温馨提示:集成学习模型精度不一定最佳,预测结果可能居中,适合具有一定场景的预测。
一、研究背景
该代码研究的是集成学习中的Stacking方法在回归预测任务中的应用。Stacking是一种通过组合多个不同基础模型(基学习器)的预测结果,再通过一个元学习器进行最终预测的集成策略,旨在提高模型的泛化能力和预测精度。
二、主要功能
代码实现了一个完整的Stacking集成回归预测系统,包括:
数据预处理:读取、标准化、划分数据集;
基学习器训练:
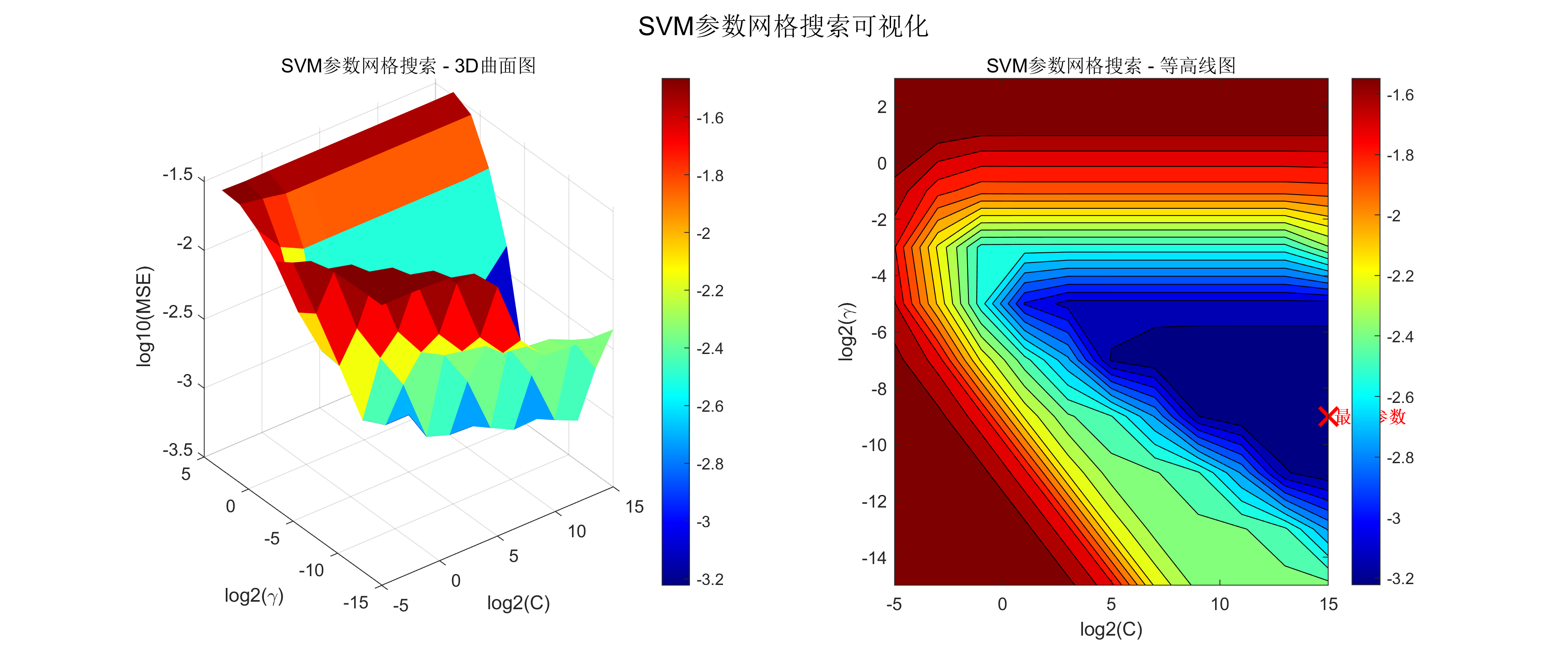
