模型:YOLOv5是一种基于深度学习的端到端目标检测算法,它使用单个神经网络模型,可以同时对图像或视频中的多个物体进行识别和定位。相比于之前的版本,YOLOv5具有更高的检测精度和更快的检测速度。YOLOv5采用了CSPDarknet网络架构,使用一系列卷积和残差块来提取特征,并通过多个尺度的特征融合来提高检测性能。此外,YOLOv5还引入了自适应的图像增强技术,可以根据不同的输入图像进行自适应调整,提高模型的鲁棒性。通过使用大规模的数据集进行训练,YOLOv5可以检测出各种尺寸、方向和姿态的物体,并在各种场景下都具有较强的适应性。YOLOv5是一种高性能、实时的目标检测算法,具有高检测精度、低计算复杂度和良好的可扩展性,广泛应用于自动驾驶、无人机监视、智能监控等领域。
功能:Python实现的手势识别系统,采用YOLOv5作为核心模型,内置三种YOLOv5模型训练结果(YOLOv5s/YOLOv5m/YOLOv5l)(可随意切换),并在PYQT界面中对各种结果实现可视化,用户可在PYQT界面中选择各种图片、视频、摄像头检测进行检测识别,并可随意更换检测模型。 用于智能检测物体种类并记录和保存结果,也可根据自己的数据集按内置详细教程切换原模型与三种已配置好的注意力机制模型进行模型训练。对各种物体检测结果可视化,提高目标识别的便捷性和准确性。给出Python的实现代码、预训练模型,以及PYQT界面设计。
付费完成后面包多网站会在本页面下方自动解锁资源下载链接,下滑至页面下方即可查看,点击下载即可。
