专题推荐:代码分享,典藏级代码,原创代码改进,论文思路,免责声明(点击即可跳转)【New Power System预测和优化理论】
👉抓住最后一个月,部分高质量电力系统预测和优化代码限时限量优惠!低至7折!祝科研顺利!👉【重磅更新】全家桶!电力系统优化与预测【原创matlab代码】合集2025.2.5👉低至2.5折!电力系统完整版原创理论性综述论文思路大放送!均为新型电力系统的热门研究方向!👉持续更新!高创新组合模型和算法典藏级matlab代码(电力系统优化和时间序列预测方向)倾情推送25.3.11👉论文生产机!时间序列预测算法高创新matlab代码,可用于风光负荷气象等预测2025.3.17
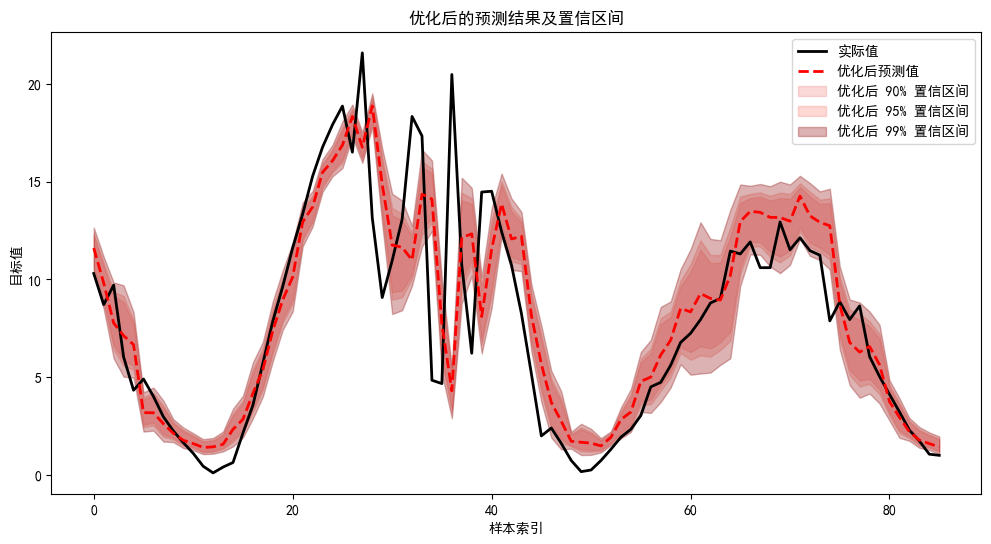
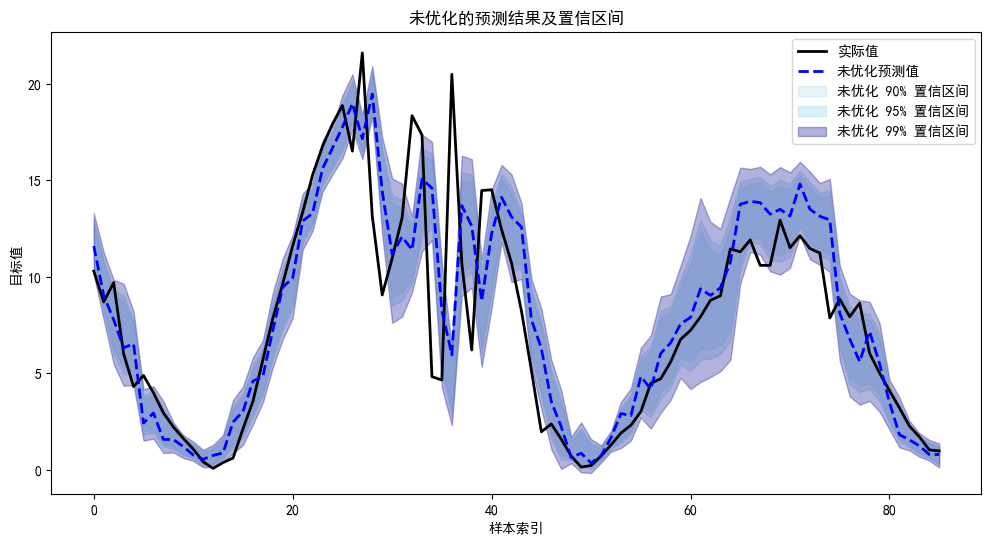
程序名称:基于Xgboost参数优化的时间序列区间预测模型
实现平台:python—Jupyter Notebook
代码简介:构建了基于极致梯度提升(eXtreme Gradient Boosting,XGBoost)的时间序列区间预测模型,可用于风光负荷、天气、交通等一切符合模型输入的时间序列预测。使用网格搜索与交叉验证优化Xgboost的参数('n_estimators': [100, 200, 300],'learning_rate': [0.01, 0.1, 0.2], 'max_depth': [3, 5, 7], 'subsample': [0.7, 0.8, 0.9], 'colsample_bytree': [0.7, 0.8, 0.9])。通过自助法(Bootstrap) 实现区间预测。自助法是一种统计方法,用于通过重复采样来估计模型预测结果的分布,从而计算置信区间。
XGBoost优势
- 强大的非线性拟合能力:时间序列数据往往具有复杂的非线性关系,XGBoost 通过集成多棵决策树,能够自动捕捉这些非线性关系,而无需手动设计复杂的特征。
- 自动特征选择:XGBoost 在训练过程中会自动评估特征的重要性,并选择对预测最有帮助的特征。这减少了手动特征选择的工作量,并且可以避免过拟合。
- 高效处理大规模数据:XGBoost 是为大规模数据集设计的,它利用多线程和分布式计算,能够快速处理海量数据,适合处理长时间跨度或高频时间序列数据。
- 支持多种目标函数和评估指标:XGBoost 支持多种目标函数(如均方误差、绝对误差等)和评估指标(如 MAE、RMSE 等),可以根据时间序列预测的具体需求选择合适的优化目标。
- 易于调参:XGBoost 提供了丰富的参数用于调整模型的复杂度和性能,如 learning_rate、n_estimators、max_depth 等。通过网格搜索等方法,可以方便地找到最优的参数组合。
- 可解释性强:虽然 XGBoost 是一种集成学习模型,但它的决策树结构使得模型的决策过程相对容易理解。通过分析特征重要性和单棵决策树的规则,可以对模型的预测结果进行解释。
- 适应性强:XGBoost 对时间序列中的异常值和噪声具有较强的鲁棒性,能够适应不同类型的季节性和趋势变化。
- 可扩展性强:XGBoost 支持分布式计算,可以利用多台机器并行处理数据,适合处理大规模时间序列数据集。
自助法(Bootstrap)原理
- 重复采样:从原始训练数据集中有放回地随机抽取样本,生成一个新的训练集(称为“自助样本”)。每次抽取的样本数量与原始训练集相同。重复上述过程多次(例如 1000 次),生成多个自助样本。
- 模型训练与预测:对每个自助样本重新训练模型,并使用测试集进行预测。这样会得到多个预测结果,每个预测结果对应一个自助样本。
- 统计分析:对所有预测结果进行统计分析,计算预测值的均值和标准差。使用均值作为最终预测值,标准差用于估计预测结果的不确定性。
- 置信区间计算:根据标准差和置信水平(如 90%、95%、99%),计算预测值的置信区间。
运行结果
最佳参数: {'colsample_bytree': 0.8, 'learning_rate': 0.01, 'max_depth': 3, 'n_estimators': 300, 'subsample': 0.7}