(一次购买,持续更新,后续更新不再收费)
9号更新:更新第二问代码
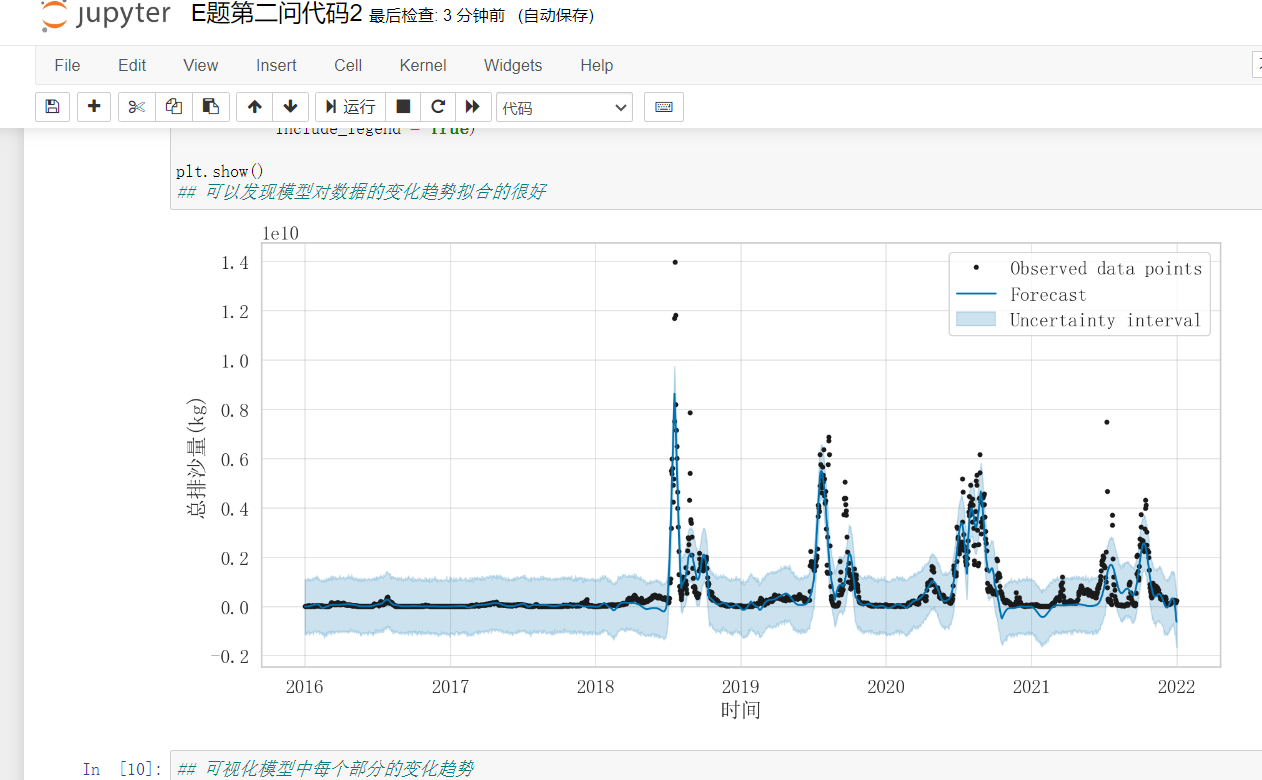
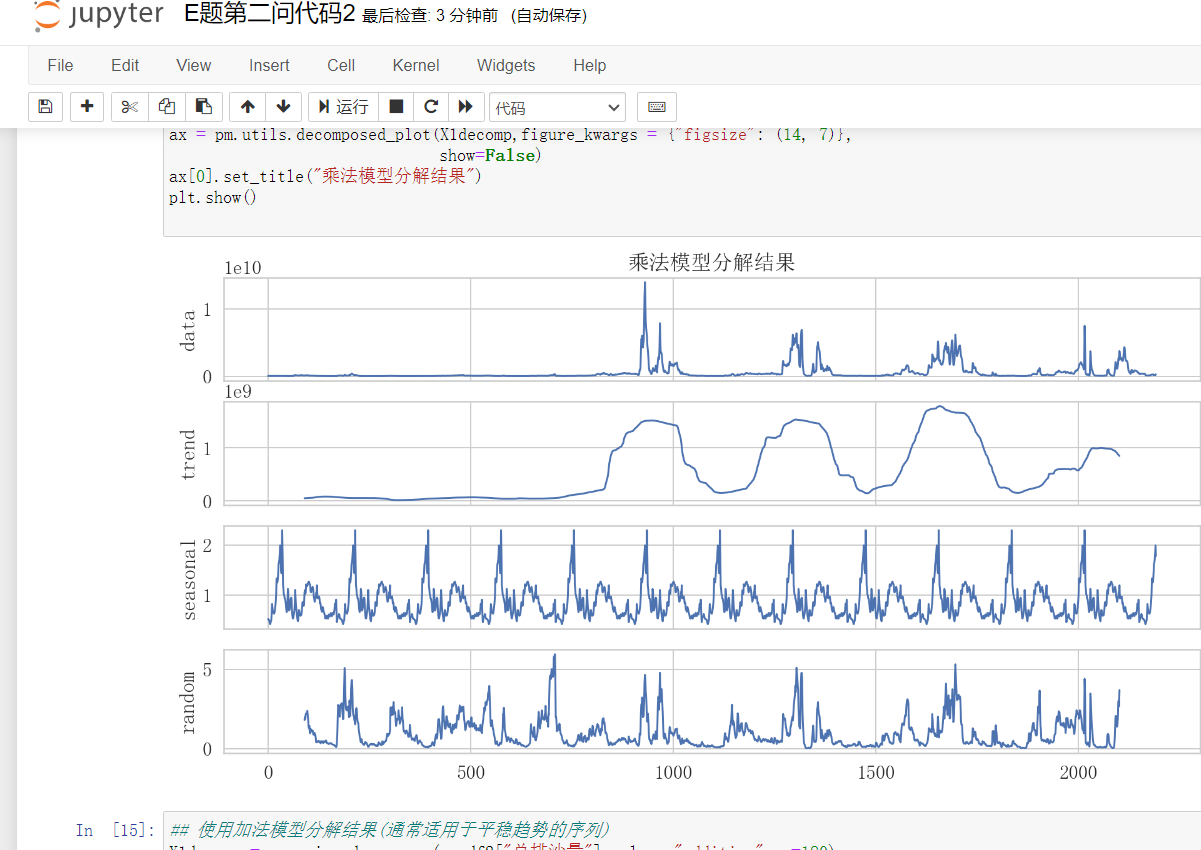

已更新2023数学建模国赛E题完整代码+处理结果+思路文档(30+页)
目标2: 并估算近6年该水文站的年总水流量和年总排沙量.... 2
目标1:解决方案,建立回归模型,分析他们之间的关系,预测含沙量.... 22
问题2:解决方案,(估算近6年该水文站的年总水流量和年总排沙量) 30



问题 1 研究该水文站黄河水的含沙量与时间、水位、水流量的关系,并估算近6年该水文站的年总水流量和年总排沙量。
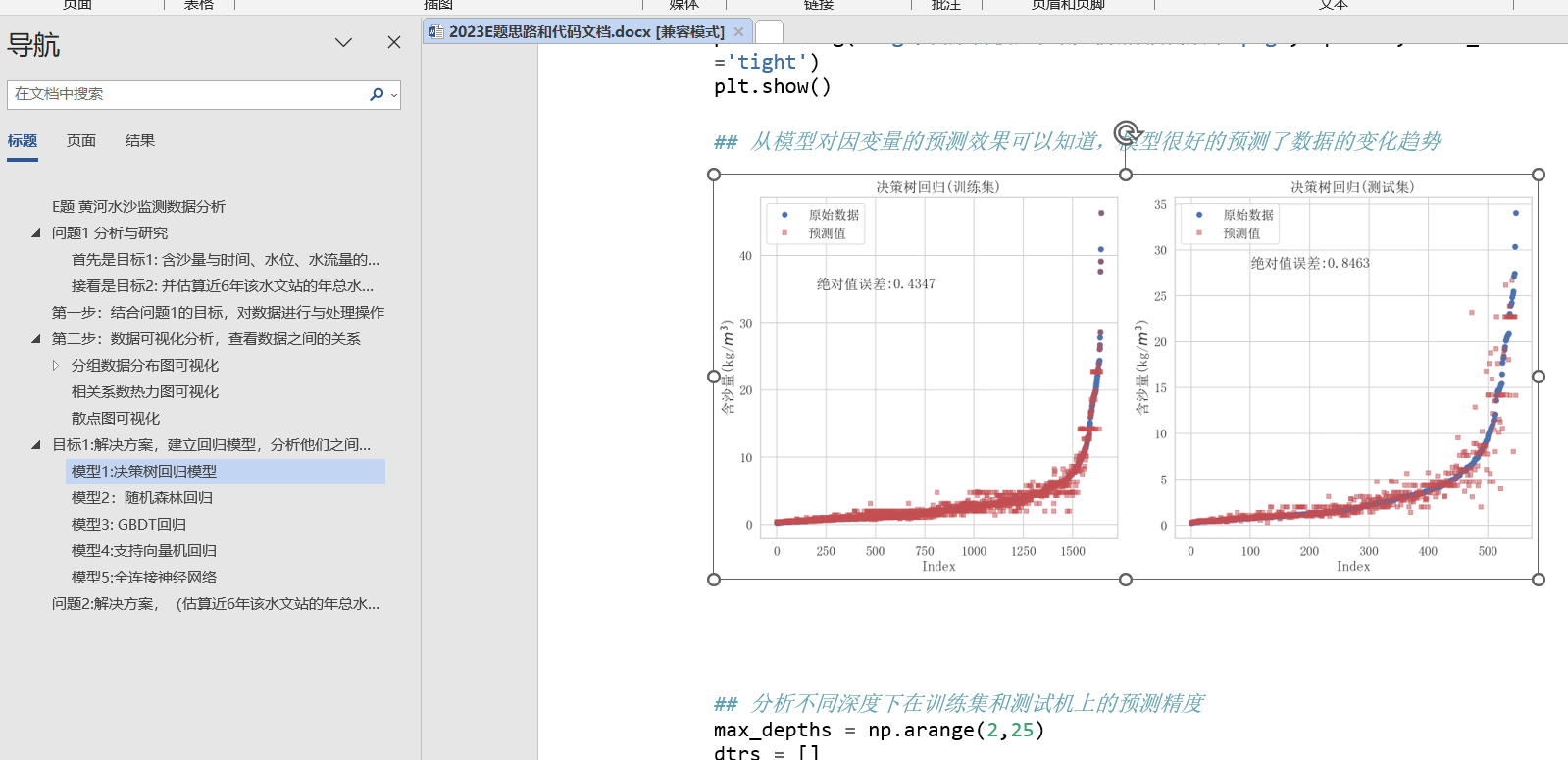
## 问题1 分析与研究
### 首先是目标1: 含沙量与时间、水位、水流量的关系
子问题:含沙量与时间的关系、含沙量与水位的关系、含沙量与水流量的关系(注意,可以分别分析两者之间的关系建模,也可以分析一个和多个变量之间关系的建模)