文件夹内包含以下文件:

(由于项目太大,所有内容已存于永久百度网盘)
功能演示
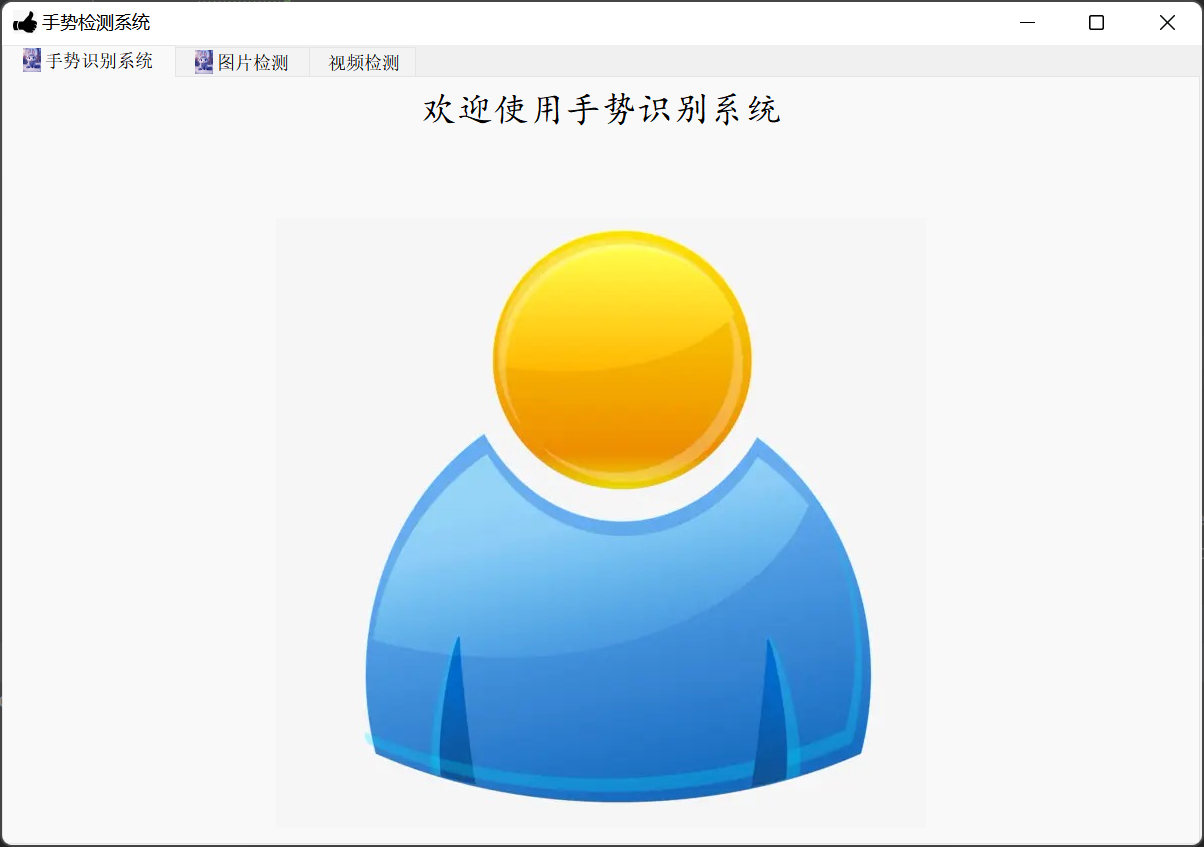
(1)选择图片检测:用户可以选择单张图片进行目标检测,系统自动识别图片中的举手行为。
(2)选择视频检测:用户可以选择视频文件进行检测,系统自动识别视频中的举手行为。
(3)调用摄像头进行检测:用户可以启用计算机摄像头进行实时检测,系统自动识别摄像头捕捉到的人物举手行为并框选。