- SVM(支持向量机)回归模型,采用网格搜索优化参数;
- BP神经网络回归模型;
元学习器训练:使用随机森林(RF)对基学习器的输出进行融合;
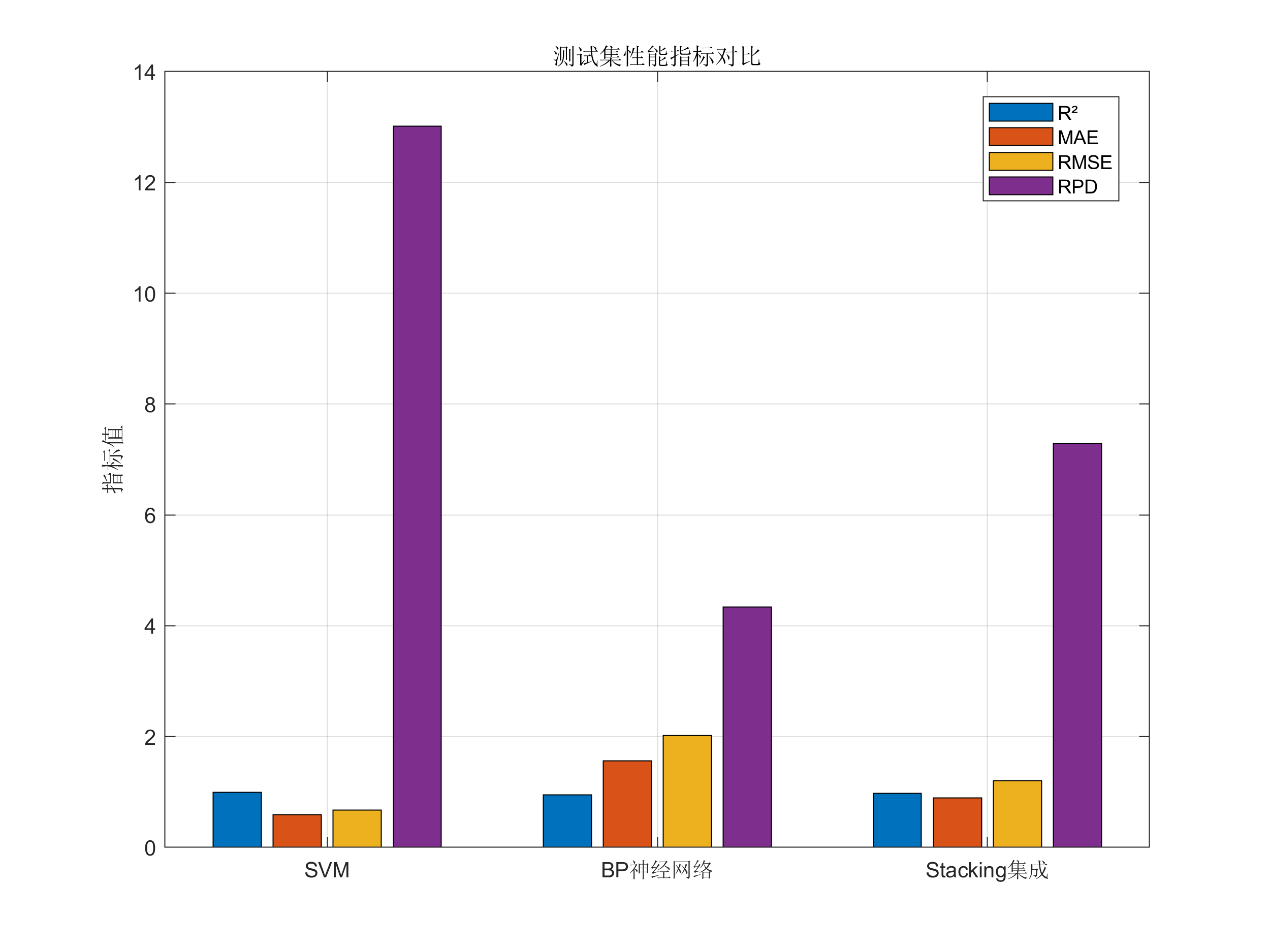
模型评估:计算R²、MAE、MSE、RMSE、RPD等指标;
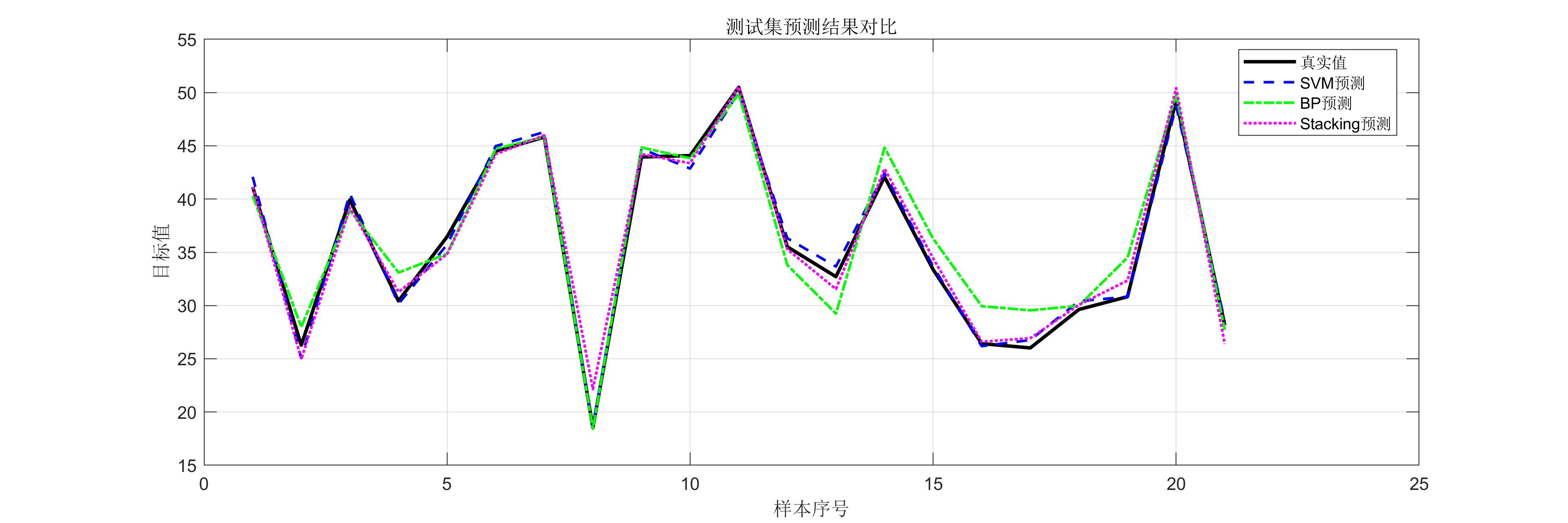
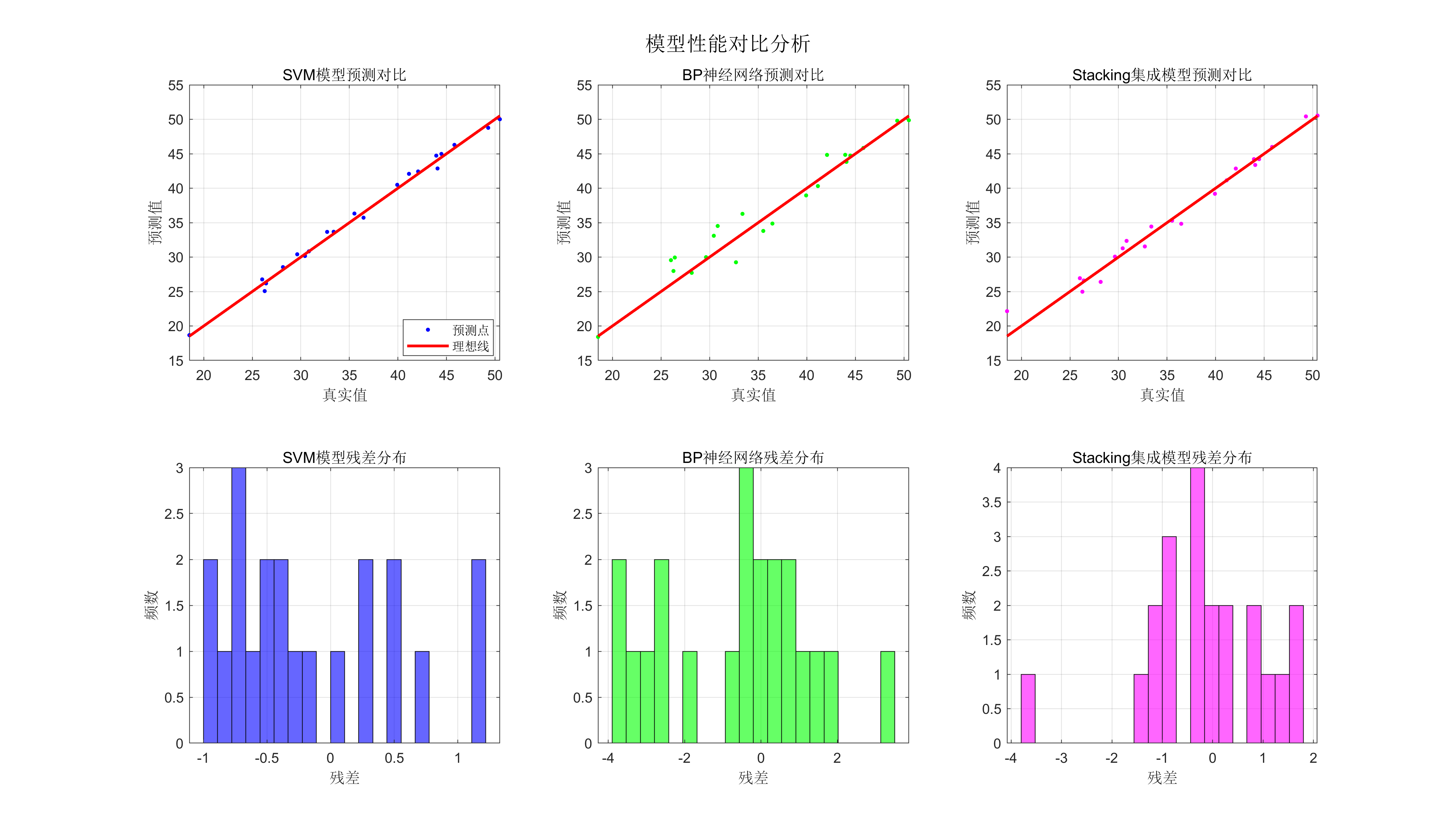
可视化:包括SVM参数搜索的3D图、预测对比图、残差分析、性能对比柱状图等;
模型保存:保存训练好的模型和预测结果。
三、算法步骤
- 数据准备与标准化;
- SVM参数网格搜索与模型训练;
- BP神经网络训练;
- 构建Stacking特征:将SVM和BP的预测作为元学习器的输入;
- 训练随机森林元学习器;
- 反标准化并计算性能指标;
- 可视化分析;
- 保存模型与结果。
四、技术要点
- 基学习器:SVM(RBF核) + BP神经网络;
- 元学习器:随机森林(回归树集成);
- 优化方法:网格搜索(SVM参数C与γ);
- 评估方法:5折交叉验证;
- 可视化工具:MATLAB绘图函数。


七、运行环境
- MATLAB版本:2019b及以上;
- 必要工具箱:
- Statistics and Machine Learning Toolbox(用于SVM、随机森林)
- Neural Network Toolbox(用于BP神经网络)
八、应用场景
该模型适用于各类回归预测问题,如:
- 房价预测
- 销量预测
- 股票价格预测
- 能源负荷预测
- 工业参数预测等
- 尤其适用于数据非线性强、特征复杂、单一模型预测效果有限的场景。