1. SVM
支持向量机(support vector machines,SVM)是一种二分类模型,它将实例的特征向量映射为空间中的一些点,SVM 的目的就是想要画出一条线,以 “最好地” 区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。SVM 适合中小型数据样本、非线性、高维的分类问题。
SVM 最早是由 Vladimir N. Vapnik 和 Alexey Ya. Chervonenkis 在1963年提出,目前的版本(soft margin)是由 Corinna Cortes 和 Vapnik 在1993年提出,并在1995年发表。深度学习(2012)出现之前,SVM 被认为机器学习中近十几年来最成功,表现最好的算法。
1. 概述
支持向量机(Support Vector Machine, 也称为支持向量网络)是一种二分类模型. 它源于统计学习理论, 是一个强学习器.从分类效力来看, SVM无论在处理线性还是非线性分类中, 都是明星般的存在。
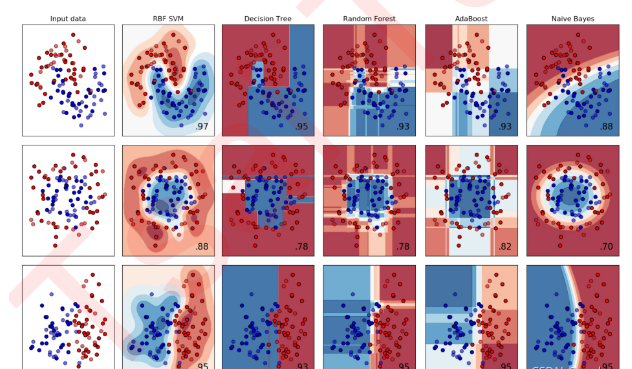
从实际来看, SVM在各种实际问题中也都具有不错的表现. 它在手写识别数字和人脸识别中应用广泛, 在文本和超文本的分类中举足轻重, 因为SVM可以大量减少标准归纳 (standard inductive) 和转换设置 (transductive settings) 中对标记训练示例的需求. 同时, SVM也被用来执行图像的分类, 并用于图像分割系统. 实验结果表明, 在仅仅三到四轮相关反馈之后, SVM就能实现比传统的查询细化方案 (query refinement schemes) 高出一大截的搜索精度. 除此之外, 生物学和许多其他科学都是SVM的青睐者, SVM现在已经被广泛用于蛋白质分类, 现在化合物分类的业界平均水平可以达到90%以上的准确率. 在生物科学的尖端研究中, 人们还使用支持向量机来识别用于模型预测的各种特征, 以找出各种基因表现结果的影响因素.
2. SVM如何工作
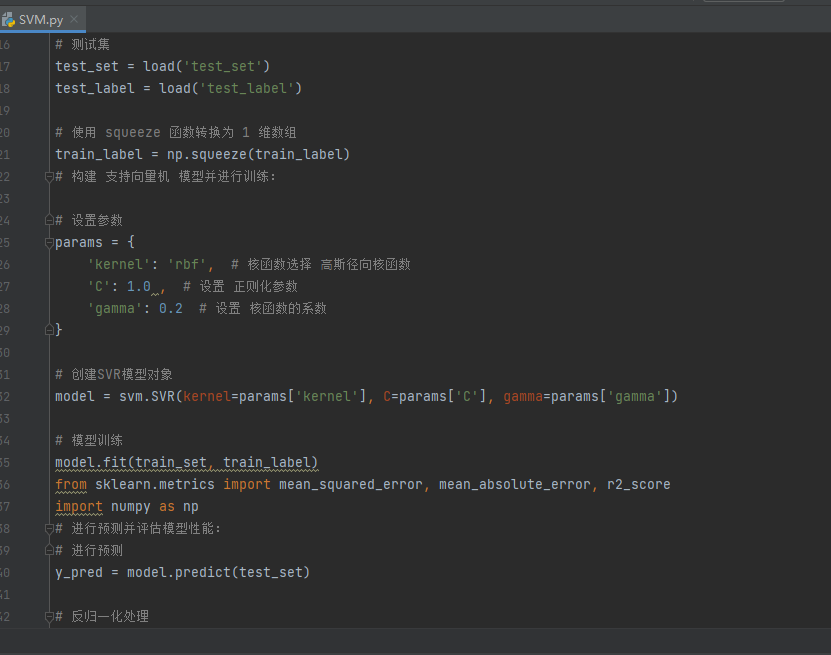
基于此,笔者整理了基于SVM的时间序列预测python代码,该代码质量优异,适合新手学习使用,注释小清晰,配备相关数据集。
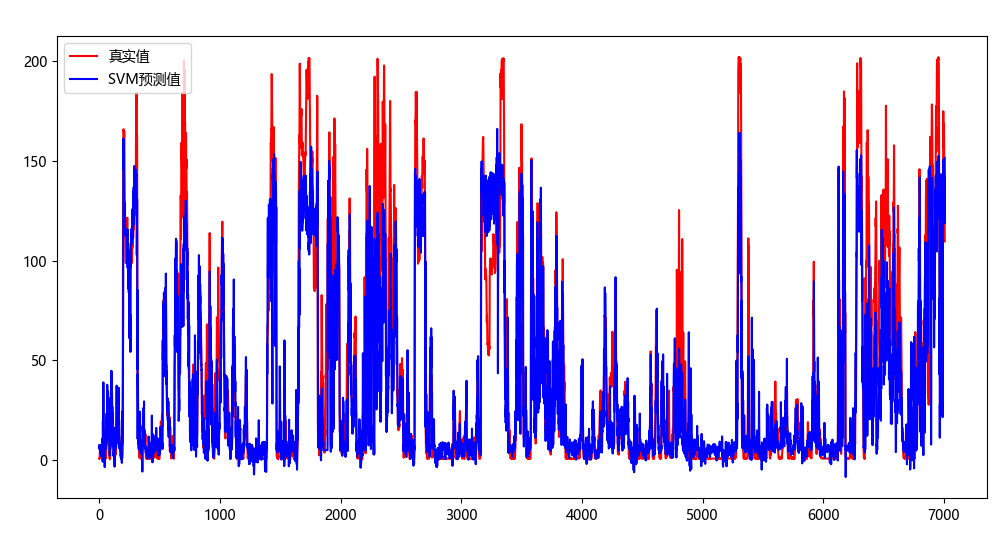
3、评价指标:
支持向量机 模型分数--R^2: 0.7740200305361501
**************************************************
测试数据集上的均方误差--MSE: 614.9418716434249
测试数据集上的均方根误差--RMSE: 24.79802152679574
测试数据集上的平均绝对误差--MAE: 15.222305277260096