1. 项目背景
本系统旨在帮助用户更高效地管理和分析招聘信息,通过爬虫抓取招聘数据、可视化分析招聘市场情况,并提供薪资预测功能。项目采用 Django 框架开发,具有以下主要功能:
- 从招聘网站抓取招聘数据。
- 存储与管理招聘信息。
- 提供基于数据的可视化分析。
- 实现简单的薪资预测功能。
2. 系统架构设计
- 后端框架:Django + SQLite
- 前端技术:HTML、CSS、JavaScript(通过 Django 模板引擎渲染)
- 爬虫工具:Python 自定义爬虫
- 核心模块:
- 数据爬取模块
- 数据管理模块(数据库模型)
- 数据可视化模块
- 薪资预测模块
3. 数据库设计
文件位置:models.py
项目数据库采用 Django ORM,数据模型如下:
- Job(职位信息表):
title:职位名称company:公司名称location:工作地点salary:薪资信息description:职位描述post_date:发布日期- Company(公司信息表):
name:公司名称industry:所属行业size:公司规模
模型中包含数据字段、关系映射及方法,用于存储和管理爬取的招聘信息。
4. 爬虫功能
文件位置:spider.py
爬虫功能主要完成以下任务:
- 访问招聘网站(如 51Job)。
- 解析 HTML 页面,提取职位信息,包括职位名称、公司名称、薪资等。
- 数据清洗与存储:
- 利用
stopwords.txt文件剔除无效信息。 - 数据存入 SQLite 数据库,便于后续处理。
关键代码示例:
import requests
from bs4 import BeautifulSoup
from .models import Job
def fetch_jobs():
url = "https://example.com/jobs"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for job_element in soup.find_all('job'):
title = job_element.find('title').text
company = job_element.find('company').text
salary = job_element.find('salary').text
# 保存到数据库
Job.objects.create(title=title, company=company, salary=salary)
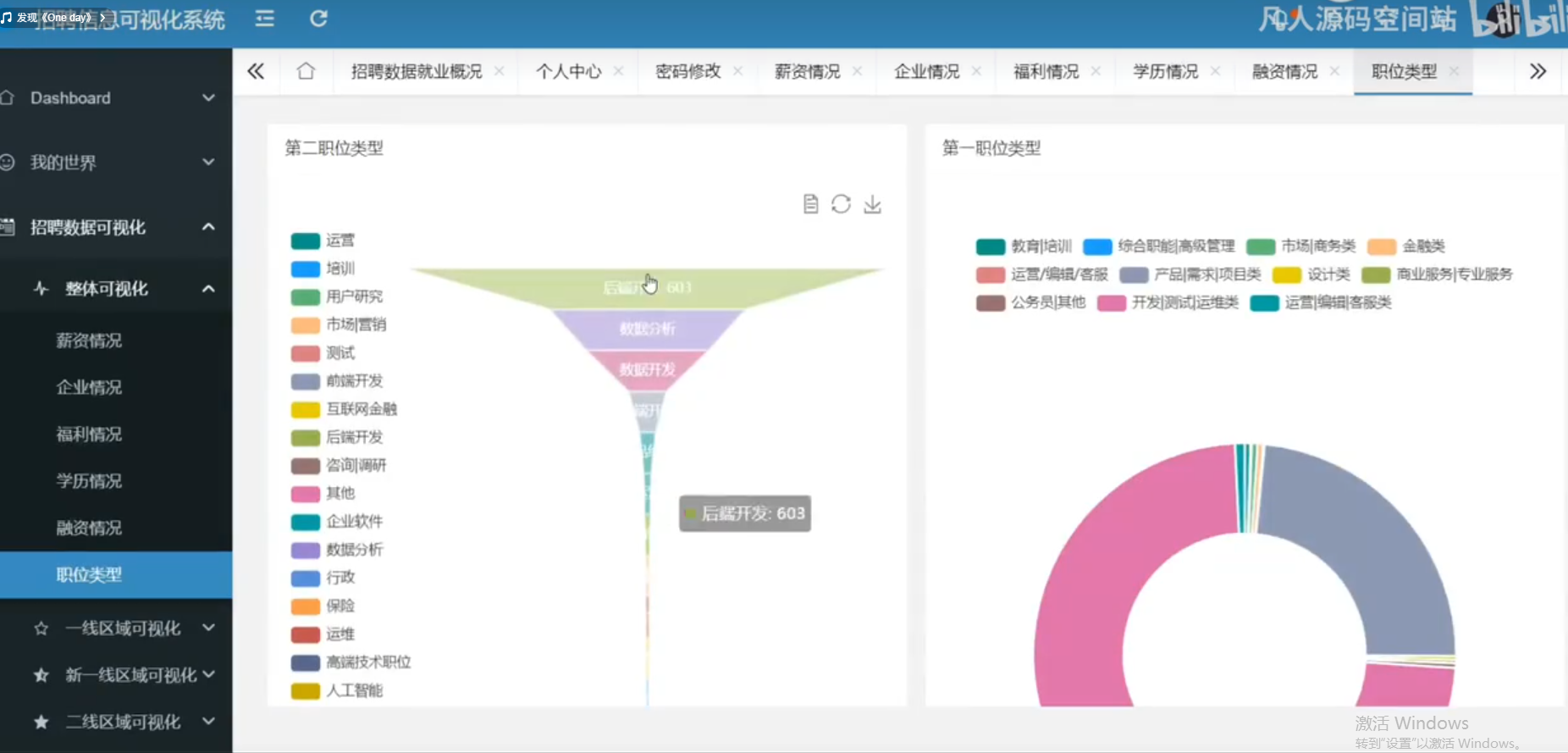
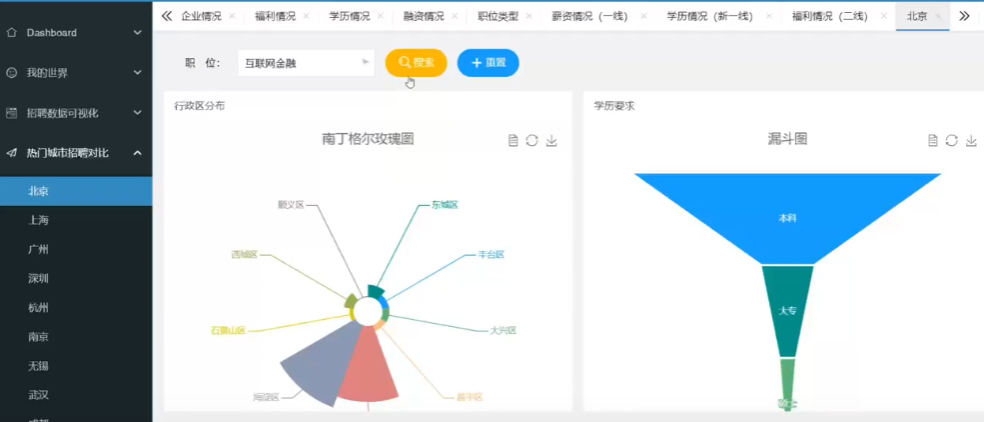
5. 数据可视化功能
文件位置:views.py
系统提供多种数据可视化方式:
- 职位数量统计图:显示不同岗位的招聘数量分布。
- 薪资分布图:绘制各职位薪资分布的柱状图或箱线图。
- 公司规模分析:展示公司规模与职位数量的关系。
通过 Matplotlib 或其他可视化库生成图片,并渲染到模板页面。
