专题推荐:代码分享,典藏级代码,原创代码改进,论文思路,免责声明(点击即可跳转)能源算法小屋:matlab代码,python代码
👉抓住最后一个月,部分高质量电力系统预测和优化代码限时限量优惠!低至7折!祝科研顺利!👉【重磅更新】全家桶!电力系统优化与预测【原创matlab代码】合集2025.2.5👉低至2.5折!电力系统完整版原创理论性综述论文思路大放送!均为新型电力系统的热门研究方向!👉持续更新!高创新组合模型和算法典藏级matlab代码(电力系统优化和时间序列预测方向)倾情推送25.3.11👉论文生产机!时间序列预测算法高创新matlab代码,可用于风光负荷气象等预测2025.3.17
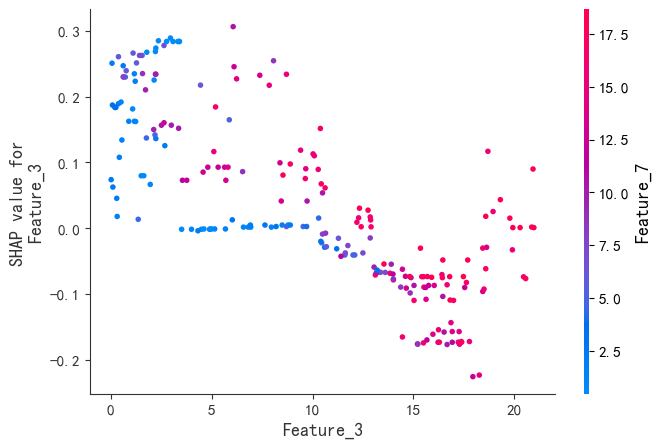
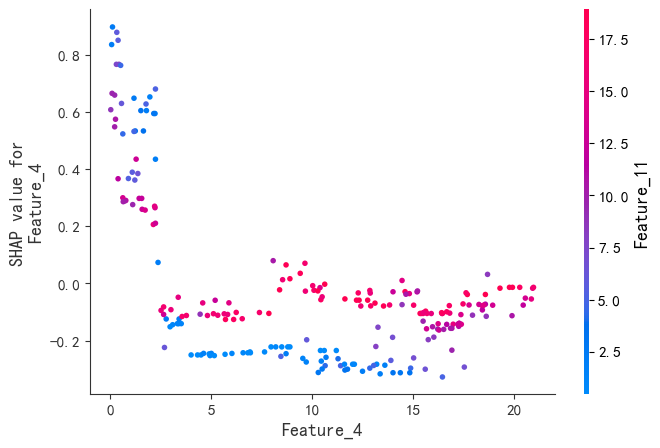
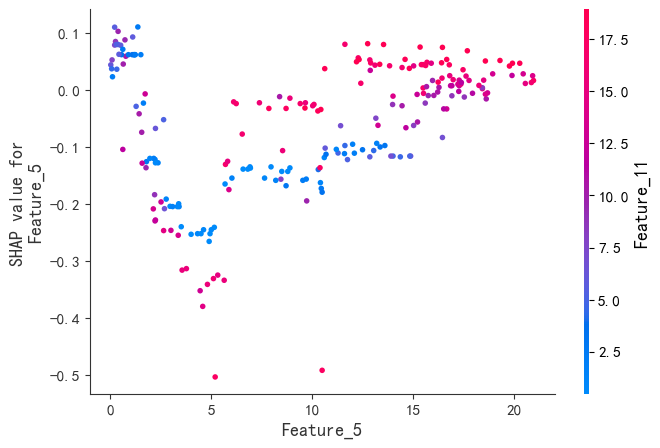
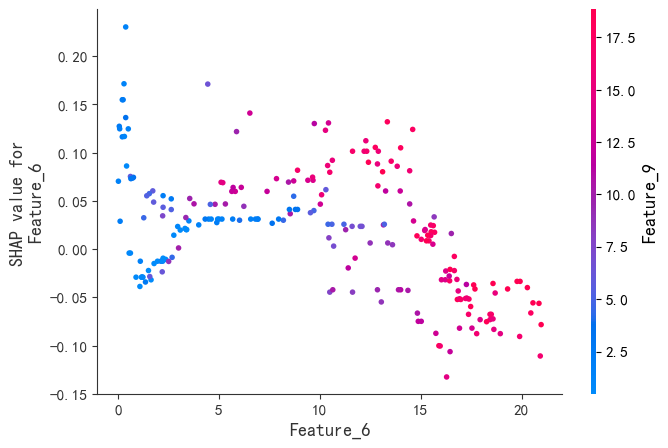
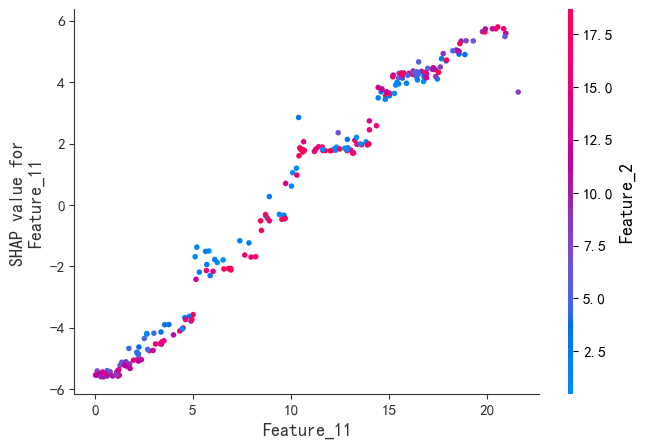
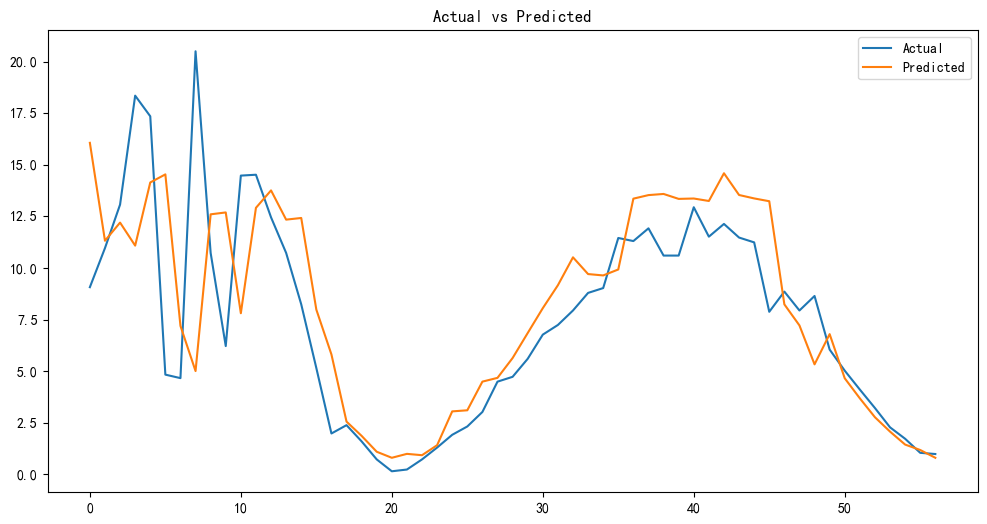
