哈喽大家好,AI应用视界工作室 致力于深入探索人工智能算法与应用开发的交互,涵盖目标分类、检测、分割、跟踪、人脸识别等关键领域,以及系统架构的创新设计与实现。我们的目标是为广大人工智能研究者提供一个丰富、权威的参考资源,同时也期待与您共同交流,推动人工智能技术的进步。如有相关算法交流学习和技术需求,请关注公众号【AI应用视界】/微信【Ai_designer666】可与我们取得联系。

一、系统概述和展示
1.1 摘要
基于YOLOV8/V11的监控视角下车牌实时检测系统通过先进的图像处理和人工智能技术,实时检测室内场景下车牌目标的情况,保障车牌检测效果。本文基于YOLOv11算法框架,通过4348张监控场景的训练图片(支持黄牌、蓝牌、绿牌、黑牌、白牌车牌)(其中3478张训练集,870张验证集),训练出一个可用于检测监控场景下车牌的有效模型。此外,为更好地展示算法效果,基于此模型开发了一款带GUI界面的基于YOLOV8/V11的监控视角下车牌实时检测系统,可用于实时检测车牌情况,以及时告警。该系统是基于Python和Pyside6开发,并支持以下功能特性:
- 系统背景和系统标题更换
- 模型权重导入和初始化
- 检测置信度和IOU调节
- 检测目标的信息展示
- 检测用时的统计展示
- 检测结果和原图结果更换
- 图片导入、检测、导出、结果展示
- 视频导入、检测、暂停、导出、结果展示
- 摄像头导入、检测、结果展示
初始化界面
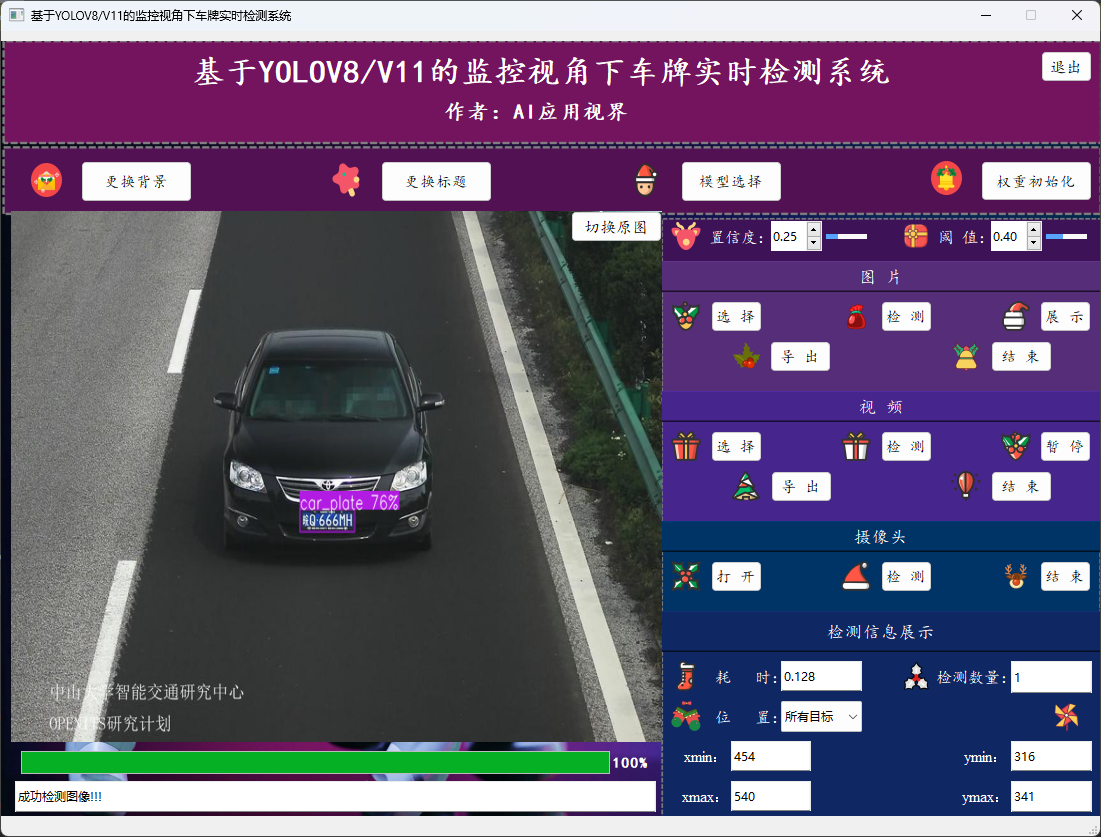
检测界面
下面将对部分核心功能进行简单展示
(1)更换背景和标题演示
- 用户可通过点击更换背景,选择想要更换背景的图片,系统便会自动更换壁纸;
- 用户可通过点击更换标题,然后在文字输入栏中输入想要更换的标题,然后点击确定即可更改系统标题。
Video Player is loading.
