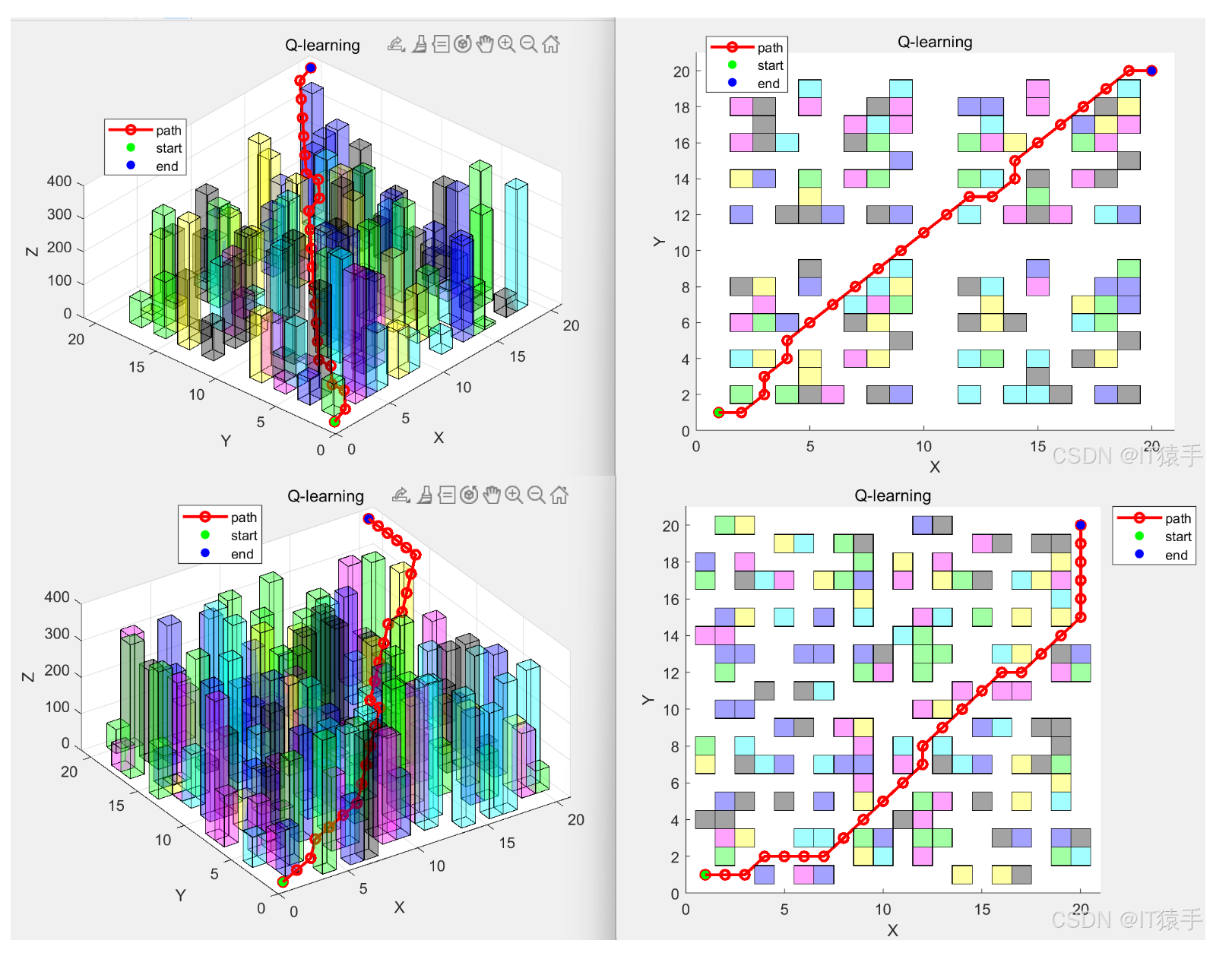
随着无人机在城市环境中的广泛应用,其三维路径规划问题日益受到关注。城市场景具有复杂多变的障碍物布局和严格的飞行安全要求,传统的路径规划算法往往难以满足实时性和最优性需求。本文提出了一种基于强化学习 Q-learning 算法的无人机三维路径规划方法,通过合理定义状态空间、动作空间和奖励函数,使无人机能够在城市场景中自主学习最优路径。实验结果表明,该算法能够有效避开障碍物,规划出较优的飞行路径,具有较高的成功率和适应性,为无人机在城市环境中的安全高效飞行提供了一种有效的解决方案。
在城市环境中,无人机的应用场景不断拓展,如物流配送、航拍测绘、交通监控等。然而,城市场景的复杂性给无人机的路径规划带来了巨大挑战。建筑物、信号塔等障碍物密集且形状各异,飞行空间受限,同时还需考虑飞行安全、能量消耗等多方面因素。传统的路径规划算法,如 A* 算法、Dijkstra 算法等,在三维复杂空间中存在计算复杂度高、难以适应动态环境等问题。强化学习作为一种通过与环境交互学习最优策略的机器学习方法,为无人机路径规划提供了新的思路。Q-learning 算法作为强化学习中的典型代表,具有无需环境模型、通过试错学习等优点,适合应用于复杂多变的城市场景。本文旨在深入研究基于 Q-learning 算法的无人机三维路径规划方法,以提高无人机在城市环境中的自主导航能力和路径规划效率。
强化学习是一种目标导向的学习方法,智能体通过与环境进行交互,根据环境反馈的奖励信号来学习最优行为策略,以最大化累积奖励。强化学习的基本要素包括智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward)和策略(Policy)。智能体根据当前状态选择动作,环境接收动作后发生变化并产生新的状态和奖励信号反馈给智能体。通过不断的试错过程,智能体逐渐学习到在不同状态下采取何种动作能够获得最大累积奖励。
Q-learning 算法是一种基于价值的强化学习方法,其核心是学习一个 Q 表,用于表示在给定状态下采取某个动作所能获得的预期累积奖励。Q 表的更新公式为:
Q(s,a) = Q(s,a) + α [r + γ max Q(s’,a’) - Q(s,a)]
其中,Q(s,a) 表示在状态 s 下采取动作 a 的 Q 值;α 是学习率,控制新旧信息的融合程度,取值范围在 [0,1] 之间;r 是当前动作获得的即时奖励;γ 是折扣因子,用于衡量未来奖励的权重,取值范围在 [0,1] 之间;max Q(s’,a’) 是下一个状态 s’ 下所有可能动作 a’ 中的最大 Q 值。通过不断地更新 Q 表,智能体最终能够收敛到最优策略。