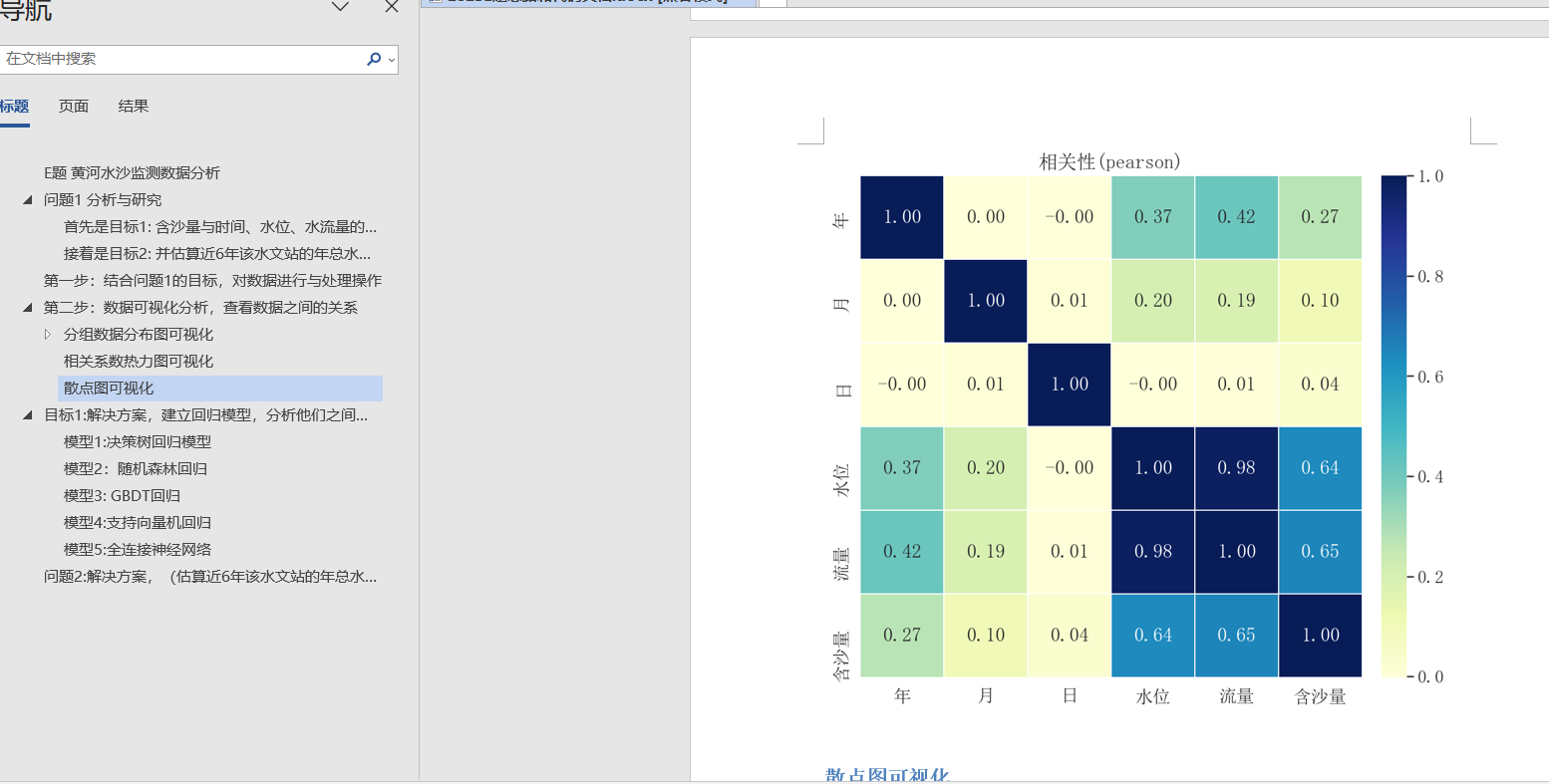
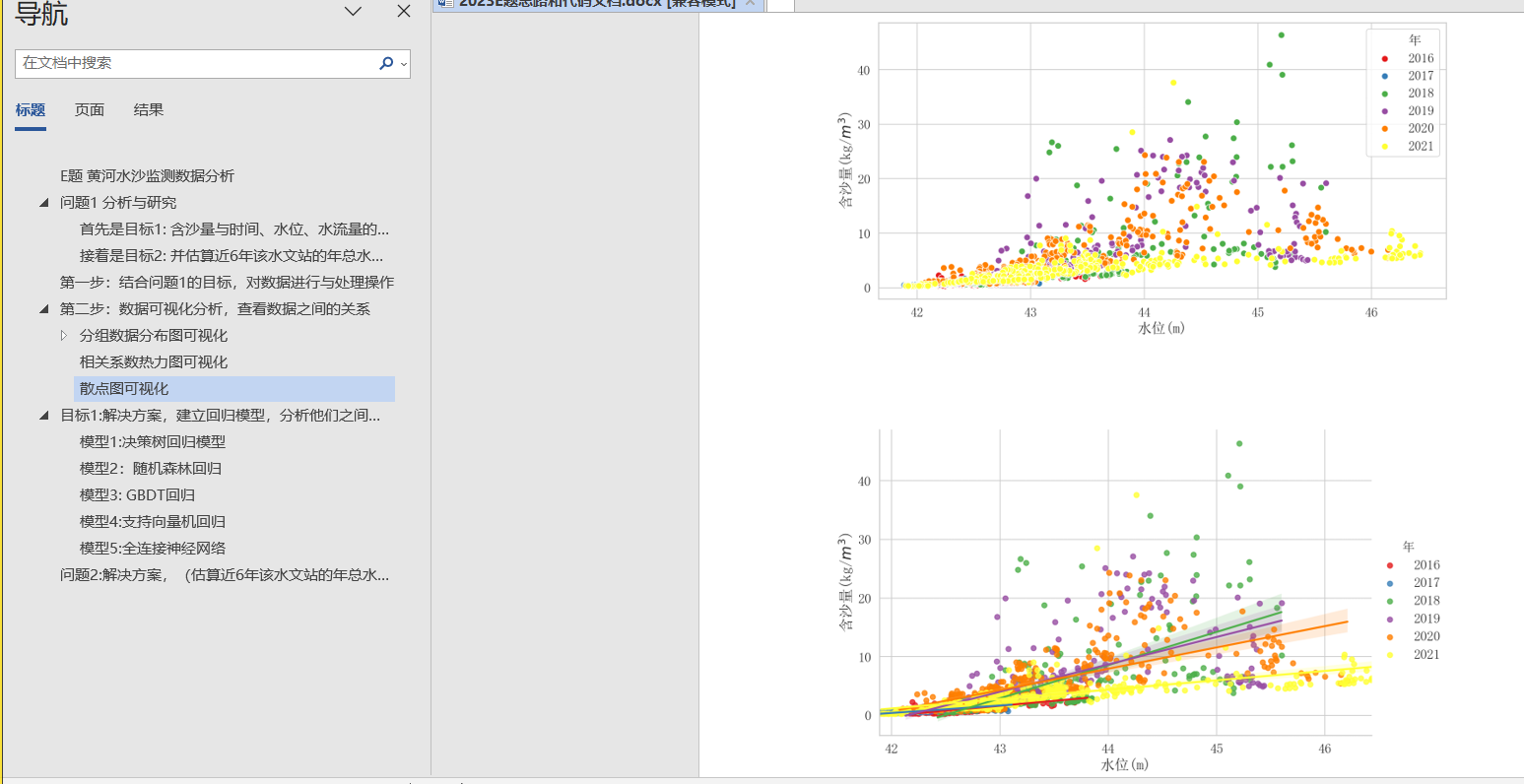
分析方式和步骤可以是:(1)数据清洗与整理,得到感兴趣的数据,利用可视化辅助分析之间的关系,利用相关性分析、回归分析等模型,建立数据之间的定量关系。
### 接着是目标2: 并估算近6年该水文站的年总水流量和年总排沙量
子问题:总排沙量理论上可以通过水流量和含沙量计算得到。因此重点还是分析年总水流量与含沙量之间的情况。
分析方式和步骤可以是:(1)数据清洗与整理,得到感兴趣的数据,利用可视化辅助分析之间的关系,通过相应的计算,获取目标数据。
第一步:结合问题1的目标,对数据进行与处理操作
结合附件1中给出的数据特点,我们将提供的的数据量计精确到以天为单位的精度。