Current Time 0:00
Duration 0:07
Remaining Time -0:07
Beginning of dialog window. Escape will cancel and close the window.
End of dialog window.
Video Player is loading.
Current Time 0:00
Duration 0:07
Remaining Time -0:07
Beginning of dialog window. Escape will cancel and close the window.
End of dialog window.
(2)模型选择和初始化演示
- 用户可通过点击模型选择,选择想要加载的系统模型;然后点击权重初始化即可完成模型的准备工作。
Video Player is loading.
Current Time 0:00
Duration 0:05
Remaining Time -0:05
Beginning of dialog window. Escape will cancel and close the window.
End of dialog window.
Video Player is loading.
Current Time 0:00
Duration 0:05
Remaining Time -0:05
Beginning of dialog window. Escape will cancel and close the window.
End of dialog window.
(3)图片检测演示
- 用户可通过点击图片中的选择,选择想要加载的图片文件;然后点击检测,等待弹出图片检测完成的提示 框,再点击展示即可将对应的目标框展示再原始图片上,完成展示后,用户可手动点击导出将图片保存到指定位置,最后点击结束关闭图片展示区域。
- 相关展示信息,如耗时、检测目标数量、位置信息等可在检测信息一栏查看。
Video Player is loading.
Current Time 0:00
Duration 0:20
Remaining Time -0:20
Beginning of dialog window. Escape will cancel and close the window.
End of dialog window.
