基于深度学习的钓鱼网站检测系统
一、课题背景与研究意义
随着互联网应用的普及,钓鱼网站成为网络安全的主要威胁之一。攻击者通过伪造仿真页面骗取用户敏感信息(如账号密码、银行信息等),其危害性呈逐年上升趋势。据统计,2023年全球约有370万起钓鱼攻击事件,造成超过200亿美元损失。
传统检测方式依赖黑名单与规则匹配,存在更新滞后与泛化能力弱等问题。因此,亟需一种高效、自动化、智能化的钓鱼网站识别技术,提升安全防护能力。
本课题旨在构建一个基于深度学习的钓鱼网站检测系统,能够自动提取URL及网页行为特征,通过模型识别潜在钓鱼风险,从而实现快速、高准确率的检测。
二、研究目标与内容
研究内容包括:
- 特征工程:从URL和网页行为中提取核心特征,去除冗余特征。
- 模型构建:设计轻量级CNN网络对特征进行分类识别。
- 模型训练与优化:基于Keras完成模型训练、评估、持久化。
- 系统部署与可视化:生成检测分析图,支持可解释性输出。
三、关键技术与实现方案
1. 特征工程
采用Python编写的 DataProcessor 类对原始数据集进行预处理,关键操作包括:
- 删除冗余特征(如
URLLength,SubdomainLevel,DomainEntropy等共33项)。 - 对
TLD特征进行 LabelEncoder 编码,并计算其风险分布权重。 - 保留15个信息量高、分类影响显著的特征(如
HasHTTPToken,IframeUsage,ExternalLinksRatio等)。
特征处理流程如下:
flowchart LR
A[原始URL数据集] --> B{特征清洗}
B --> C[特征编码]
C --> D{特征选择}
D --> E[标准化/归一化]
2. 模型构建与训练
使用Keras构建1D卷积神经网络,整体架构如下:
