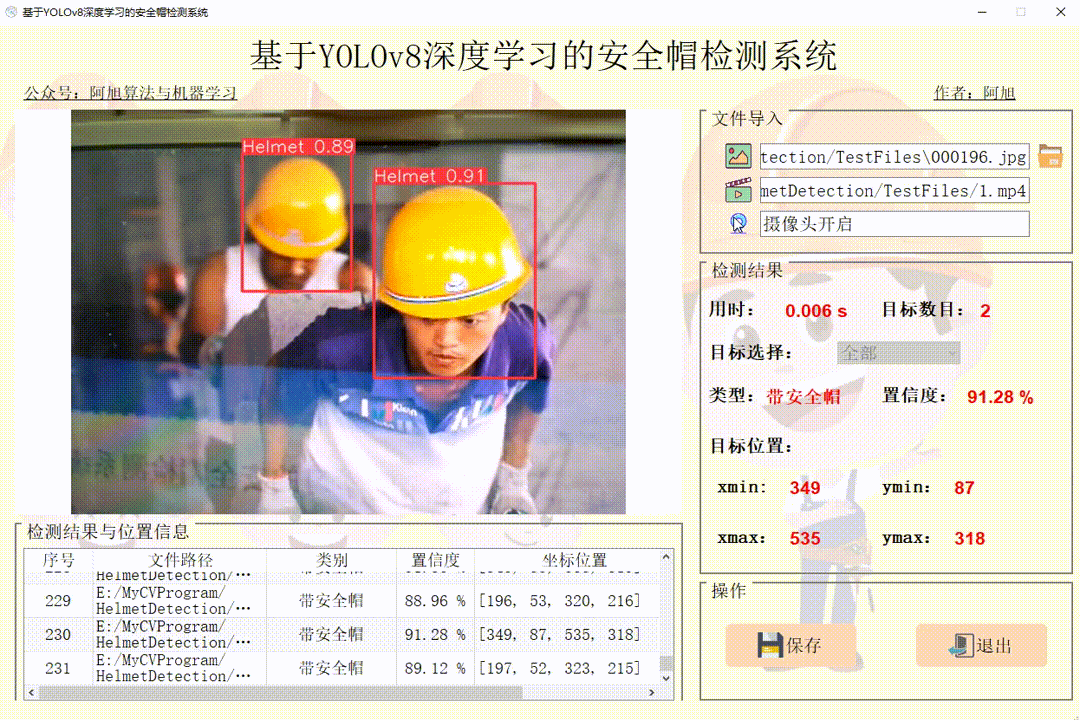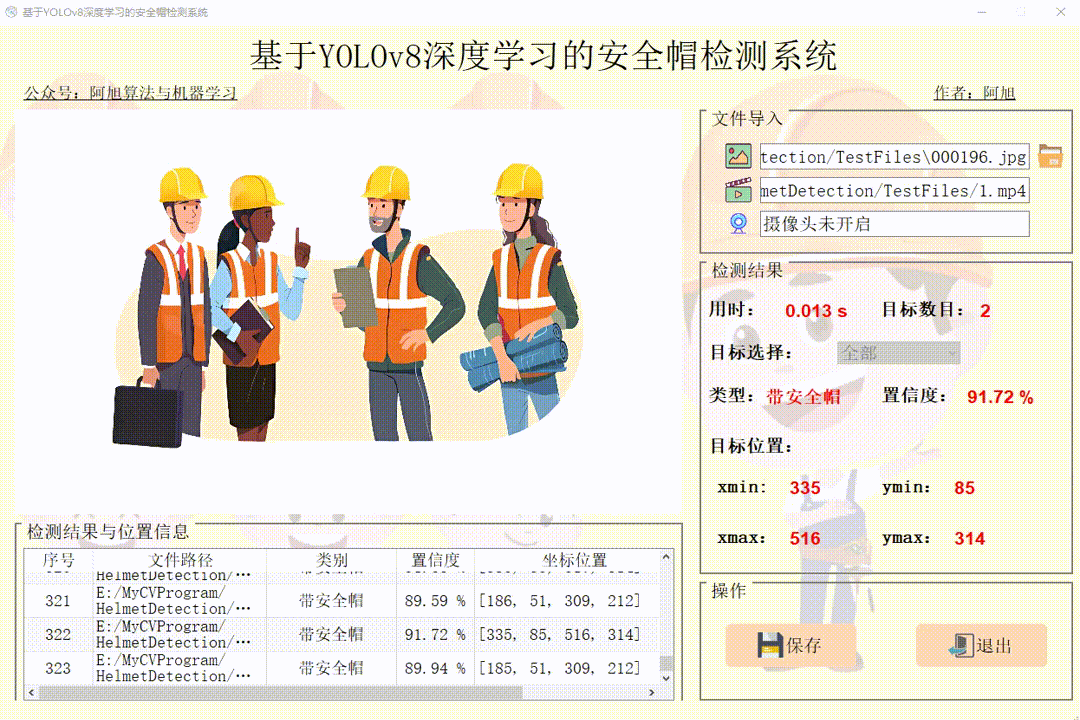
(4)保存图片与视频检测结果
点击保存按钮后,会将当前选择的图片【含批量图片】或者视频的检测结果进行保存。检测的图片与视频结果会存储在save_data目录下。

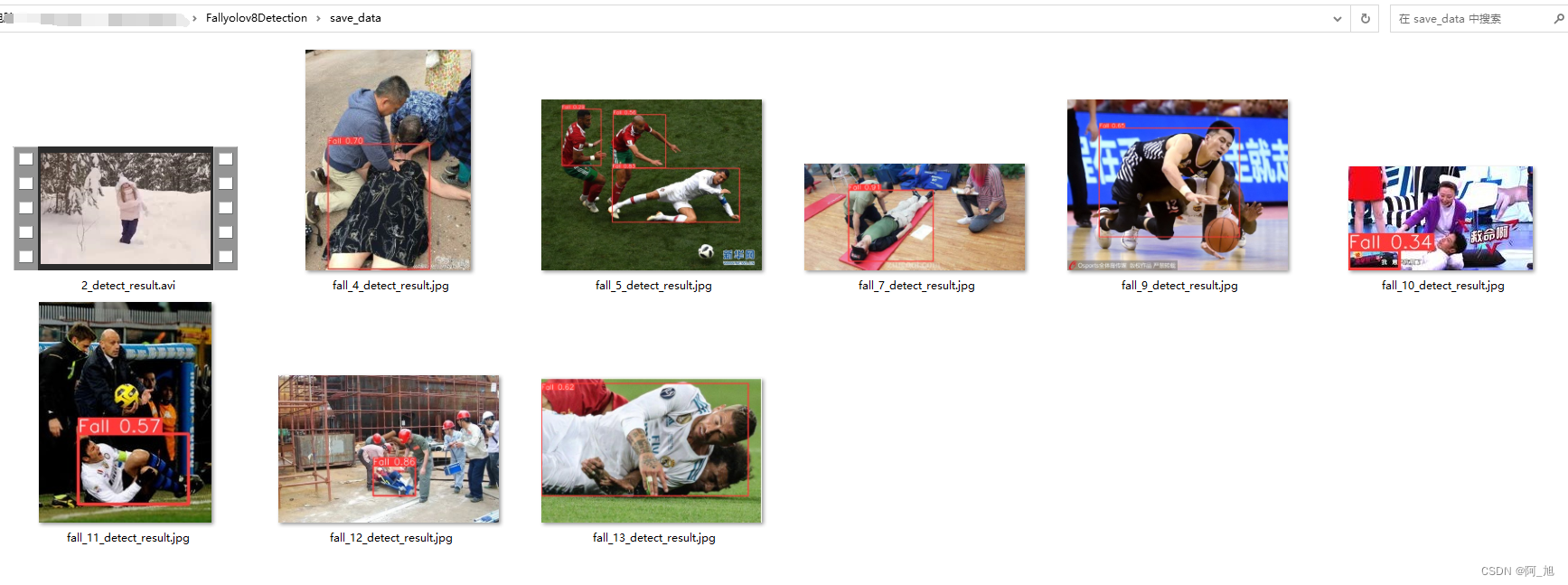
注意事项:
(1) 注意:虚拟产品一经售出概不退款!
(2) 本套系统已经经过本人长时间的调试修改,只需按照要求配置好运行环境,都可以完美运行。
(3) 版权所有,未经许可禁止转载及用于商业化用途;
(4) 该代码基于Python3.9+pyqt5开发,程序运行的主程序为MainProgram.py。为确保程序顺利运行,请按照程序运行说明文档txt配置软件运行所需环境。