Video Player is loading.
Current Time 0:00
Duration 0:20
Remaining Time -0:20
Beginning of dialog window. Escape will cancel and close the window.
End of dialog window.
(4)视频和摄像头检测演示
- 用户可通过点击图片中的选择,选择想要加载的图片文件;然后点击检测,等待弹出图片检测完成的提示框,再点击展示即可将对应的目标框展示再原始图片上,完成展示后,用户可手动点击导出将图片保存到指定位置,最后点击结束关闭图片展示区域。
- 相关展示信息,如耗时、检测目标数量、位置信息等可在检测信息一栏查看。
- 对于摄像头检测模块和视频检测模块原理类似(摄像头检测会自动调用电脑摄像头,也可修改并支持RTSP流)。
Video Player is loading.
Current Time 0:00
Duration 0:21
Remaining Time -0:21
Beginning of dialog window. Escape will cancel and close the window.
End of dialog window.
Video Player is loading.
Current Time 0:00
Duration 0:21
Remaining Time -0:21
Beginning of dialog window. Escape will cancel and close the window.
End of dialog window.
二、一站式使用教程
>conda create -n YOLOv11_My python=3.8.10
>conda activate YOLOv11_My
>pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https:
>pip install ultralytics huggingface-hub -i https:
>pip install pyside6==6.6.1 -i https:
>python base_camera.py
三、模型训练、评估、推理
3.1 数据集介绍