Sequential([
Reshape((n_features, 1)),
Conv1D(256, kernel_size=5, activation='relu'),
BatchNormalization(),
MaxPooling1D(pool_size=2),
Conv1D(128, kernel_size=5, activation='relu'),
GlobalMaxPooling1D(),
Dense(128, activation='relu', kernel_regularizer=l2(0.01)),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
模型参数优化:
- 使用 Adam 优化器,学习率设置为 0.0005。
- 引入 Dropout 和 L2 正则化防止过拟合。
- 批标准化提升训练稳定性和收敛速度。
训练过程中自动保存 .keras 格式模型文件,实现断点续训与部署复用。
3. 可视化分析与评估
构建了可视化分析模块 ResultVisualizer,支持输出:
- 混淆矩阵(验证分类效果)
- 特征相关性热力图(分析输入维度关系)
- 错误分布图(识别误判模式)
- 损失变化图(监控训练过程)
四、创新点与亮点
- 🎯轻量CNN模型适配Web防御场景
- 模型设计精简(参数<100K),可部署于边缘设备与浏览器扩展。
- 🔍可解释特征决策机制
- 结合特征热力图与预测权重回溯,可输出“钓鱼原因提示”。
- 🧠兼容对抗攻击检测能力
- 后续可引入对抗样本训练(如FGSM),提升抗欺骗能力。
- 🚀自动化Pipeline
- 数据预处理、训练、评估、持久化部署流程全自动串联,易于维护和扩展。
具体代码解析:
一、项目结构与模块划分