关键视图代码示例:
from django.shortcuts import render
import matplotlib.pyplot as plt
from .models import Job
def salary_distribution(request):
salaries = [job.salary for job in Job.objects.all()]
plt.hist(salaries, bins=10)
plt.savefig('static/images/salary_dist.png')
return render(request, 'visualization.html', {'image_path': '/static/images/salary_dist.png'})
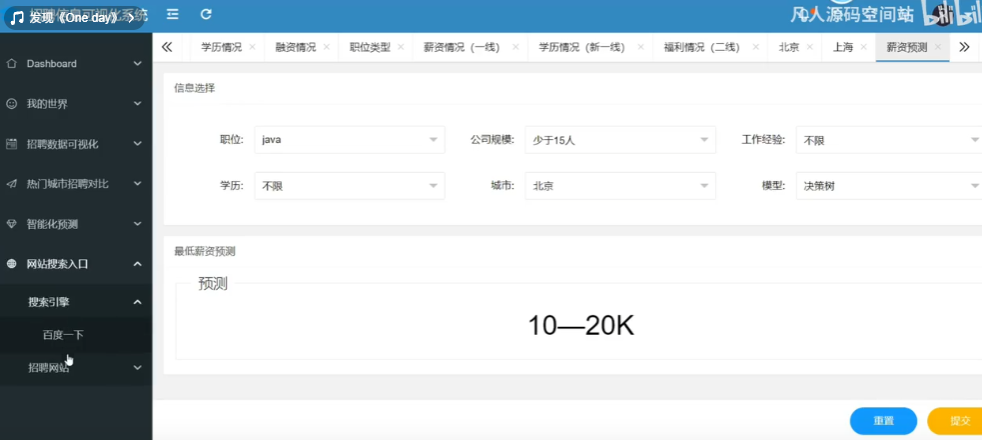
6. 薪资预测功能
实现思路:
- 利用招聘数据训练简单的机器学习模型(如线性回归)。
- 使用 scikit-learn 库实现,预测给定职位的预期薪资范围。
关键代码示例:
from sklearn.linear_model import LinearRegression
from .models import Job
def train_salary_model():
jobs = Job.objects.all()
X = [[job.experience] for job in jobs] # 工作经验
y = [job.salary for job in jobs]
model = LinearRegression().fit(X, y)
return model
7. 前后端交互
文件位置:templates/ 和 static/
- 模板文件使用 Django 模板引擎编写(如 HTML 表单)。
- 静态文件夹存放 CSS 和 JavaScript 文件,提升用户交互体验。
8. 配置说明
文件位置:settings.py
- 数据库配置:使用 SQLite。
- 静态文件路径:
static/ - 已配置爬虫相关参数及应用路由。
9. 项目部署与运行
- 依赖安装:
pip install -r requirements.txt
- 数据库迁移:
python manage.py makemigrations python manage.py migrate
- 运行服务器:
python manage.py runserver
10. 总结与安全性
- 系统通过模块化设计,功能清晰,易于扩展。
- 数据可视化与薪资预测功能为用户提供了深入洞察。
- 后续可优化爬虫逻辑,增加多网站支持,并加强数据安全
具体项目演示视频:
【S2023016大数据专业毕设之基于python爬虫的招聘信息可视化+薪资预测管理系统】 https://www.bilibili.com/video/BV1tW4y1p7cX/?share_source=copy_web&vd_source=3d18b0a7b9486f50fe7f4dea4c24e2a4