【2024年第十二届“泰迪杯”数据挖掘挑战赛】--B题:基于多模态特征融合的图像文本检索的基本思路、完整代码、模型以及结果
一、问题背景
随着近年来智能终端设备和多媒体社交网络平台的飞速发展,多媒体数据呈现海量增长 的趋势,使当今主流的社交网络平台充斥着海量的文本、图像等多模态媒体数据,也使得人 们对不同模态数据之间互相检索的需求不断增加。有效的信息检索和分析可以大大提高平台 多模态数据的利用率及用户的使用体验,而不同模态间存在显著的语义鸿沟,大大制约了海 量多模态数据的分析及有效信息挖掘。因此,在海量的数据中实现跨模态信息的精准检索就 成为当今学术界面临的重要挑战。图像和文本作为信息传递过程中常见的两大模态,它们之 间的交互检索不仅能有效打破视觉和语言之间的语义鸿沟和分布壁垒,还能促进许多应用的 发展,如跨模态检索、图像标注、视觉问答等。
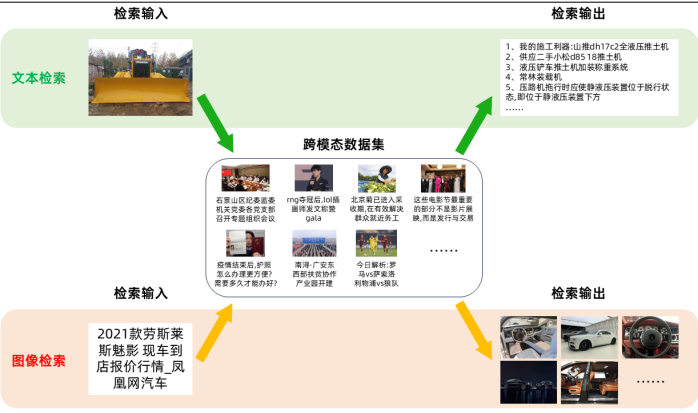
图像文本检索指的是输入某一模态的数据(例如图像),通过训练的模型自动检索出与 之最相关的另一模态数据(例如文本),它包括两个方向的检索,即基于文本的图像检索和 基于图像的文本检索,如图 1 所示。基于文本的图像检索的目的是从数据库中找到与输入句 子相匹配的图像作为输出结果;基于图像的文本检索根据输入图片,模型从数据库中自动检 索出能够准确描述图片内容的文字。然而,来自图像和来自文本的特征存在固有的数据分布 的差异,也被称为模态间的“异构鸿沟”,使得度量图像和文本之间的语义相关性困难重重。
二、解决问题
本赛题是利用附件 1 的数据集,选择合适方法进行图像和文本的特征提取,基于提取的 特征数据,建立适用于图像检索的多模态特征融合模型和算法,以及建立适用于文本检索的 多模态特征融合模型和算法。基于建立的“多模态特征融合的图像文本检索”模型,完成以 下两个任务,并提交相关材料。
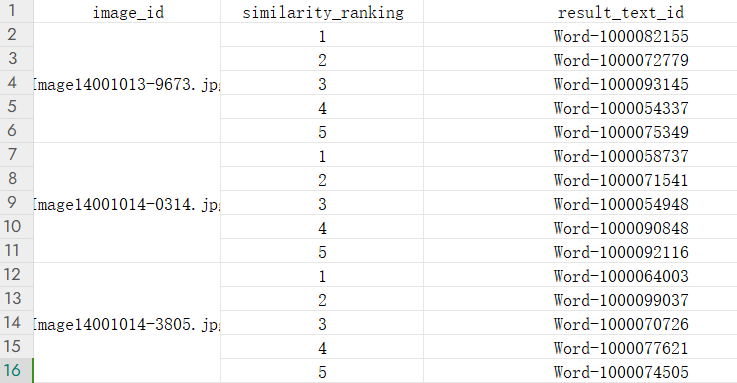
(1)基于图像检索的模型和算法,利用附件 2 中“wordtest.csv”文件的文本信息, 对附件 2 的 ImageData 文件夹的图像进行图像检索,并罗列检索相似度较高的前五张图像, 将结果存放在“result1.csv”文件中(模板文件详见附件4的result1.csv)。其中,ImageData 文件夹中的图像 ID 详见附件 2 的“imagedata.csv”文件。
(2)基于文本检索的模型和算法,利用附件 3 中“imagetest.csv”文件提及的图像 ID,对附件 3 的“worddata.csv”文件进行文本检索,并罗列检索相似度较高的前五条文 本,将结果存放在“result2.csv”文件中(模板文件见附件 4 的 result2.csv)。其中, “image_test.csv”文件提及的图像 id,对应的图像数据可在附件 3 的 ImageData 文件夹 中获取。
三、解题方法
1、基本原理及思路
多模态图文检索的本质上是对图像和文本两种模态的信息进行压缩编码,压缩编码过程可以利用传统方法也可以利用深度学习方法,但最终会得到图像和文本的压缩编码嵌入embedding。在此基础之上,如果得到的embedding是空间对齐的,即两个模态的编码在一个语义空间中,那么就可以利用一般的相似度匹配进行图文检索;如果得到的embedding是空间不对齐的,那么就需要学习相似度匹配方法来更好地匹配两个图文编码向量的相似度,这样的效率虽然高,但得到的效果显然没有进行向量空间对齐的方法好。
空间对齐指的是公共空间特征学习方法,相似度学习指的是跨模态相似性度量方法。前者为主流方法,并且现在的方法都是基于深度学习模型,同时目前的SOTA模型主要为:CLIP、ALBEF、BLIP-2、Fine-grained Image-text Matching by Cross-modal Hard Aligning Network这些较为成熟的方法模型。具体多模态图文检索方法可以参考知乎文章:https://zhuanlan.zhihu.com/p/688195028
考虑到此题环境为中文数据,并且数据的噪声很大。我们考虑利用Chinese-CLIP模型为主干模型进行跨模态检索。该项目是OpenAI CLIP模型的中文版本。使用大量互联网图文信息进行预训练,提供了多个规模的预训练模型和技术报告。
2、检索流程
若想获取项目思路、所有代码、模型以及实验结果,请购买商品!!!
3、部分代码
2.1、文到图检索结果可视化
import json
import csv
import random
import numpy as np
import matplotlib
matplotlib.rc("font",family='SimHei')
# 读取test_t2p_predictions.jsonl文件
with open('test_t2p_predictions.jsonl', 'r', encoding='utf-8') as jsonfile:
predictions = [json.loads(line) for line in jsonfile]