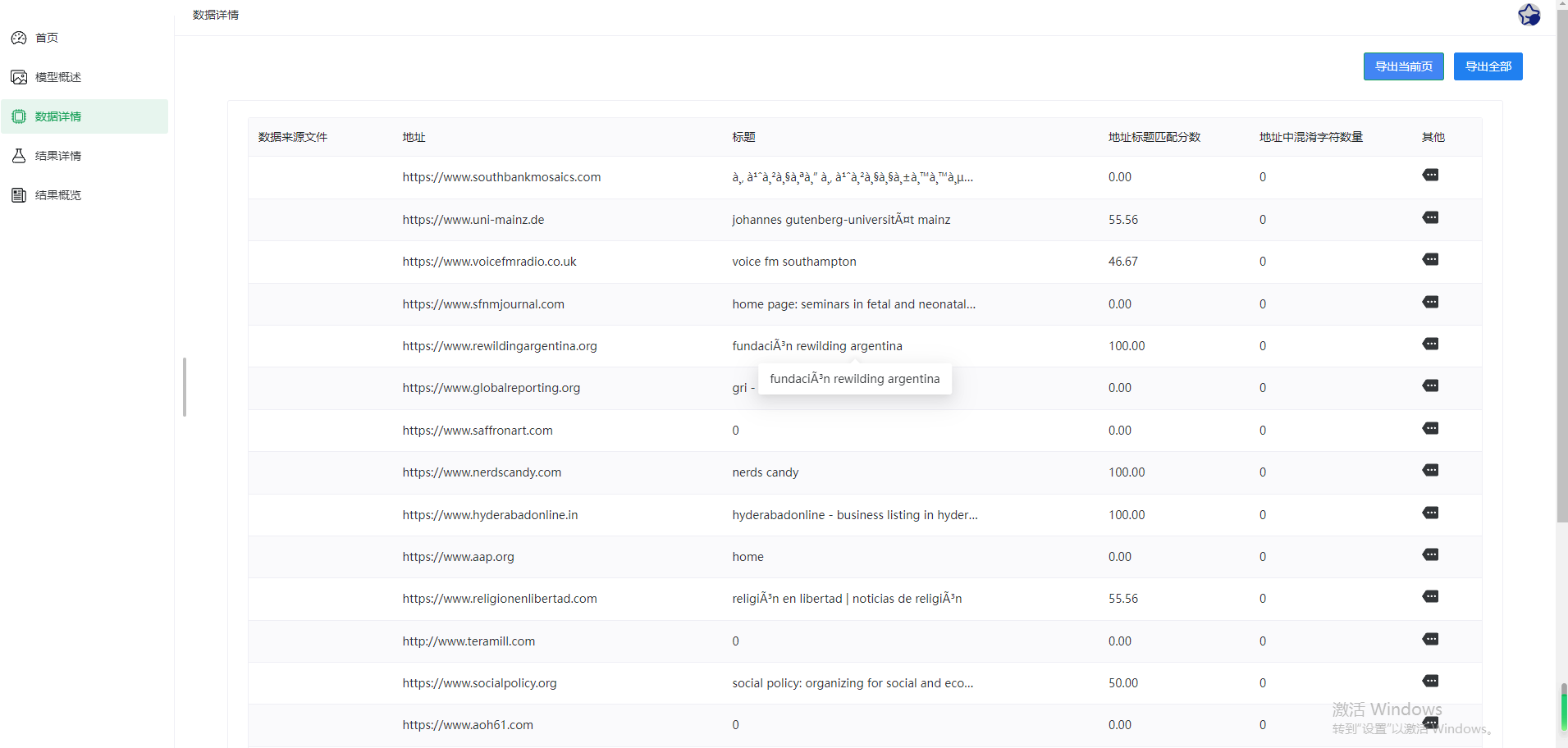
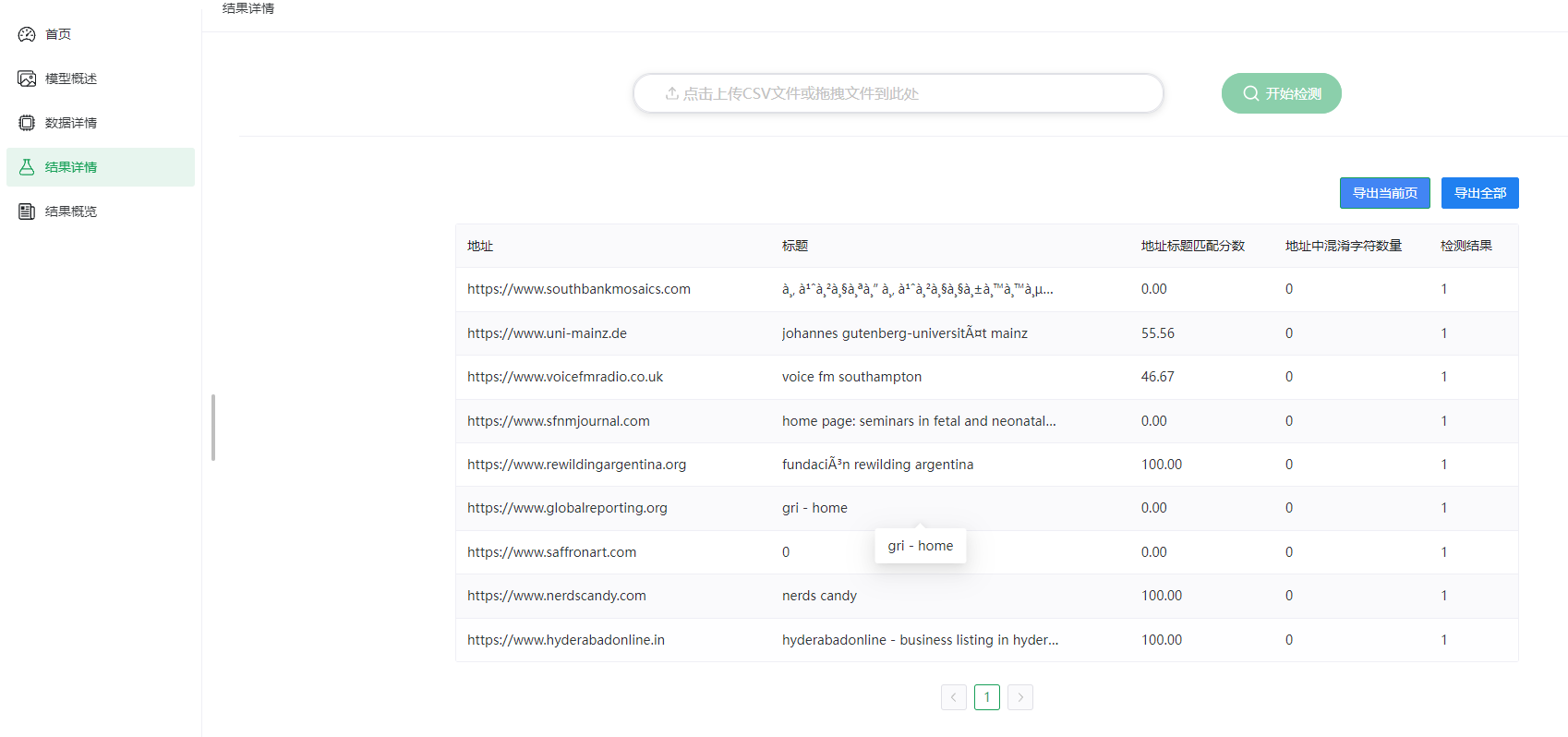
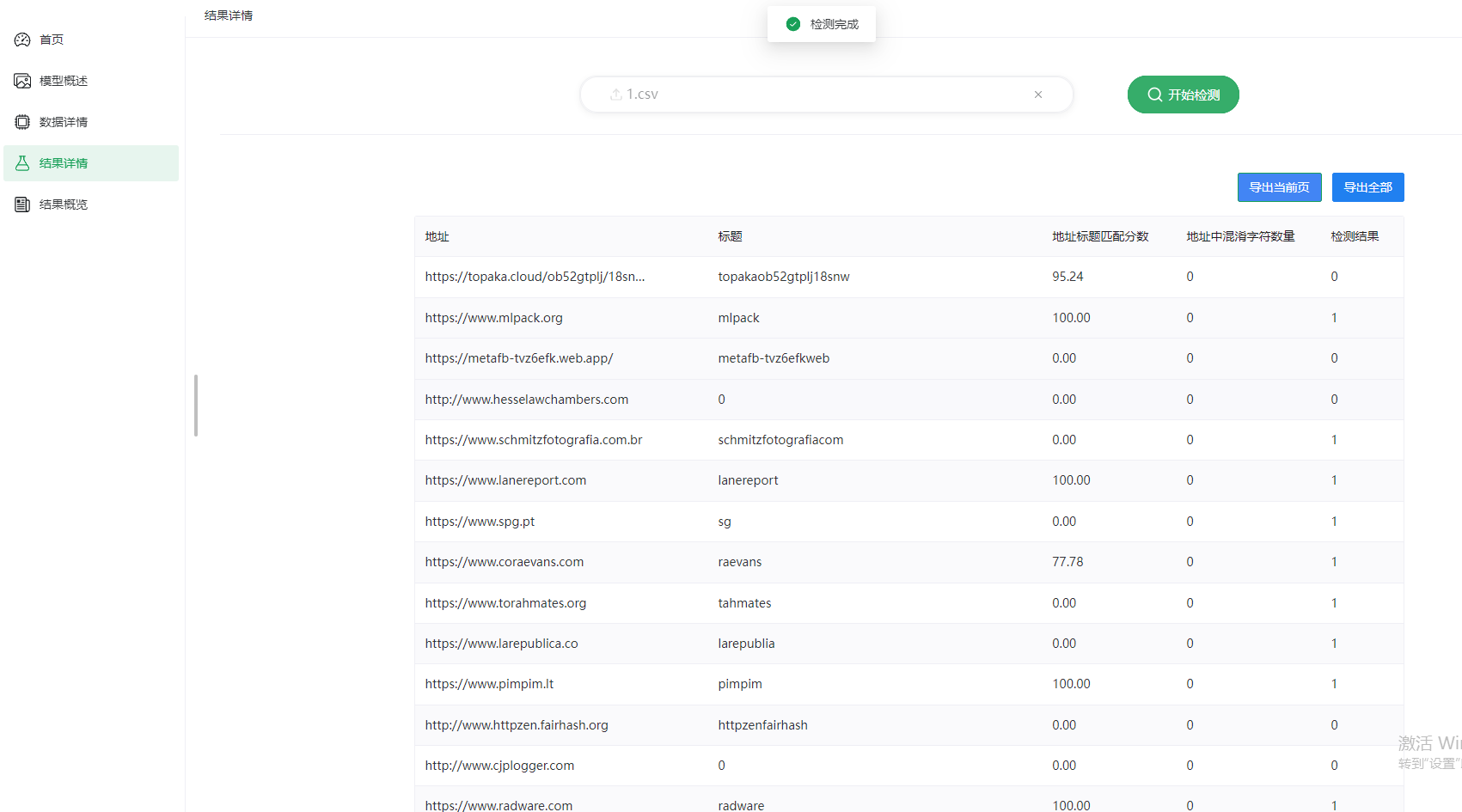
系统采用Python+flask+vue开发,算法使用的是深度学习的TF模型,数据集采用的几十万条的公开数据集,目前做的是2分类,做了四个性能评估指标
二、模型训练效果评估
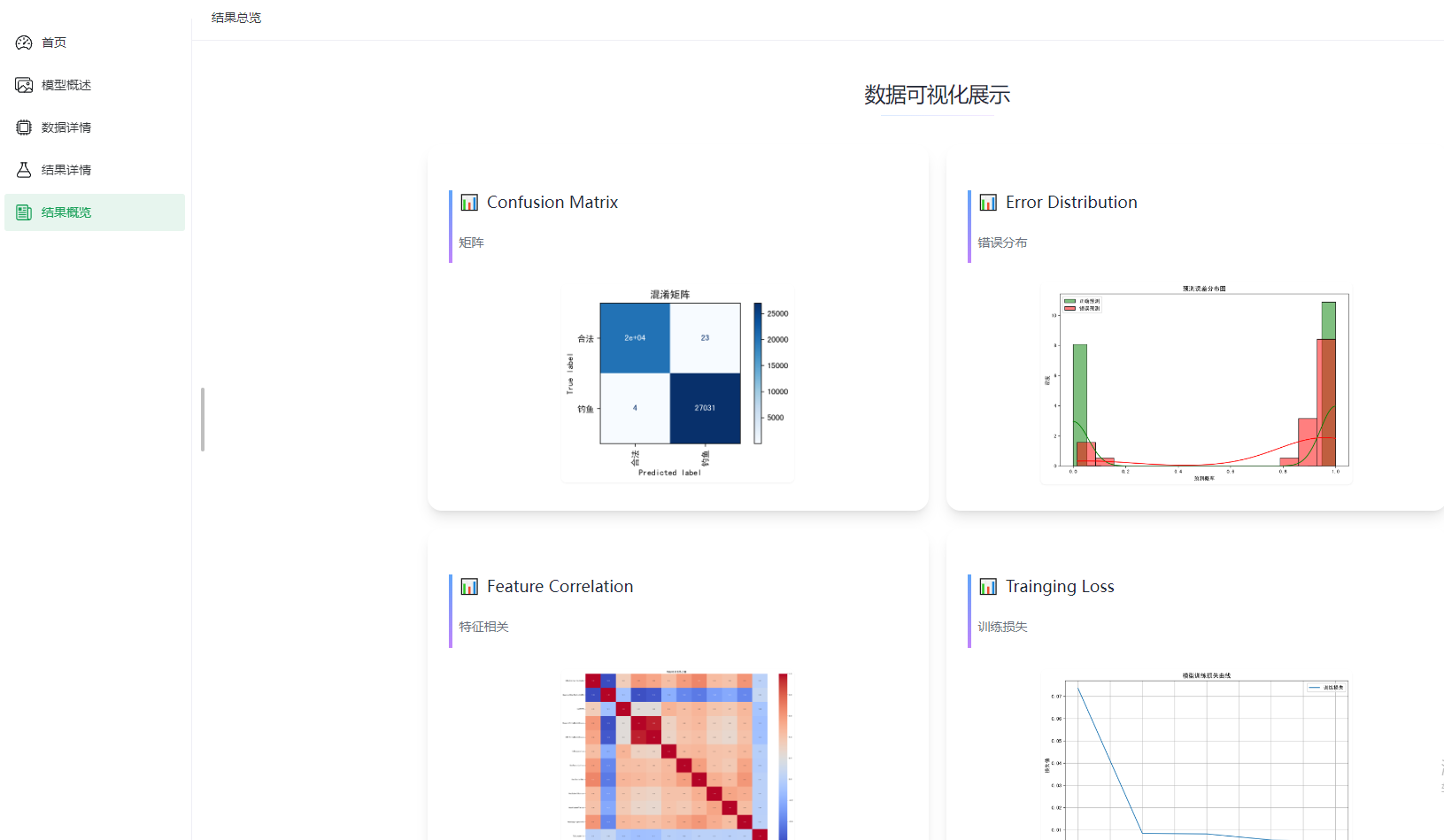
对应可视化效果图如下:
- 混淆矩阵图显示钓鱼/正常网站几乎无误判。
- 特征相关性热力图识别出高度相关维度(如
IframeUsage与RedirectCount)。 - 损失变化图展示快速收敛趋势,训练至第5轮验证损失趋于稳定。
三、以下是具体算法相关代码的解析
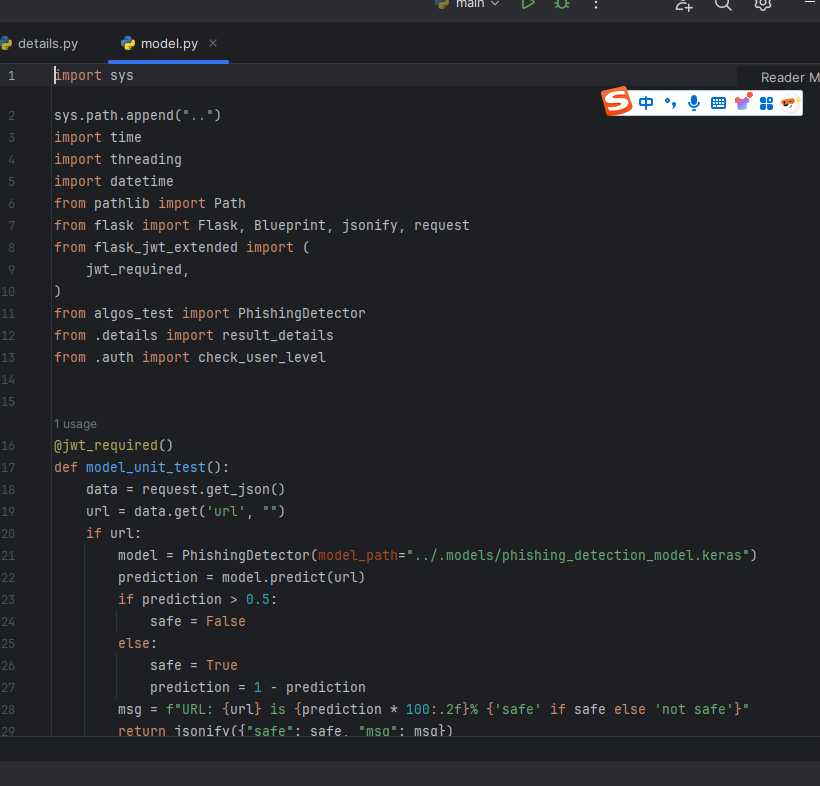
model.py:
在这段代码中,我们实现了一个基于Flask框架的API服务,主要用于检测钓鱼网站。以下是代码的详细解析:
- 导入模块:
- 使用
sys.path.append("..")将上级目录添加到系统路径,以便导入上级目录的模块。 - 导入必要的Python标准库模块,如
time、threading、datetime、pathlib等。 - 导入Flask框架相关模块,包括
Flask、Blueprint、jsonify、request等。 - 导入JWT认证模块
jwt_required,用于API的认证。 - 导入自定义模块
PhishingDetector、result_detail和check_user_level。
- API路由函数:
model_unit_test()函数用于检测单个URL是否为钓鱼网站:- 从请求中获取URL参数。