本文使用的是监控场景车牌检测数据集(作者通过多段真实视频抽帧以及网上获取的相关车牌图片并标注) ,按照一类目标【车牌】进行定位与分类标注并转换成 YOLO格式 ,并对此数据集进行了划分,可直接用于训练 。此数据集共包含4348张监控场景的训练图片 ,本文实验使用的训练集3478张,验证集870张。部分数据集及标注可视化信息如下:

图片数据集的存放格式如下,在项目目录中新建datasets目录,同时将YOLO格式数据集images和labels放入指定目录下,然后修改dataset_cfg下的data.yaml文件中的path路径指向datasets文件夹(绝对路径)。
datasets:
----images
--------train(此文件夹全是图片)
--------val(此文件夹全是图片)
----labels
--------train(此文件夹全是txt文件)
--------val(此文件夹全是txt文件)
3.2 模型训练
数据准备完成后,通过调用detection_train.py文件进行模型训练,data参数用于加载数据集的配置文件,epochs参数用于调整训练的轮数,workers参数用于调整系统的并发能力,batch参数用于调整训练的批次大小【根据内存大小调整,最小为1】,代码如下:
from ultralytics import YOLO
import os
os.environ["GIT_PYTHON_REFRESH"] = "quiet"
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
if __name__ == '__main__':
model = YOLO('weights/yolov11s.pt')
result = model.train(data="data/data.yaml", epochs=100, workers=8, batch=16, imgsz=416, amp=False, device="0")
3.3 结果评估
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况,避免过拟合和欠拟合现象。YOLOv11 训练过程及结果文件保存在runs/det/目录下,我们可以在训练结束后进行查看,结果如下所示:
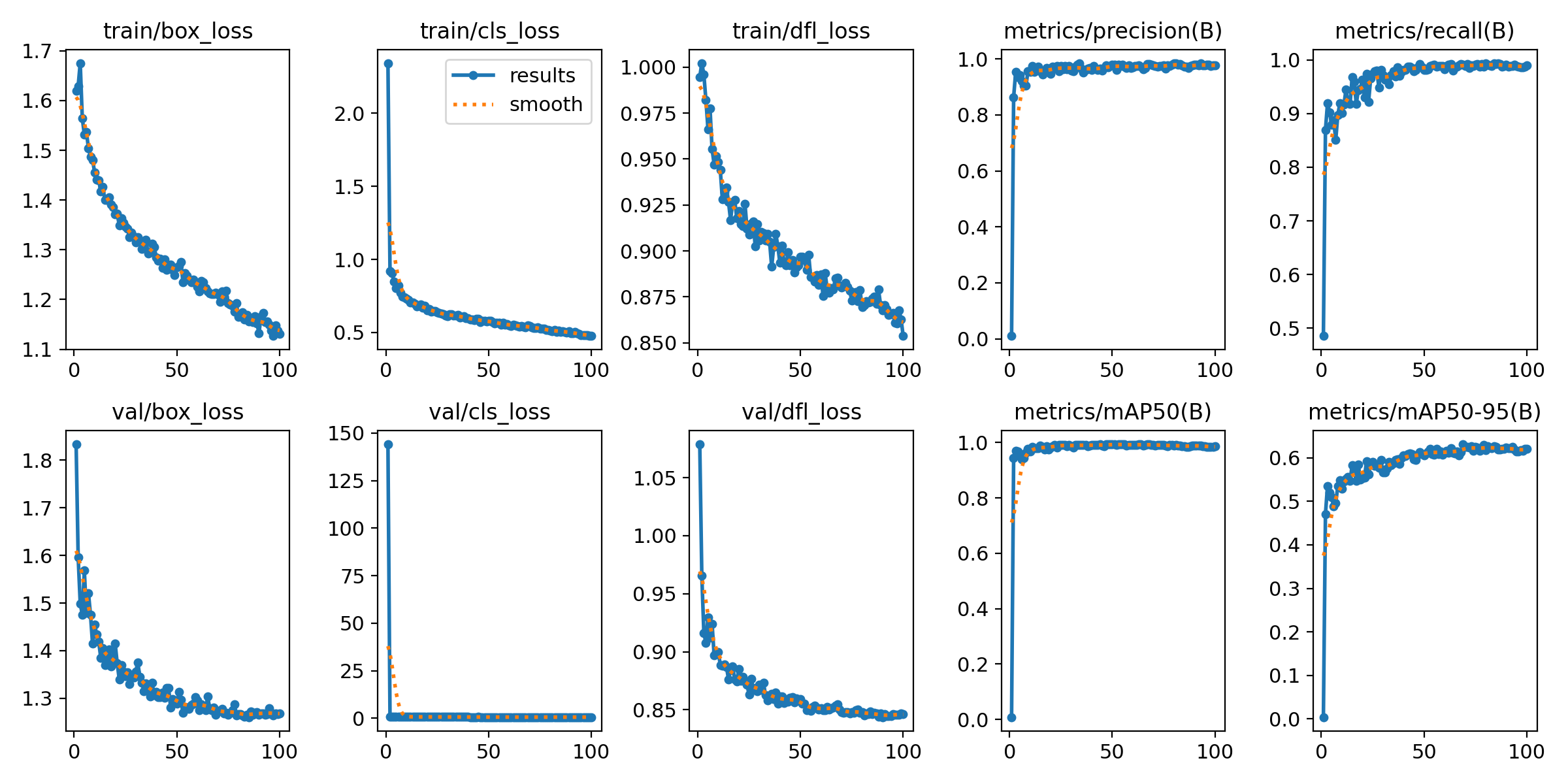
本文训练结果如下:
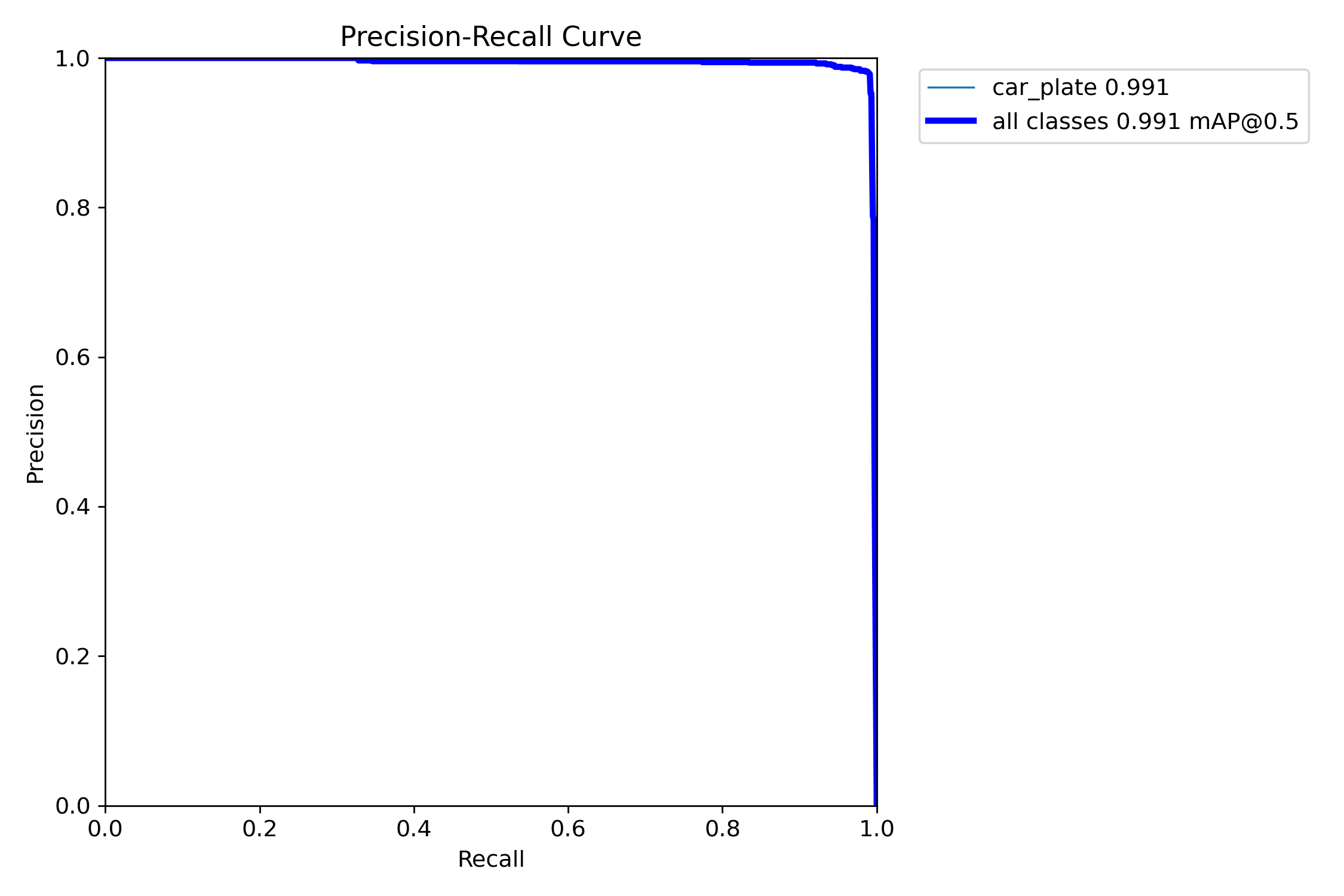