top_k = 5
query_idx_list = random.sample(range(len(predictions)), 6)
query_list = [predictions[i]['text_id'] for i in query_idx_list]
query_ans = {}
image_dir = '附件2/ImageData/'
COLUMNS = ['text_id', 'caption']
for query_idx in query_idx_list:
with open('附件2/word_test.csv', mode='r', encoding='gbk', errors='ignore') as csvfile:
reader = csv.DictReader(csvfile, fieldnames=COLUMNS)
for row in reader:
try:
text_id = int(row['text_id'].split('-')[1])
if text_id == predictions[query_idx]['text_id']:
query_value = predictions[query_idx]['image_ids'][0:top_k]
query_value = [image_dir + get_int2id(item) for item in query_value]
query_ans[row['caption']] = query_value
continue
except Exception as e:
print(f"处理行出错:{e}")
print(query_ans)
2.2、图到文检索结果可视化
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import json
import csv
import os
from PIL import Image, ImageSequence
matplotlib.rc("font",family='SimHei')
import random
# 读取test_p2t_predictions.jsonl文件
with open('test_p2t_predictions.jsonl', 'r', encoding='utf-8') as jsonfile:
predictions = [json.loads(line) for line in jsonfile]
top_k = 5
query_idx_list = random.sample(range(len(predictions)), 4)
query_list = [predictions[i]['image_id'] for i in query_idx_list]
query_ans = {}
image_dir = '附件3/ImageData/'
COLUMNS = ['image_id']
word_data_dict = {}
# 对word_data.csv中的text_id做映射到caption(即文本内容):
with open('附件3/word_data.csv', mode='r', encoding='gbk', errors='ignore') as csvfile:
reader = csv.DictReader(csvfile, fieldnames=['text_id', 'caption'])
for row in reader:
word_data_dict[row['text_id']] = row['caption']
for query_idx in query_idx_list:
with open('附件3/image_test.csv', mode='r', encoding='utf-8', errors='ignore') as csvfile:
reader = csv.DictReader(csvfile, fieldnames=COLUMNS)
for row in reader:
try:
image_id = get_id2int(row['image_id'])
if image_id == predictions[query_idx]['image_id']:
query_value = predictions[query_idx]['text_ids'][0:top_k]
text_id_list = [word_data_dict['Word-' + str(item)] for item in query_value]
query_ans[image_dir + get_int2id(image_id)] = text_id_list
continue
except Exception as e:
print(f"处理行出错:{e}")
print(query_ans)
若想获取项目思路、所有代码、模型以及实验结果,请购买商品!!!
4、部分检索结果