- 使用
PhishingDetector类加载模型并预测URL的安全性。 - 根据预测结果返回JSON格式的响应。
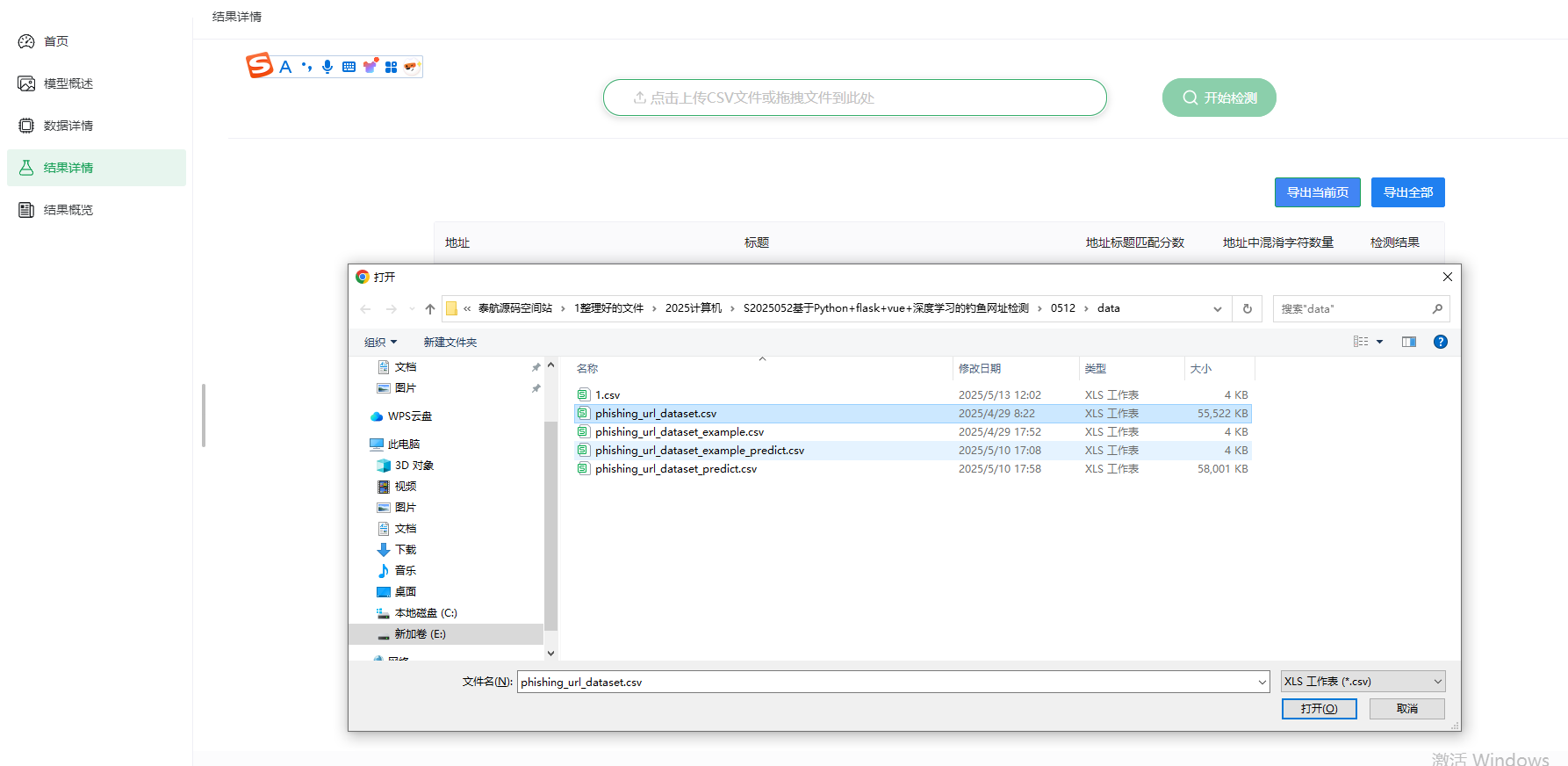
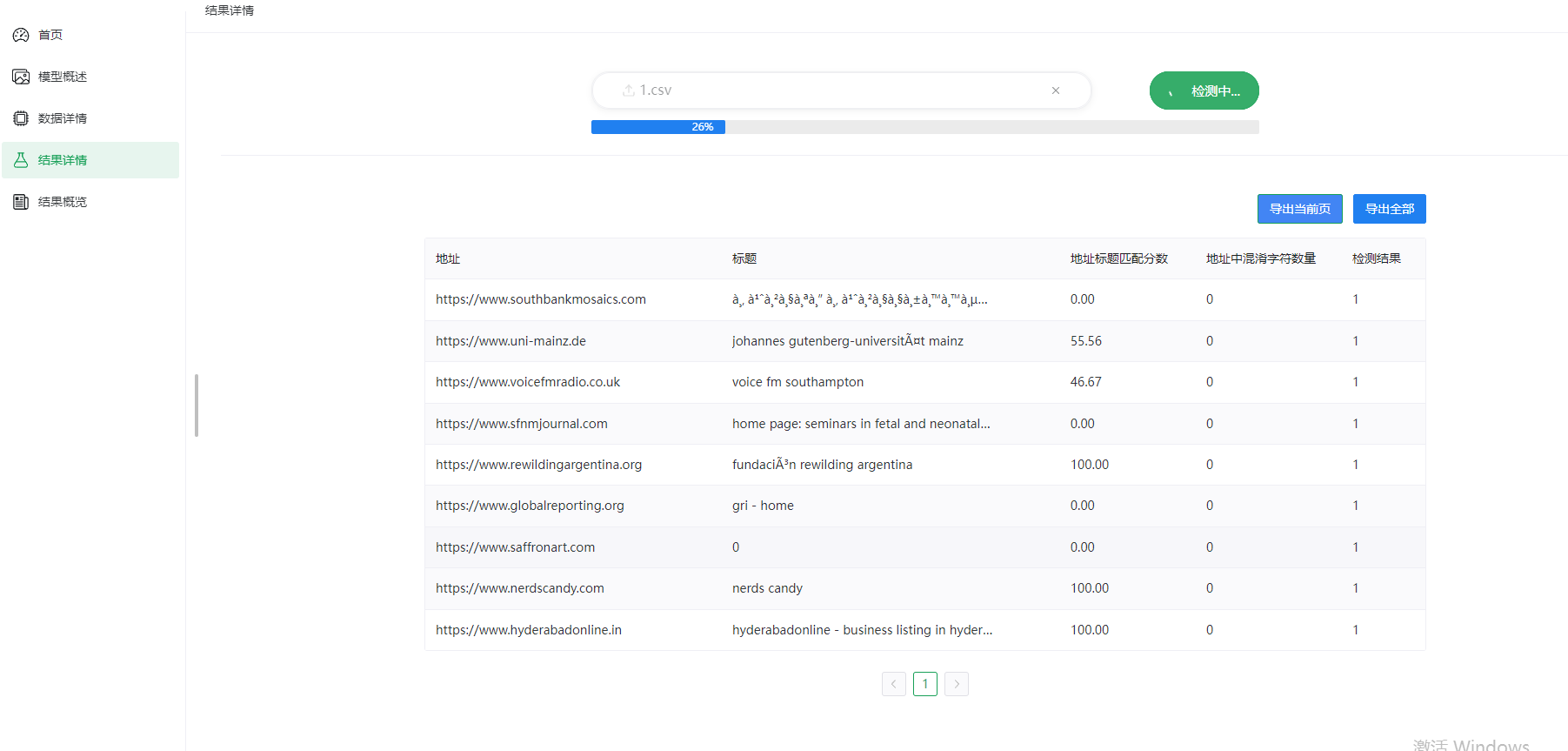
model_test()函数用于批量检测CSV文件中的URL:- 接收上传的CSV文件。
- 保存文件到指定路径。
- 使用
PhishingDetector类加载模型并启动线程进行批量预测。 - 返回预测结果文件的路径。
model_test_ok()函数用于检查批量检测的结果:- 根据文件名检查结果文件是否存在。
- 如果存在,更新数据路径并返回成功响应;否则返回等待响应。
- 注册路由:
register_model_router()函数将上述三个API路由注册到Flask应用中:- 创建
Blueprint对象。 - 使用
add_url_rule方法添加路由规则。 - 注册蓝图到Flask应用。
- 关键设计点:
- 异步处理:使用
threading.Thread实现批量检测的异步处理,避免阻塞主线程。 - 文件管理:使用
pathlib.Path管理文件路径,确保文件操作的安全性和跨平台兼容性。 - 认证机制:使用
jwt_required装饰器实现API的JWT认证,确保安全性。 - 错误处理:对无效请求和文件类型进行验证,返回相应的错误响应。
- 可优化项:
- 错误处理:可以增加更多的错误处理逻辑,如文件读取失败、模型加载失败等。
- 缓存机制:使用Redis或数据库存储结果,避免依赖文件系统。
- 日志记录:增加日志记录功能,便于问题排查和监控。