3.4 模型推理
模型训练结束后,我们可在runs/det/目录下可以得到一个最新且最佳的训练结果模型best.pt文件,在runs/det/train/weights目录下。我们可使用该文件进行后续的推理检测。
图片推理代码如下:
import os
from ultralytics import YOLOv10
current_path = os.path.dirname(os.path.realpath(__file__))
root_path = os.path.abspath(os.path.join(current_path, "../.."))+"/"
model = YOLOv10(root_path + 'runs/det/train/weights/best.pt')
if __name__ == '__main__':
model.predict(root_path + 'ultralytics/assets/test1.jpg', save=True, imgsz=416, conf=0.5)
图片推理结果如下

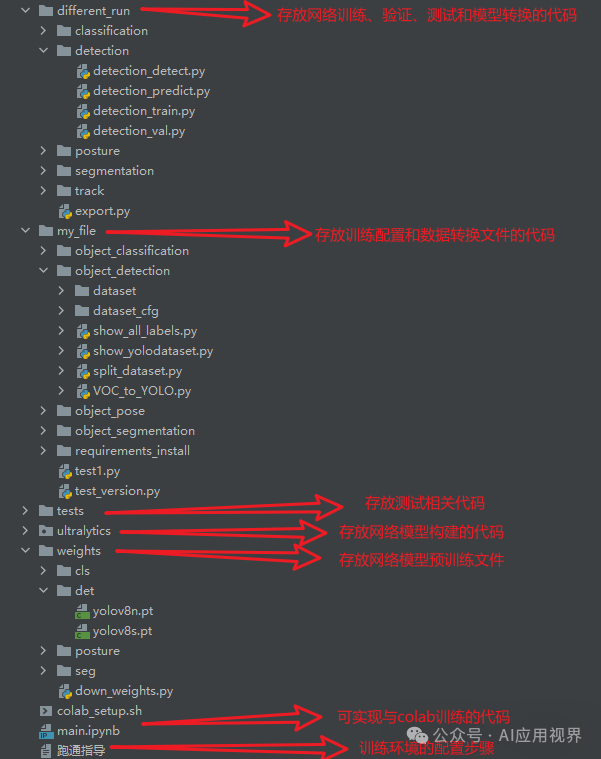
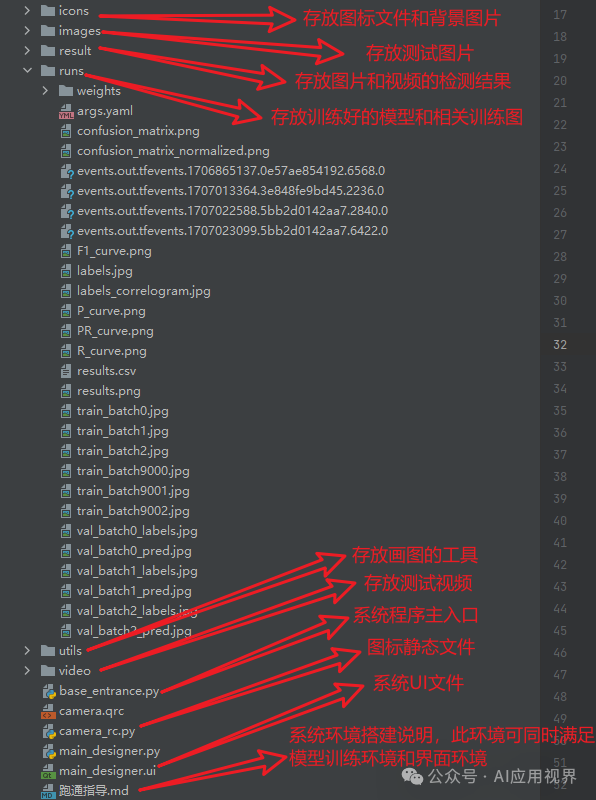
四、项目完整目录
本文涉及到的完整的程序文件:包括环境配置文档说明(训练和系统环境都适用)、模型训练源码、数据集、系统完整代码、系统UI文件、测试图片视频等。
模型训练代码如下:
系统完整代码如下:
五、项目总结
本文训练得到的车牌实时检测模型在数据集上的表现良好,泛化性能较强,检测能力较强。此外在此模型上开发了一款带GUI界面的基于YOLOV8/V11的监控视角下车牌实时检测系统,可用于实时检测获取车牌的告警情况。此处下单可获取模型训练完整代码、系统完整代码、完整的数据集和UI界面等,此外模型训练完整代码和系统部署完整代码都有对应的跑通指导手册!所有的文件均已打包上传,感兴趣的小伙伴可以自主下单获取,如有技术交流或者系统配置相关问题可联系我们,可远程提供部署支持。如有其他的项目需求也可以联系我们。
注意事项:
- 虚拟产品一经售出概不退款!
- 版权所有,未经许可禁止转载及用于商用化用途
- 该代码采用PyTorch和Pyside6等库开发,经过测试能成功运行,如有不清楚可查看训练代码和系统代码中的跑通指导文件,或者可联系我们协助解决