注意:此内容是为发论文或者发专利以及著作权的同学提供的idea和实现代码,购买它您可以迅速达到一个毕业要求或者获得一个评优评先资格。
在YOLOv5的目标检测算法中我们认为它是一个多标签的模型,因为它支持一种到无穷多种物体的标注和识别,但是这是说的单图多类别,当我们深入到一些项目的时候会发现,我们所说的多标签的意思是:单框多标签 也就是,我给你一张图,其中一个框检测出来了它是一个杯子,同时我们希望它告诉我们是什么颜色的杯子。
在YOLOv5的原始代码中,它的实现是基于一种one-hot的思想去做的,是不可能实现单框多标签分类任务的。为此我们提出了一种新的思路以达到这种效果,为此我们建立了一个基准数据集去训练和测试我们的模型,事实上它们的效果表现是非常合理的,为此我们愿意将该idea和实现代码进行出售(注意:我们不会使用它去发表任何公开的论文或者文章,而且我们保证该idea和实现代码只售出一份 希望帮助一个同学去评优评先甚至是一篇水区的论文)。

我们创建的基准数据集是:数字1-3以及对应它们的数字。
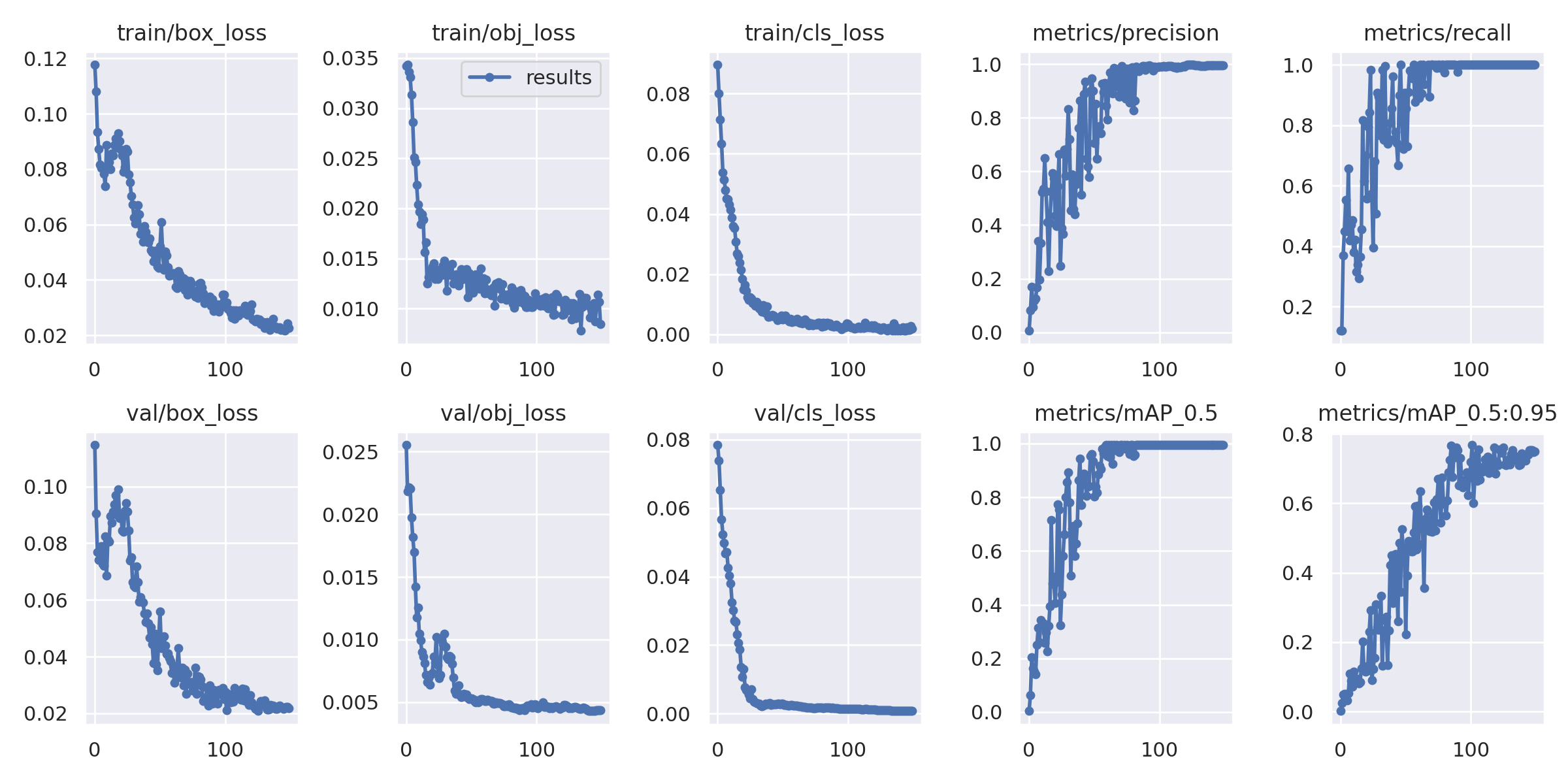
迭代150次训练的效果。

train_batch

识别效果:数字1且为红色(这是仅仅是标签遮挡了,后期可以处理)

识别效果:数字2且为红色