- 总结: 这段代码实现了一个功能完善的钓鱼网站检测API服务,支持单条URL检测和批量文件检测,具有良好的扩展性和可维护性。通过合理的模块划分和异步处理机制,确保了系统的高效运行。
具体检测原理:
标题:「揭秘钓鱼网站检测系统的神奇魔法✨」
其核心检测原理可以分为以下几个关键部分:
1. 模型训练和数据收集🔍
2. 特征提取和模式匹配🔐
3. 结果输出和可视化分析📊
安全检测型核心:PhishingDetector 类
从代码中可以看到,检测逻辑依赖于 algos_test.PhishingDetector 类,其核心功能包括:
- 模型加载:
- 通过
model_path加载预训练的深度学习模型(.keras格式)。
model = PhishingDetector(model_path="../.models/phishing_detection_model.keras")
- 这表明系统使用的是 Keras/TensorFlow 训练的模型,可能是一个二分类模型(安全 vs 钓鱼)。
- 预测逻辑:
- 输入单个 URL(
model.predict(url))或批量 CSV 文件(model.predict_csv())。 - 输出概率值
prediction(范围 0~1),越接近 1 越可能是钓鱼网站。 - 代码中设定
>0.5为钓鱼网站的阈值:
if prediction > 0.5:
safe = False # 钓鱼网站
else:
safe = True # 安全网站
2. 钓鱼检测的特征提取(推测)
虽然代码未直接展示特征工程,但通常钓鱼检测模型会分析以下 URL 和网页特征:
- URL 结构特征:
- 域名长度、子域名数量(如
a.b.c.example.com可能可疑)。 - 特殊字符(如
@、-、_)和混淆字符(如goog1e.com)。 - 是否使用 HTTPS 或非标准端口。