## 数据读取
dfq1 = pd.read_excel("附件1问题1预处理数据.xlsx",usecols=[1, 2,3,4,5,6,7],
parse_dates=[6])
dfq1 = dfq1.iloc[0:-2,:]
dfq1[["年","月","日"]] = dfq1[["年","月","日"]].astype("int32")
dfq1
## 水位 流量 含沙量,均为当天数据的平均值
.dataframe tbody tr th:only-of-type { vertical-align: middle; }body>
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
年 月 日 水位 流量 含沙量 日期 0 2016 1 1 42.801429 363.428571 0.804286 2016-01-01 1 2016 1 2 42.775714 348.428571 0.827429 2016-01-02 2 2016 1 3 42.746667 331.333333 0.728000 2016-01-03 3 2016 1 4 42.718571 315.000000 0.657000 2016-01-04 4 2016 1 5 42.741429 328.571429 0.681000 2016-01-05 ... ... ... ... ... ... ... ... 2187 2021 12 27 43.146667 1176.666667 1.810000 2021-12-27 2188 2021 12 28 43.101667 1123.333333 1.810000 2021-12-28 2189 2021 12 29 43.090000 1105.000000 1.810000 2021-12-29 2190 2021 12 30 43.086667 1096.666667 2.683333 2021-12-30 2191 2021 12 31 43.081667 1091.666667 2.633333 2021-12-31
dfq1.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2192 entries, 0 to 2191
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 年 2192 non-null int32
1 月 2192 non-null int32
2 日 2192 non-null int32
3 水位 2192 non-null float64
4 流量 2192 non-null float64
5 含沙量 2192 non-null float64
6 日期 2192 non-null datetime64[ns]
