基于机器学习和深度学习的时间序列分析和预测(Python)
主代码:
import os
import numpy as np
import pandas as pd
import seaborn as sns
from ARX_Model import arx
import statsmodels.api as sm
from AR_Model import ar_model
import matplotlib.pyplot as plt
from ARIMA_Model import arima_model
from Plot_Models import plot_models
from Least_Squares import lest_squares
from Normalize_Regression import normalize_regression
from Sequences_Data import sequences_data
from Test_Stationary import test_stationary
from Auto_Correlation import auto_correlation
from Linear_Regression import linear_regression
from Xgboost_Regression import xgboost_regression
from keras import models, layers
from Random_Forest_Regression import random_forest_regression
from Tree_Decision_Regression import tree_decision_regression
# ======================================== Step 1: Load Data ==================================================
os.system('cls')
data = sm.datasets.sunspots.load_pandas() # df = pd.read_csv('monthly_milk_production.csv'), df.info(), X = df["Value"].values
data = data.data["SUNACTIVITY"]
# print('Shape of data \t', data.shape)
# print('Original Dataset:\n', data.head())
# print('Values:\n', data)
# ================================ Step 2.1: Normalize Data (0-1) ================================================
#data, normalize_modele = normalize_regression(data, type_normalize='MinMaxScaler', display_figure='on') # Type_Normalize: 'MinMaxScaler', 'normalize'
# ================================ Step 2.2: Check Stationary Time Series ========================================
#data = test_stationary(data, window=20)
# ==================================== Step 3: Find the lags of AR and etc models ==============================
#auto_correlation(data, nLags=10)
# =========================== Step 4: Split Dataset intro Train and Test =======================================
nLags = 3
num_sample = 300
mu = 0.000001
Data_Lags = pd.DataFrame(np.zeros((len(data), nLags)))
for i in range(0, nLags):
Data_Lags[i] = data.shift(i + 1)
Data_Lags = Data_Lags[nLags:]
data = data[nLags:]
Data_Lags.index = np.arange(0, len(Data_Lags), 1, dtype=int)
data.index = np.arange(0, len(data), 1, dtype=int)
train_size = int(len(data) * 0.8)
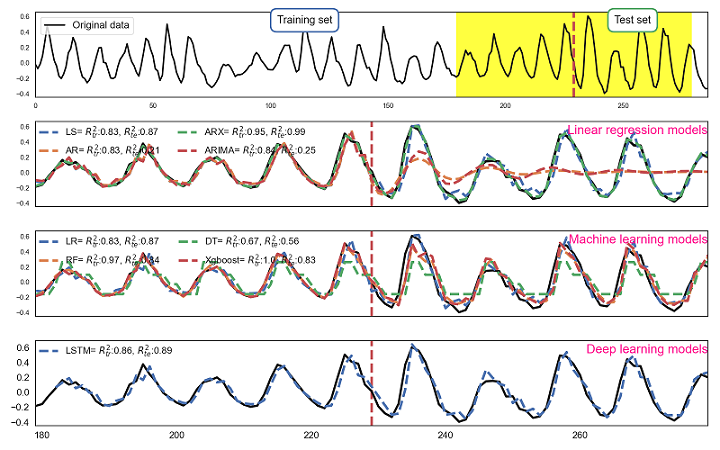
# ================================= Step 5: Autoregressive and Automated Methods ===============================
sns.set(style='white')
fig, axs = plt.subplots(nrows=4, ncols=1, sharey='row', figsize=(16, 10))
plot_models(data, [], [], axs, nLags, train_size, num_sample=num_sample, type_model='Actual_Data')
# ------------------------------------------- Least Squares ---------------------------------------------------
lest_squares(data, Data_Lags, train_size, axs, num_sample=num_sample)
# -------------------------------------------- Auto-Regressive (AR) model --------------------------------------
ar_model(data, train_size, axs, n_lags=nLags, num_sample=num_sample)
# ------------------------------------------------ ARX --------------------------------------------------------
arx(data, Data_Lags, train_size, axs, mu=mu, num_sample=num_sample)
# ----------------------------- Auto-Regressive Integrated Moving Averages (ARIMA) -----------------------------
arima_model(data, train_size, axs, order=(5, 1, (1, 1, 1, 1)), seasonal_order=(0, 0, 2, 12), num_sample=num_sample)
# ======================================= Step 5: Machine Learning Models ======================================
# ------------------------------------------- Linear Regression Model -----------------------------------------
linear_regression(data, Data_Lags, train_size, axs, num_sample=num_sample)
# ------------------------------------------ RandomForestRegressor Model ---------------------------------------
random_forest_regression(data, Data_Lags, train_size, axs, n_estimators=100, max_features=nLags, num_sample=num_sample)
# -------------------------------------------- Decision Tree Model ---------------------------------------------
tree_decision_regression(data, Data_Lags, train_size, axs, max_depth=2, num_sample=num_sample)
# ---------------------------------------------- xgboost -------------------------------------------------------
xgboost_regression(data, Data_Lags, train_size, axs, n_estimators=1000, num_sample=num_sample)
# ----------------------------------------------- LSTM model --------------------------------------------------
train_x, train_y = sequences_data(np.array(data[:train_size]), nLags) # Convert to a time series dimension:[samples, nLags, n_features]
test_x, test_y = sequences_data(np.array(data[train_size:]), nLags)
mod = models.Sequential() # Build the model
# mod.add(layers.ConvLSTM2D(filters=64, kernel_size=(1, 1), activation='relu', input_shape=(None, nLags))) # ConvLSTM2D
# mod.add(layers.Flatten())
mod.add(layers.LSTM(units=100, activation='tanh', input_shape=(None, nLags)))
mod.add(layers.Dropout(rate=0.2))
# mod.add(layers.LSTM(units=100, activation='tanh')) # Stacked LSTM
# mod.add(layers.Bidirectional(layers.LSTM(units=100, activation='tanh'), input_shape=(None, 1))) # Bidirectional LSTM: forward and backward
mod.add(layers.Dense(32))
mod.add(layers.Dense(1)) # A Dense layer of 1 node is added in order to predict the label(Prediction of the next value)
mod.compile(optimizer='adam', loss='mse')
mod.fit(train_x, train_y, validation_data=(test_x, test_y), verbose=2, epochs=100)
y_train_pred = pd.Series(mod.predict(train_x).ravel())
y_test_pred = pd.Series(mod.predict(test_x).ravel())
y_train_pred.index = np.arange(nLags, len(y_train_pred)+nLags, 1, dtype=int)
y_test_pred.index = np.arange(train_size + nLags, len(data), 1, dtype=int)
plot_models(data, y_train_pred, y_test_pred, axs, nLags, train_size, num_sample=num_sample, type_model='LSTM')
# data_train = normalize.inverse_transform((np.array(data_train)).reshape(-1, 1))
mod.summary(), plt.tight_layout(), plt.subplots_adjust(wspace=0, hspace=0.2), plt.show()
注意:
1.所有代码均经过运行测试,没有问题。
2.拍前请仔细阅读作品简介,这非常重要,因为涉及到不同的编程语言(Python或matlab)。
3.程序为特殊商品,经售出不退,有问题请及时联系。
4.建议有一定Python或Matlab基础的同学或工程师购买。
5.该代码不讲解哦。