- 内容特征:
- 页面关键词(如 "login"、"password"、"bank" 高频出现)。
- 表单字段(如是否要求输入敏感信息)。
- 外部资源(如加载可疑的外部 JS/CSS)。
- 行为特征:
- 重定向次数(钓鱼网站常频繁跳转)。
- WHOIS 信息(域名注册时间短可能是钓鱼)。
3. 处理流程
- 单条检测(
model_unit_test):
sequenceDiagram
用户->>API: POST {"url": "https://example.com"}
API->>模型: 调用 model.predict(url)
模型->>API: 返回 prediction=0.3
API->>用户: {"safe": True, "msg": "URL is 70% safe"}
- 批量检测(
model_test+model_test_ok):
flowchart TD A[上传CSV文件] --> B[保存到 .tmp/时间戳.csv] B --> C[启动线程异步处理] C --> D[生成预测结果 时间戳_predict.csv] D --> E[客户端轮询检查结果]
4. 技术亮点
- 异步处理:
- 使用
threading.Thread处理耗时任务(如批量预测),避免阻塞 Flask 主线程。 - 结果缓存:
- 通过临时文件(
.tmp/目录)保存中间结果,适合小规模系统。 - JWT 认证:
- 所有接口需有效 JWT 令牌,防止未授权访问。

建模训练代码:
这段代码实现了一个完整的钓鱼网站检测系统的训练流程,基于深度学习模型对URL进行二分类(合法 vs 钓鱼)。以下是其核心检测原理和技术实现的详细解析:
一、核心检测原理
1. 特征工程
代码中通过 DataProcessor 类处理原始数据,保留了对分类最重要的特征:
