功能
PyThon实现的目标检测系统代码,基于深度学习框架PyTorch编程,采用 YOLOv7-Tiny检测网络作为核心模型,可用于对车辆、行人、飞机、轮船、猫、狗等几十种类别进行检测和识别,并在QT界面中将结果可视化。代码可用于训练、验证和评估模型。在QT界面中,用户可以选择加载图像、摄像头和视频流三种模式作为模型输入。对模型训练完成后,用户可以根据自己数据集完成权重替换并可视化结果。用户还可以根据自己的需求,去更改QT界面的背景、按钮等,界面的操作和相关的代码都有详细的注释。
数据集检测类别
常用包括车辆、行人、飞机、轮船、猫、狗、马、鸟、羊、自行车、瓶、椅子、火车、沙发、餐桌、电视机、盆栽植物等几十个类别进行检测和识别。

PYQT界面:用户还可以根据自己的需求,去更改QT界面的背景、按钮等
给出的模型均已训练完成,自带权重文件!
模型
YOLOv7-Tiny 是一种高效的轻量级目标检测算法,专为计算资源有限的设备设计。在YOLOv7 的基础上,YOLOv7-Tiny 采用了更紧凑的网络架构和优化的训练策略。通过降低模型参数和计算量,YOLOv7-Tiny 成功实现了在嵌入式设备和移动端的实时运行。尽管模型轻量化,但YOLOv7-Tiny 仍保持了良好的目标检测性能。总之,YOLOv7-Tiny 为各种计算受限场景提供了实时目标检测的解决方案,拓宽了计算机视觉在实际应用中的广度。
文件夹包含的内容
- 完整的程序文件(.py)
- UI界面文件(qt.py)
- 可供预测的图像文件和视频文件(./img/street.jpg and video.avi)
- 训练和预测代码(.py)
注意事项
- 付费后会收到文件的百度云链接噢!!!
- 版权所有,未经许可禁止商用和转载!
- 质量有保证,一经售出概不退款!
展示
(1)加载图像进行检测:可以选择图像进行目标检测,系统将检测和识别后的结果标注在图像上并在界面上自动展示。

(2)加载视频进行检测:可以选择视频进行目标检测,系统将检测和识别后的结果标注在视频上并在界面上自动展示。
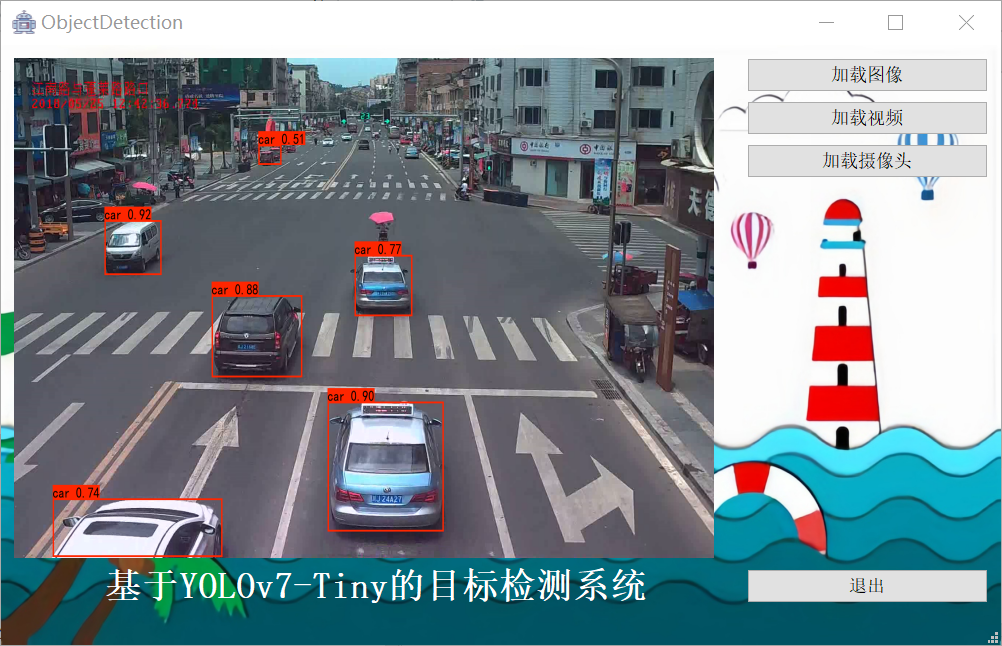
(3)加载摄像头进行检测:可以选择摄像头进行目标检测,系统将检测和识别后的结果标注在图像流上并在界面上自动展示。
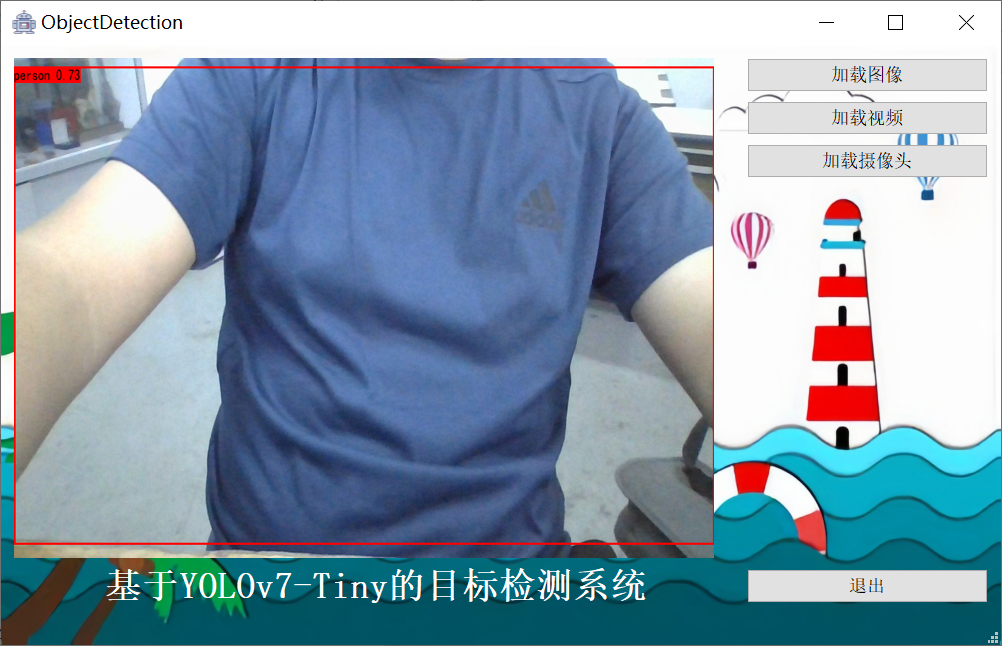
操作界面