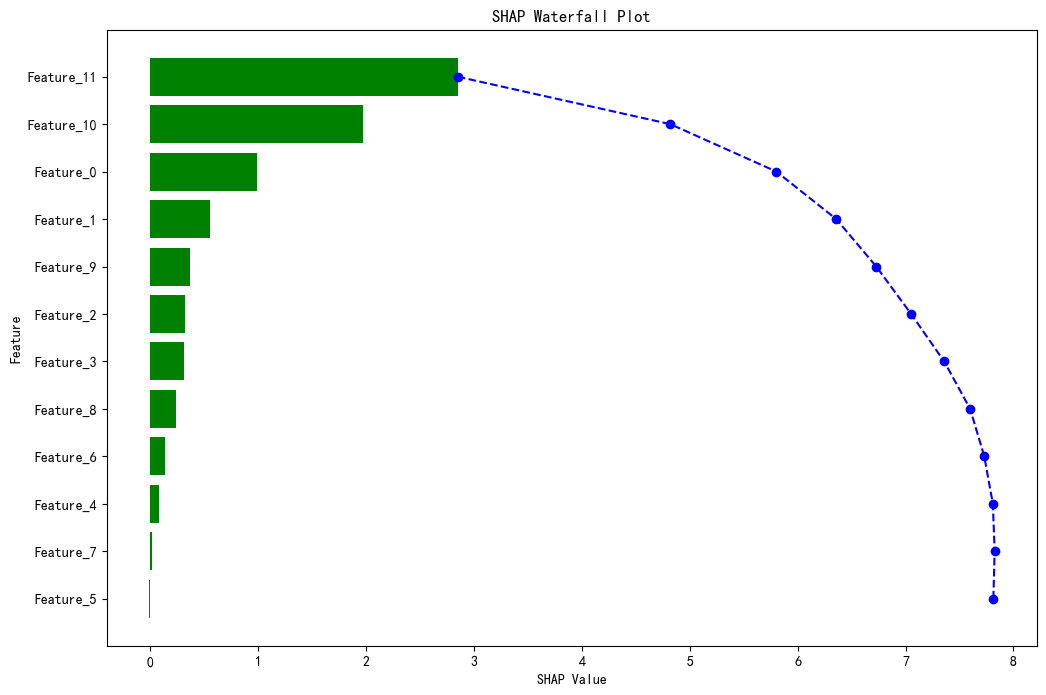
程序名称:基于Xgboost参数优化和SHAP特征可视化分析的时间序列预测模型
实现平台:python—Jupyter Notebook
代码简介:构建了基于极致梯度提升(eXtreme Gradient Boosting,XGBoost)的时间序列预测模型,并通过SHAP(SHapley Additive exPlanations)可视化特征的交互影响,增强模型的可解释性。使用网格搜索与交叉验证优化Xgboost的参数:param_grid = { 'max_depth': [3, 4, 5, 6], # 树的最大深度 'learning_rate': [0.01, 0.05, 0.1, 0.2], # 学习率'n_estimators': [100, 200, 300], # 树的数量 'subsample': [0.7, 0.8, 0.9], # 子采样率 'colsample_bytree': [0.7, 0.8, 0.9] # 列采样率}。可用于风光负荷、天气、交通等一切符合模型输入的时间序列预测。