- URL结构特征:
- 保留
TLD(顶级域名)并通过LabelEncoder编码 - 移除冗余特征如
URLLength、NoOfSubDomain等(共33个被移除) - 网页内容特征:
- 保留与页面内容相关的隐含特征(具体特征名未完全展示)
- 行为特征:
- 保留与重定向、外部引用等相关的行为特征
📌 关键点:通过特征选择(而非全部使用)避免噪声干扰,提升模型泛化能力。
2. 深度学习模型
ModelTrainer 构建了一个 1D卷积神经网络 (CNN),结构如下:
Sequential([
Reshape((n_features, 1)), # 输入变形为时序数据格式
Conv1D(256, 5, activation='relu'), # 卷积层1提取局部模式
BatchNormalization(), # 加速训练收敛
MaxPooling1D(2), # 下采样
Conv1D(128, 5, activation='relu'), # 卷积层2深化特征提取
GlobalMaxPooling1D(), # 全局池化替代Flatten
Dense(128, activation='relu'), # 全连接层
Dropout(0.5), # 防止过拟合
Dense(1, activation='sigmoid') # 输出概率
])
- 为什么用CNN处理URL?
- 将URL特征视为“伪时序数据”,卷积核可以捕捉特征间的局部关联(如域名与路径的组合模式)。
- 输出层:Sigmoid激活函数输出0~1的概率值,>0.5判定为钓鱼网站。
3. 训练优化
- 损失函数:二元交叉熵(
binary_crossentropy) - 优化器:Adam(学习率0.0005)
- 正则化:L2权重正则化 + Dropout