dtypes: datetime64[ns](1), float64(3), int32(3)
memory usage: 94.3 KB
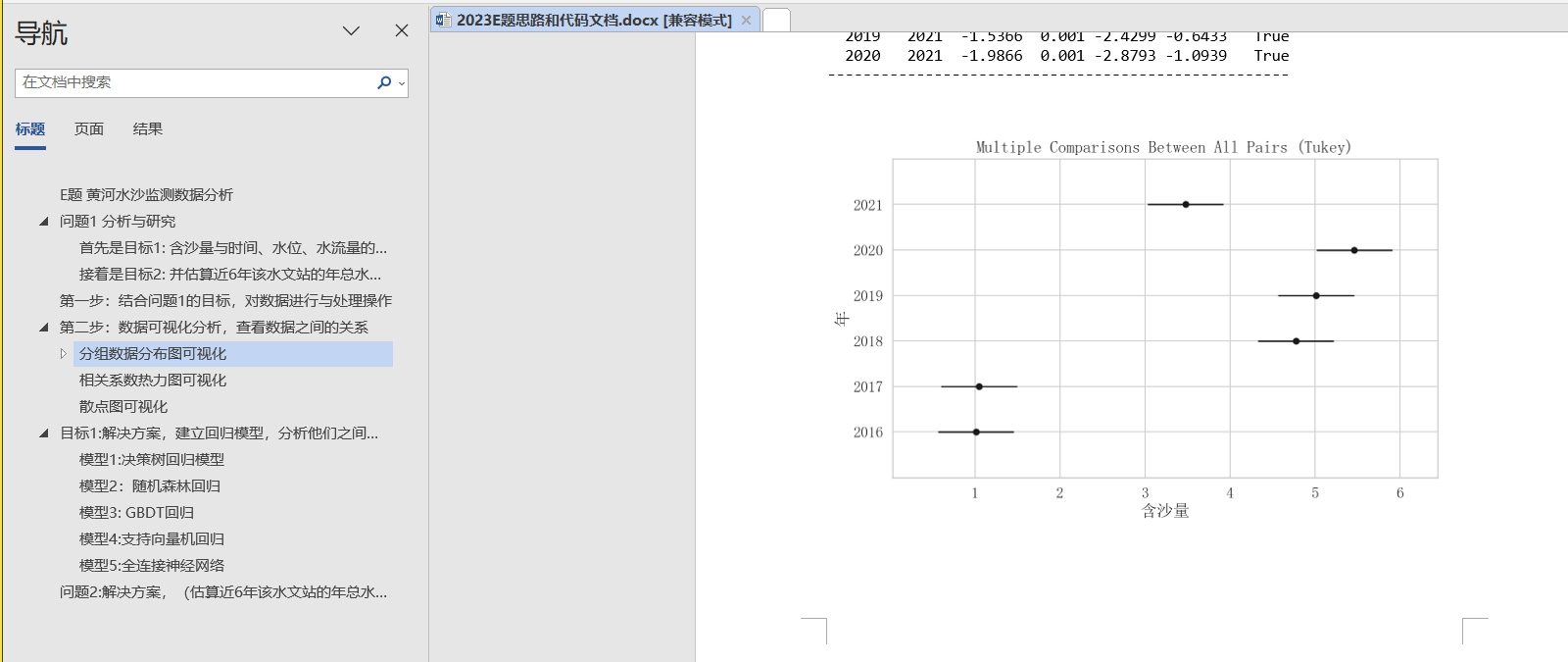
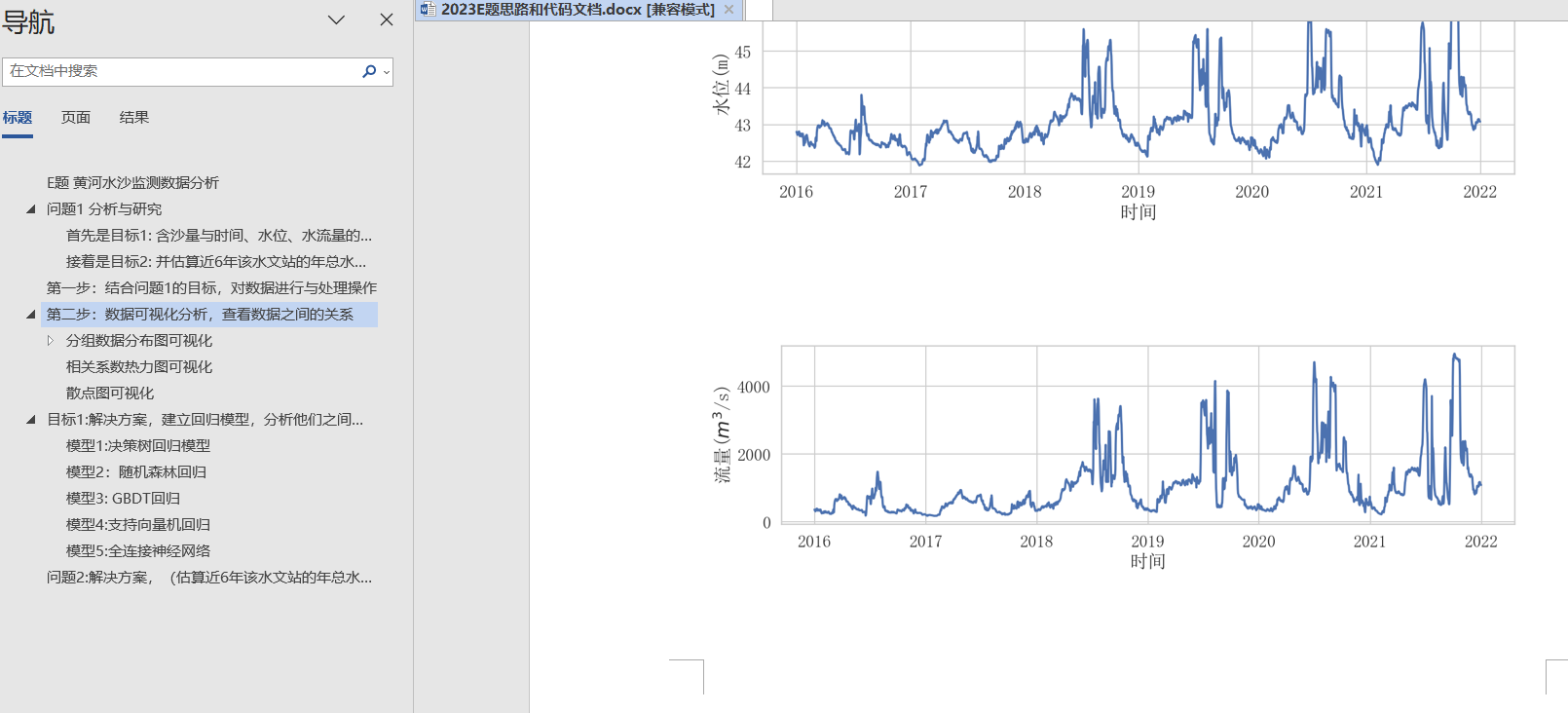
第二步:数据可视化分析,查看数据之间的关系
## 根据时间变量变化的数据散点图可视化
## 水位的变化情况
plt.figure(figsize=(12,3))
p = sns.lineplot(data=dfq1, x="日期", y="水位",lw = 2)
plt.xlabel("时间")
plt.ylabel("水位(m)")
plt.title("")
plt.savefig('figs/水位的变化情况.png', dpi=300, bbox_inches='tight')
plt.show()
## 流量的变化情况
plt.figure(figsize=(12,3))
p = sns.lineplot(data=dfq1, x="日期", y="流量",lw = 2)
plt.xlabel("时间")
plt.ylabel("流量("+"$m^3$"+"/s)")
plt.title("")
plt.savefig('figs/流量的变化情况.png', dpi=300, bbox_inches='tight')
plt.show()
## 含沙量的变化情况
plt.figure(figsize=(12,3))
p = sns.lineplot(data=dfq1, x="日期", y="含沙量",lw = 2)
plt.xlabel("时间")
plt.ylabel("含沙量(kg/"+"$m^3$"+")")
plt.title("")
plt.savefig('figs/含沙量的变化情况.png',dpi=300,bbox_inches='tight')
plt.show()