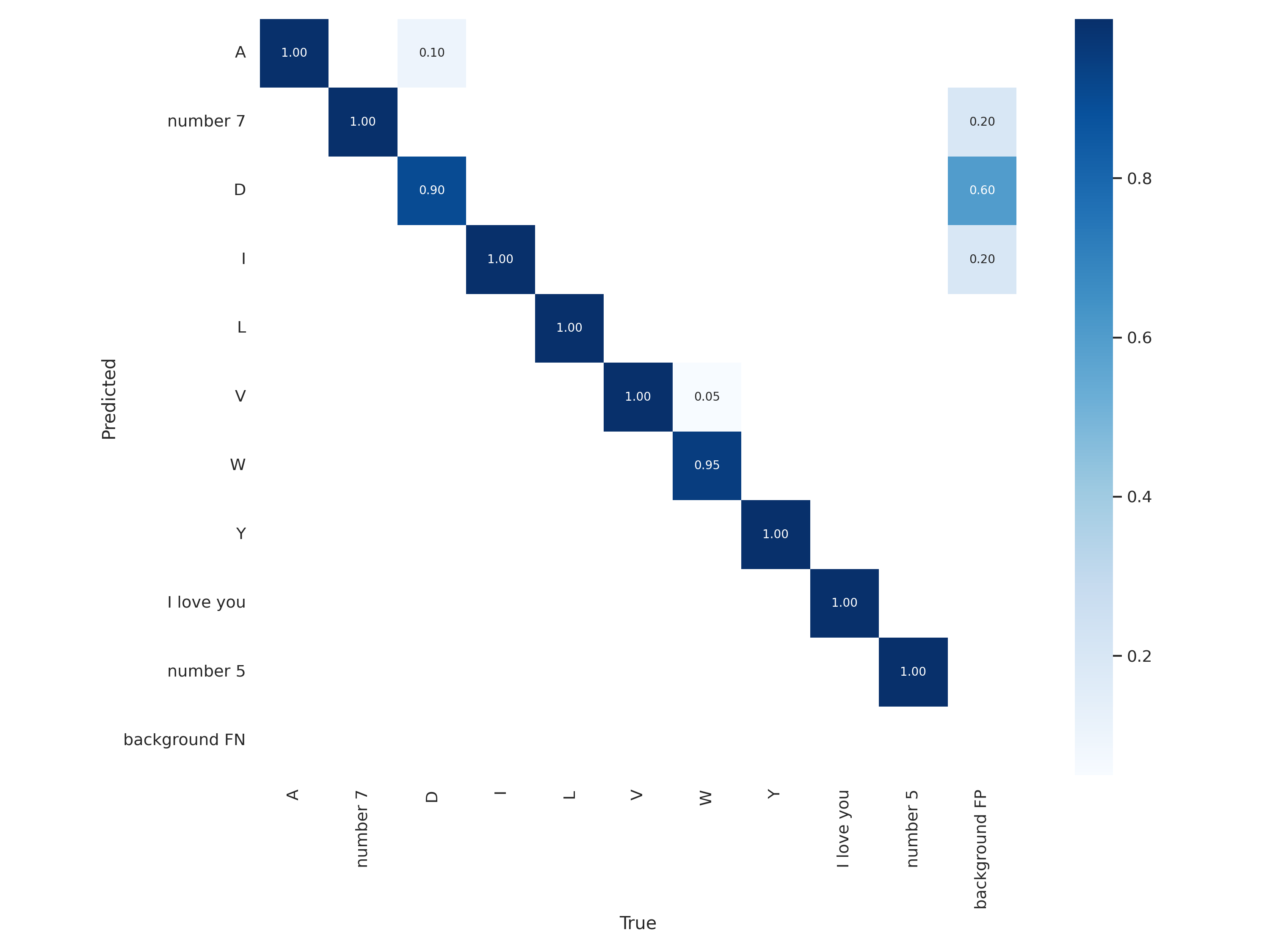
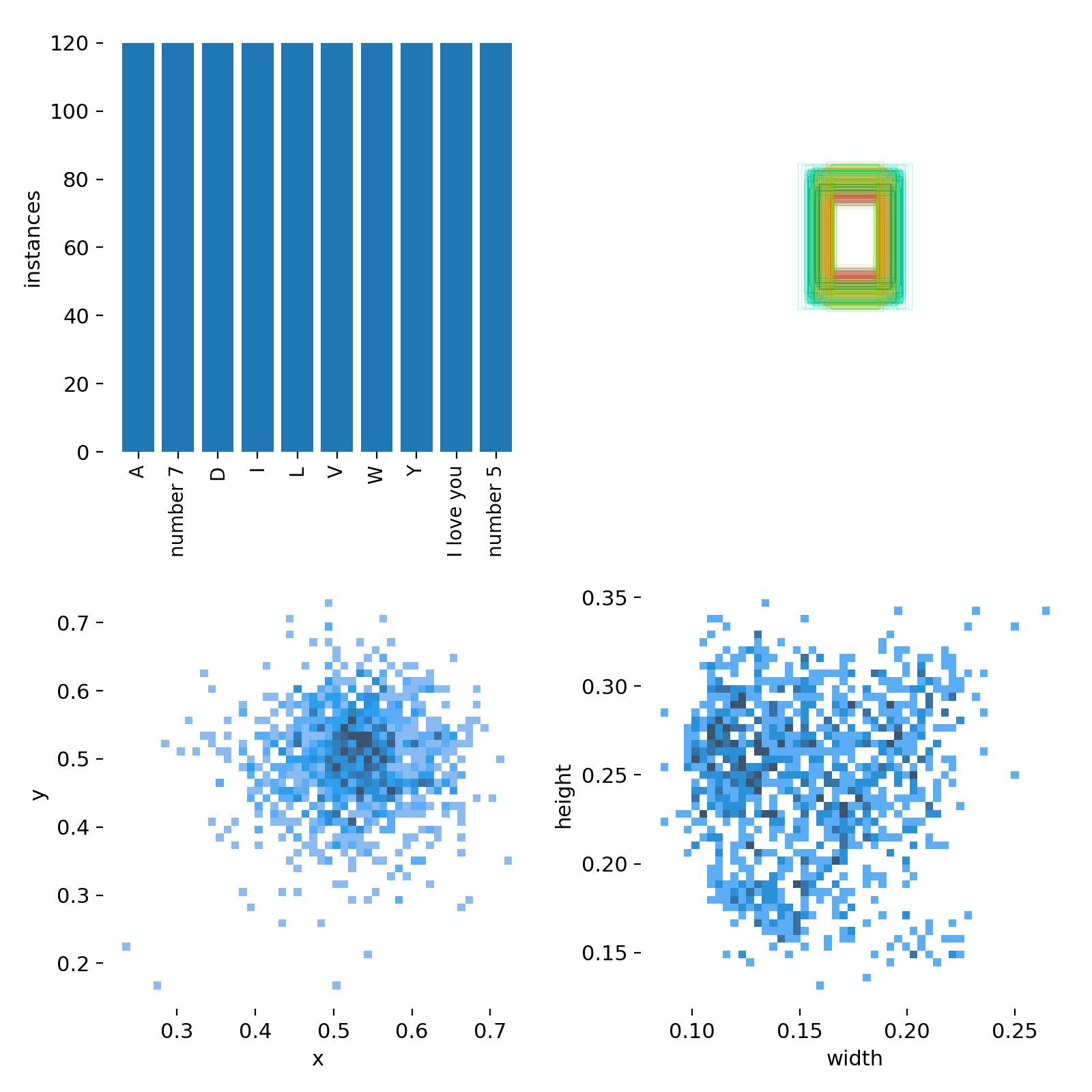
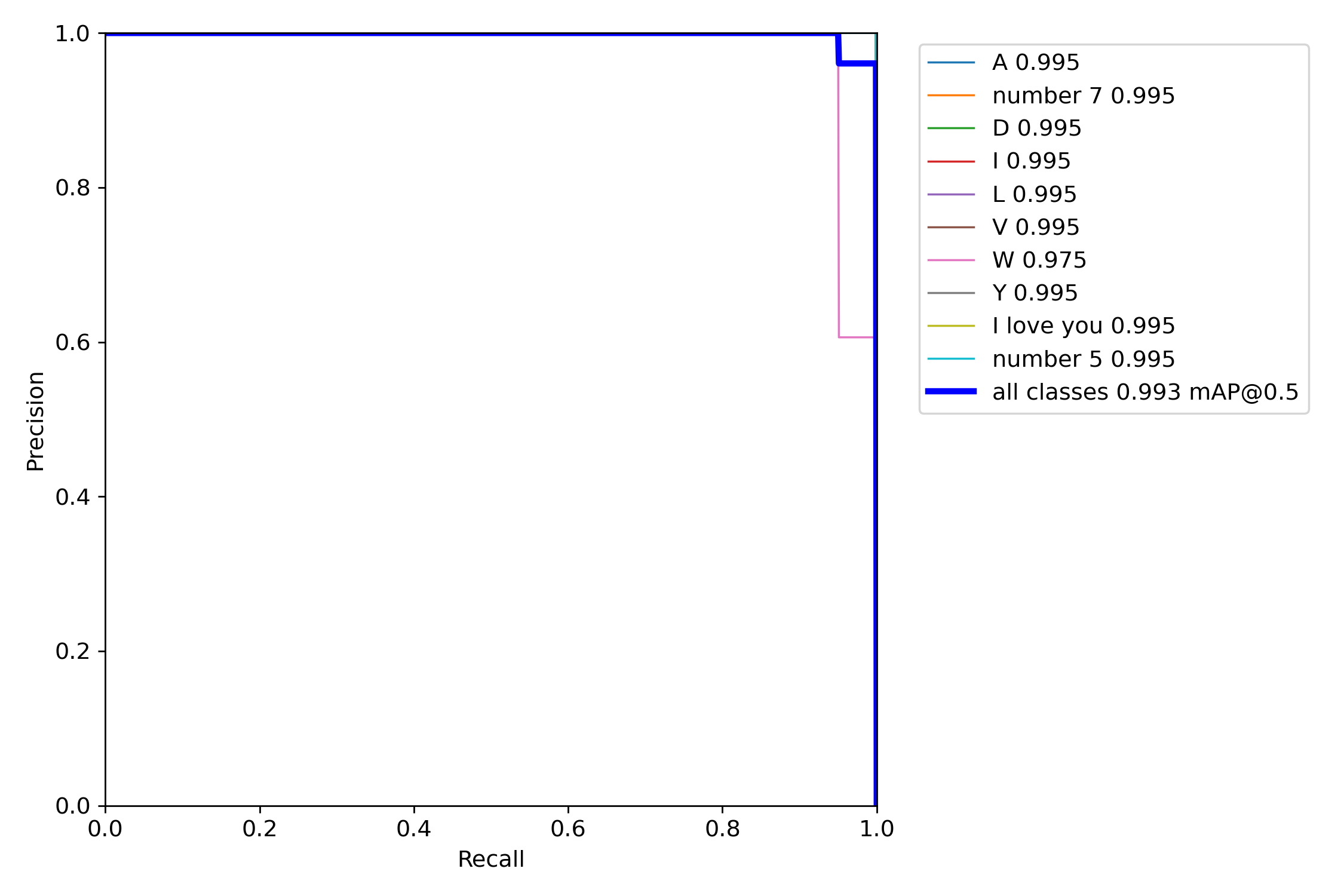
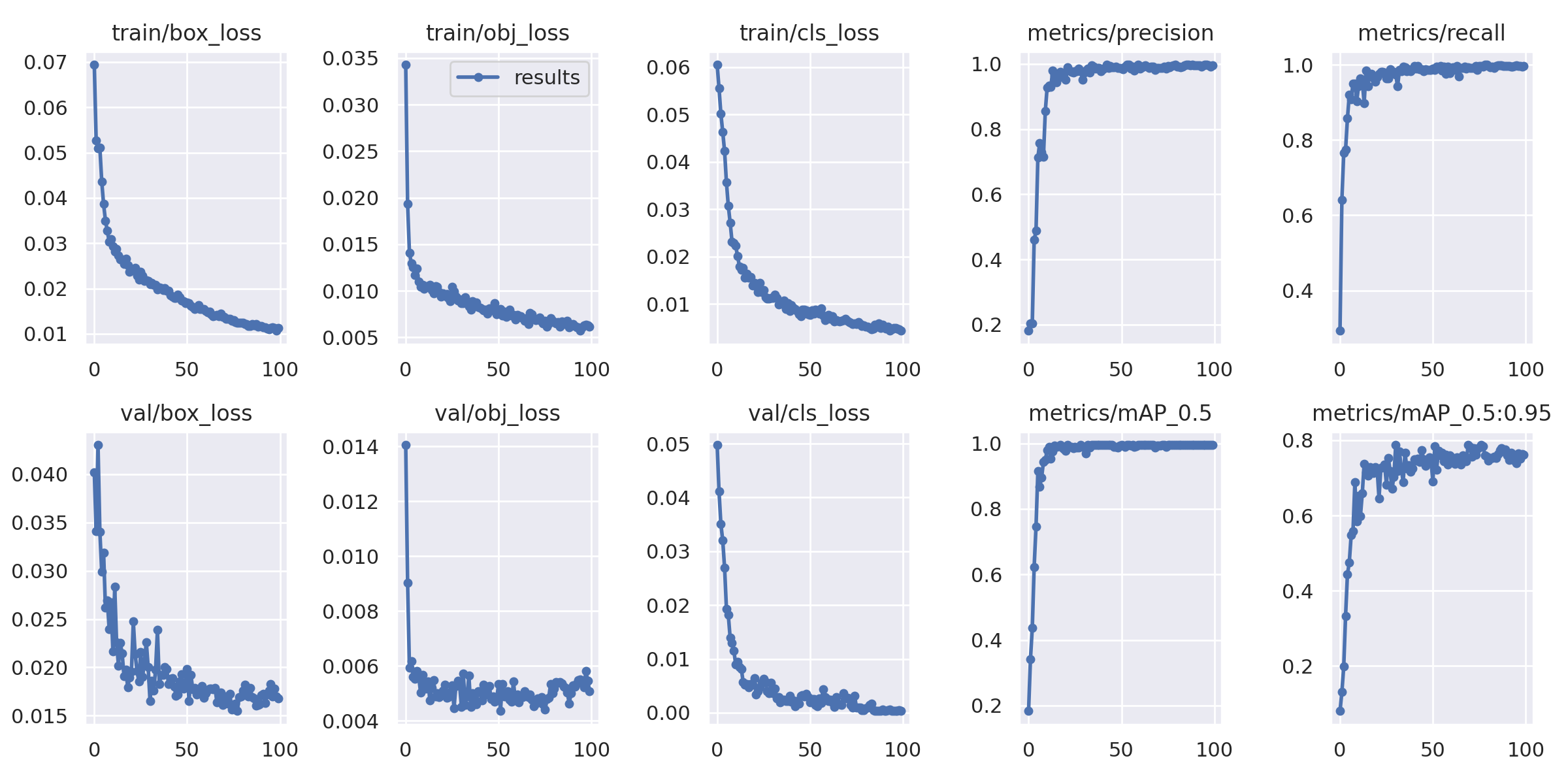
训练结果展示
注意事项:
(1)注意:虚拟产品一经售出概不退款!
(2)版权所有,未经许可禁止转载及用于商业用途!