XGBoost(eXtreme Gradient Boosting)是一种高效、灵活且广泛应用的机器学习算法,尤其在结构化数据建模中表现卓越。
一、核心原理
XGBoost(极端梯度提升)是一种基于梯度提升框架的集成学习算法,通过逐步训练多个弱模型(通常是决策树)来提升整体预测性能。其核心思想是每一棵新树都专注于修正前一棵树预测的残差(错误),最终将所有树的预测结果加权求和得到最终输出。
1. 目标函数设计
XGBoost的训练过程围绕优化一个自定义目标函数展开,该目标函数包含两部分:
- 预测误差项:衡量模型预测结果与真实值的差距,例如回归任务中的均方误差,或分类任务中的交叉熵。
- 模型复杂度惩罚项:通过限制树的复杂度(如叶子节点数量、叶子权重大小)防止模型过拟合。
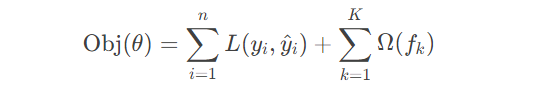
2. 梯度优化方法
不同于传统梯度提升仅用一阶导数(梯度),XGBoost还利用二阶导数(曲率)更精准地更新模型。这类似于在优化时不仅考虑“方向”,还考虑“步长”,使模型更快收敛且更稳定。
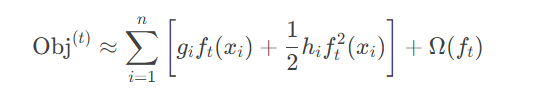
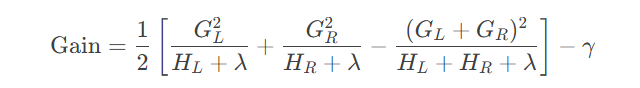
3. 树的生成策略
- 贪心分裂:遍历所有特征和特征值,选择能带来最大增益的分裂点。增益的计算综合考虑分裂后的左右子树的预测误差减少量,并扣除新增节点的复杂度惩罚(如叶子节点数量的控制参数)。
- 自动处理缺失值:在分裂时,XGBoost会为缺失值自动分配一个默认方向(左子树或右子树),选择能使增益最大化的路径。
二、关键特性
1. 高效性能
- 并行计算:虽然树模型本身是串行生成的,但XGBoost在特征排序和分裂点评估时实现并行化,大幅加速训练。
- 内存优化:数据按特征分块存储(Block结构),提升缓存利用率,减少计算时间。
- 稀疏数据处理:自动识别稀疏特征(如缺失值、One-Hot编码后的0值),跳过无意义的计算。
2. 防止过拟合
- 正则化:通过限制叶子节点权重、控制树的深度、设置最小分裂增益等参数抑制模型复杂度。
- 随机化策略:支持行采样(随机选样本)和列采样(随机选特征),类似随机森林,增强多样性。
3. 灵活性与扩展性
- 支持多种任务:分类、回归、排序、自定义损失函数均可适配。
- 分布式训练:可集成到Hadoop、Spark等大数据平台处理超大规模数据。
- 增量学习:允许在已有模型基础上继续训练新数据,无需从头开始。
在机器学习领域,模型的预测性能往往与可解释性成反比。以XGBoost为代表的集成学习算法,虽然在预测精度上表现出色,但其复杂的决策逻辑却让许多研究者望而却步。如何在不牺牲性能的前提下,揭示这些“黑箱模型”的内部机制?SHAP(SHapley Additive exPlanations)作为一种基于博弈论的模型解释方法,为这一难题提供了优雅的解决方案。
SHAP框架将博弈论中的Shapley值引入机器学习领域,提出了加性特征归因方法(Additive Feature Attribution)。其核心思想是将模型的预测结果分解为每个特征的贡献值,从而量化每个特征对预测结果的影响。
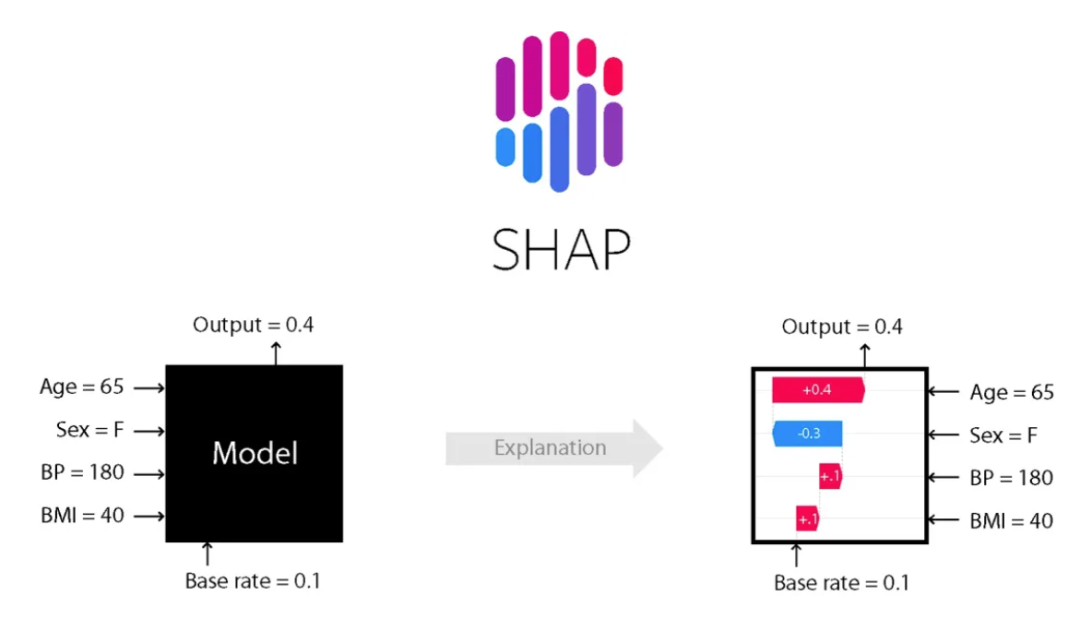
Shapley通过遍历所有特征组合,计算每个特征的边际贡献加权平均值。针对树模型(如XGBoost、LightGBM),TreeSHAP通过动态规划递归计算特征路径概率,降低复杂度,显著提升了计算效率。
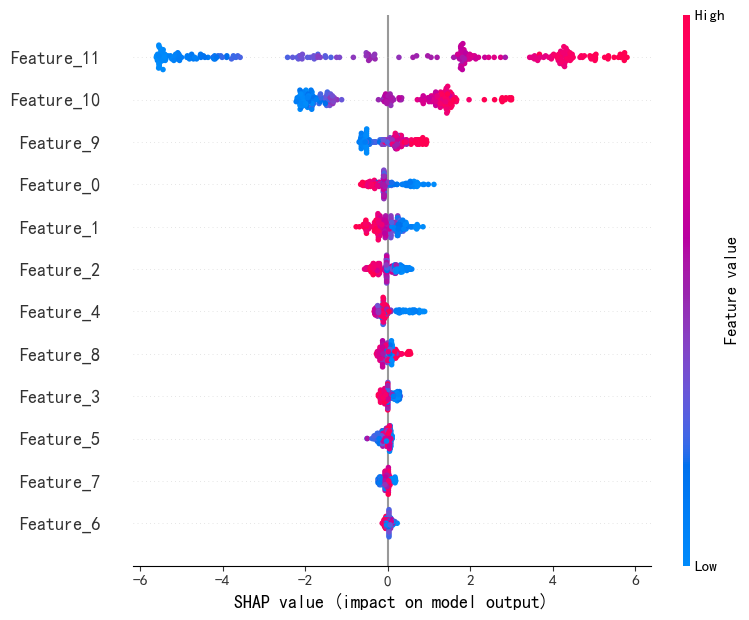
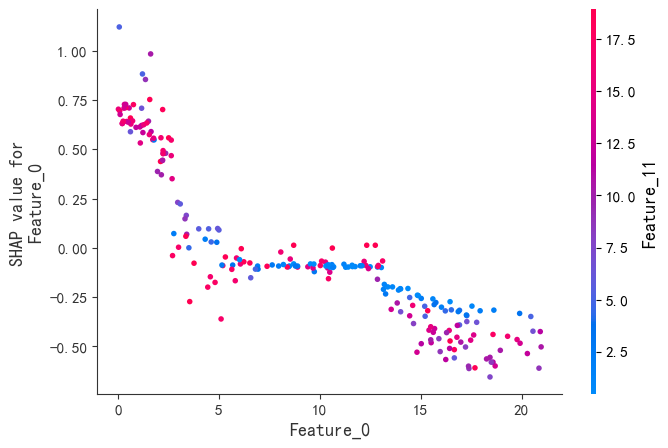
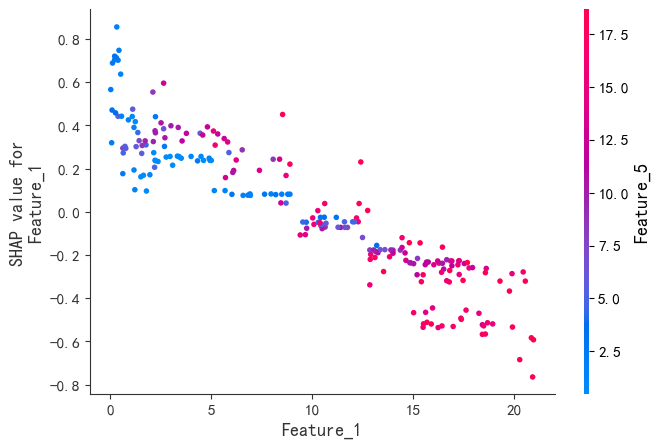
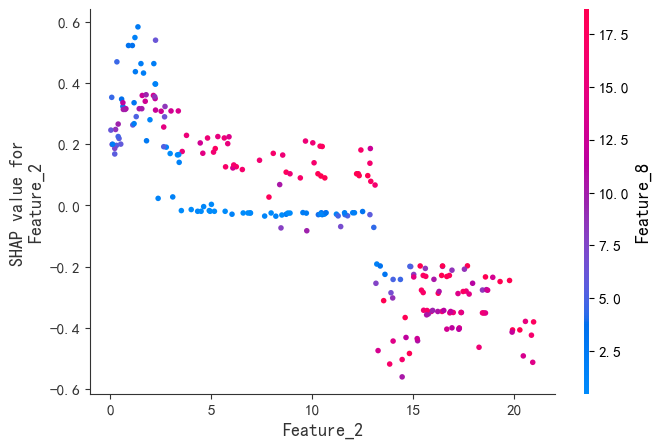
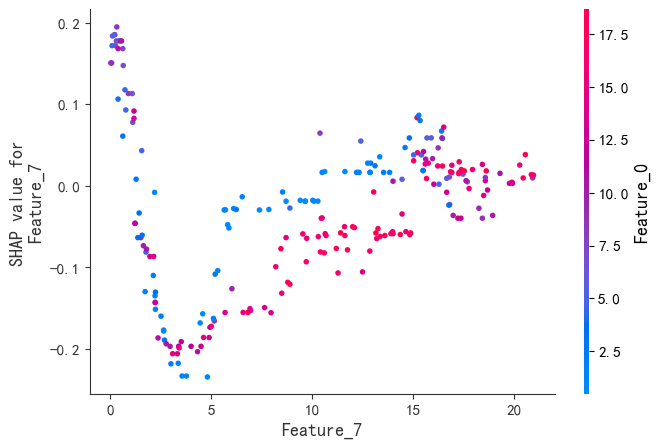
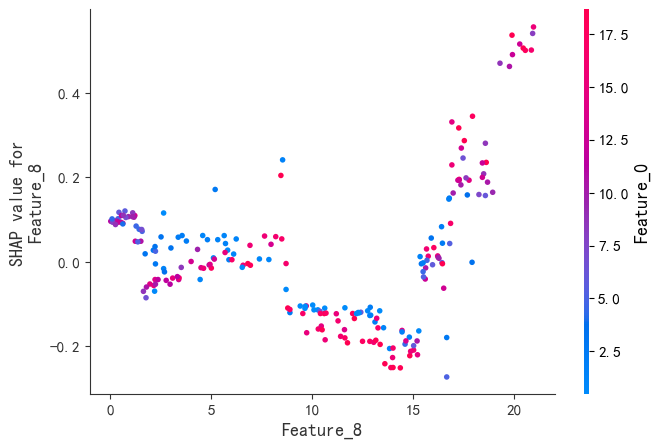
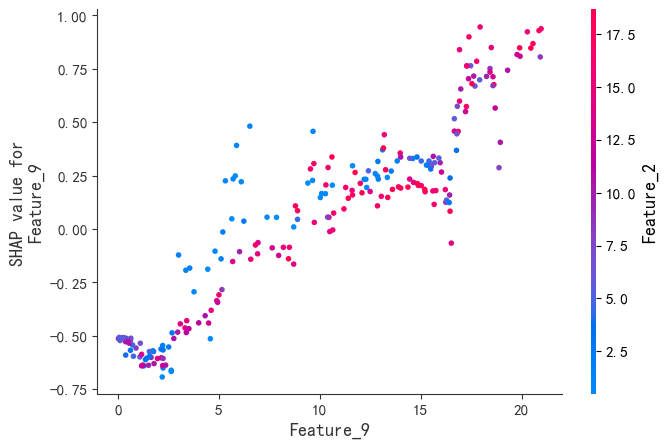
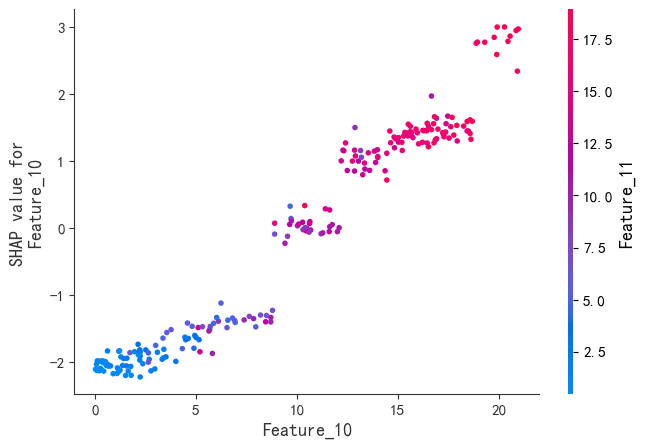
SHAP是唯一同时满足局部准确性、缺失特征归零和一致性三大公理的解释模型。既能揭示整体特征重要性,又能分析单个样本的预测逻辑。通过依赖图和交互作用值,动态拆解特征间的非线性协同效应。
尽管XGBoost在预测性能上表现出色,但其复杂的树结构使得理解模型的决策逻辑变得困难。SHAP框架的引入,为XGBoost的可解释性提供了全新的解决方案。
运行结果
Best parameters found: {'colsample_bytree': 0.9, 'learning_rate': 0.05, 'max_depth': 3, 'n_estimators': 100, 'subsample': 0.9} Mean Squared Error: 12.227052177143975