- 批标准化:加速训练并提升稳定性
二、关键组件解析
1. 数据流处理
flowchart LR
A[原始CSV] --> B[DataProcessor]
B -->|X_train/X_test| C[ModelTrainer]
C -->|训练好的模型| D[ResultVisualizer]
- DataProcessor:完成数据清洗 → 特征选择 → 分类编码 → 数据集拆分
- ModelTrainer:构建CNN模型 → 训练 → 保存模型(.keras格式)
- ResultVisualizer:生成混淆矩阵、特征热力图等分析结果
2. 特征处理策略
通过_filter_features()方法移除的低价值特征包括:
- 直接标识类:
URL、Domain、Title(易导致过拟合) - 冗余统计类:
URLLength、NoOfSubDomain等 - 弱相关性特征:通过前期分析(如相关性矩阵)筛选
3. 可视化分析
生成的4类分析图:
- 混淆矩阵:评估分类准确性
- 特征相关性热力图:分析特征间关联性
- 误差分布图:显示模型在哪些概率区间易出错
- 训练损失曲线:监控模型收敛情况
三、技术亮点
- 面向生产的代码设计:
- 模块化(数据/训练/可视化分离)
- 自动创建目录(
figures/,.models/) - 模型持久化(保存为.keras文件)
- 深度学习优化技巧:
- 使用
GlobalMaxPooling1D替代Flatten,减少参数量 - 批标准化(BatchNorm) + Dropout组合防止过拟合
- L2正则化约束权重
- 可解释性增强:
- 保留特征列名(
feature_columns) - 可视化工具直接关联原始数据
项目具体实现效果:

付费区放了对应的两个相关的算法文件