DBSCAN 密度聚类算法,聚类结果可视化,Matlab源代码。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,簇集的划定完全由样本的聚集程度决定。聚集程度不足以构成簇落的那些样本视为噪声点,因此DBSCAN聚类的方式也可以用于异常点的检测。
算法的关键在于样本的‘聚集程度’,这个程度的刻画可以由聚集半径和最小聚集数两个参数来描述。如果一个样本聚集半径领域内的样本数达到了最小聚集数,那么它所在区域就是密集的,就可以围绕该样本生成簇落,这样的样本被称为核心点。如果一个样本在某个核心点的聚集半径领域内,但其本身又不是核心点,则被称为边界点;既不是核心点也不是边界点的样本即为噪声点。其中,最小聚集数通常由经验指定,一般是数据维数+1或者数据维数的2倍。
通俗地讲,核心点就是构成一个簇落的核心成员;边界点就是构成一个簇落的非核心成员,它们分布于簇落的边界区域;噪声点是无法归属在任何一个簇集的游离的异常样本。
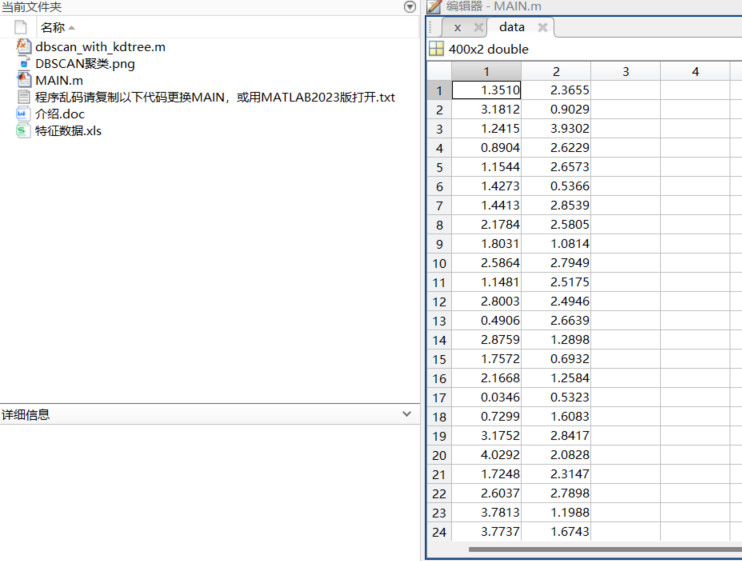
算法采用带有KD树加速的dbscanwithkdtree函数进行密度聚类。然后,我们根据每个簇的编号使用hsv色彩映射为每个簇分配不同的颜色,并用散点图进行可视化展示。同时,我们用黑色的"x"标记表示噪声点。请注意,DBSCAN的性能高度依赖于选择合适的epsilon和minPts参数。在实际应用中,你可能需要根据数据的特点进行调整,以获得更好的聚类结果。
从Excel表格中读取数据,直接替换数据就可以使用。程序内有详细注释,便于理解程序运行。
运行效果展示:
资料包含的文件及数据样式展示: