印章检测
1 概述
由于未找到印章目标检测的公开数据集及印章数据的敏感性,因为本文的印章数据均为测试使用的自动生成,本任务首先基于随机中文字符生成包含印章的word文档,然后将word转换为pdf,将pdf转换为图片,并使用labelme对图片进行标注,最后使用yolov5对印章进行检测
注意:由于是随机中文字符生成,因此图片中的文字都是乱编的,本实验的主要目的在于检测出印章的位置,因此文档的内容对此没有影响,所以本文使用随机字符生成数据,另外,如果希望本模型获得更好的泛化性能,需要为其添加自己希望检测的自定义数据集
- ▶️视频教程:http://www.codeborn.cn/videos/StampDetection.mp4
- 📨作者邮箱:<购买后查看>
- 检测效果:

2 软件安装
3 环境安装
- 创建虚拟环境,打开CMD,使用下述命令创建一个名为Stamp的虚拟环境,python版本为3.9.19
conda create -n Stamp python=3.9.19
- 激活环境:
conda activate Stamp
- 安装深度学习框架Torch:
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch
注意:在安装的过程中上述安装命令只能运行一次,如果想重新安装,请使用pip uninstall torch和conda uninstall torch先将其卸载再重装,否则在运行会出现冲突错误
如果自己能够掌握显卡和Torch的对应关系,也可以自行查看对应版本的下载情况,更推荐使用pip进行下载,查看链接为:https://pytorch.org/get-started/previous-versions/
- 首先cd到项目根目录,根据自己实际情况修改:
cd D:\projects\Stamp_detection
- 安装项目所需要的所有依赖包:
pip install -r requirement.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
4 使用
- 使用下述命令进行检测:
python detect.py --weights runs/train/exp/weights/best.pt --source dataset/Stamp/images/3.png
5 自定义训练
5.1 数据集准备
- 直接运行dataset/generate_stamp_word.py会在dataset/word中生成很多带有印章的word文件
- 直接运行dataset/convert_doc2img.py会将dataset/word中的word文件生成pdf和png,分别保存在dataset/pdf和dataset/images下
- 使用labelme标注工具对自己图片中的类别进行标记(印章数据集只有一个类别,即印章),标记的时候记得将标记的json文件保存到datasets/labels_json下,等待全部图像标记完成后,打开dataset/convert_dataset.py,更改其中的以下参数:
json_base_dir = "./labels_json" # 输入的json文件夹路径你
output_label_dir = "./labels" # 输出的label(txt)路径
- 将上述参数更改以后,运行这个文件,会自动在labels下生成对应的txt文件
5.2 训练
- 完成数据集准备后,会在dataset/images和dataset/labels下生成对应的图片和标签,然后将其按照8:2分别复制到dataset/Stamp/train/images与 dataset/Stamp/train/labels下,以及dataset/Stamp/val/labels和dataset/Stamp/val/labels下,和项目中的目录一致
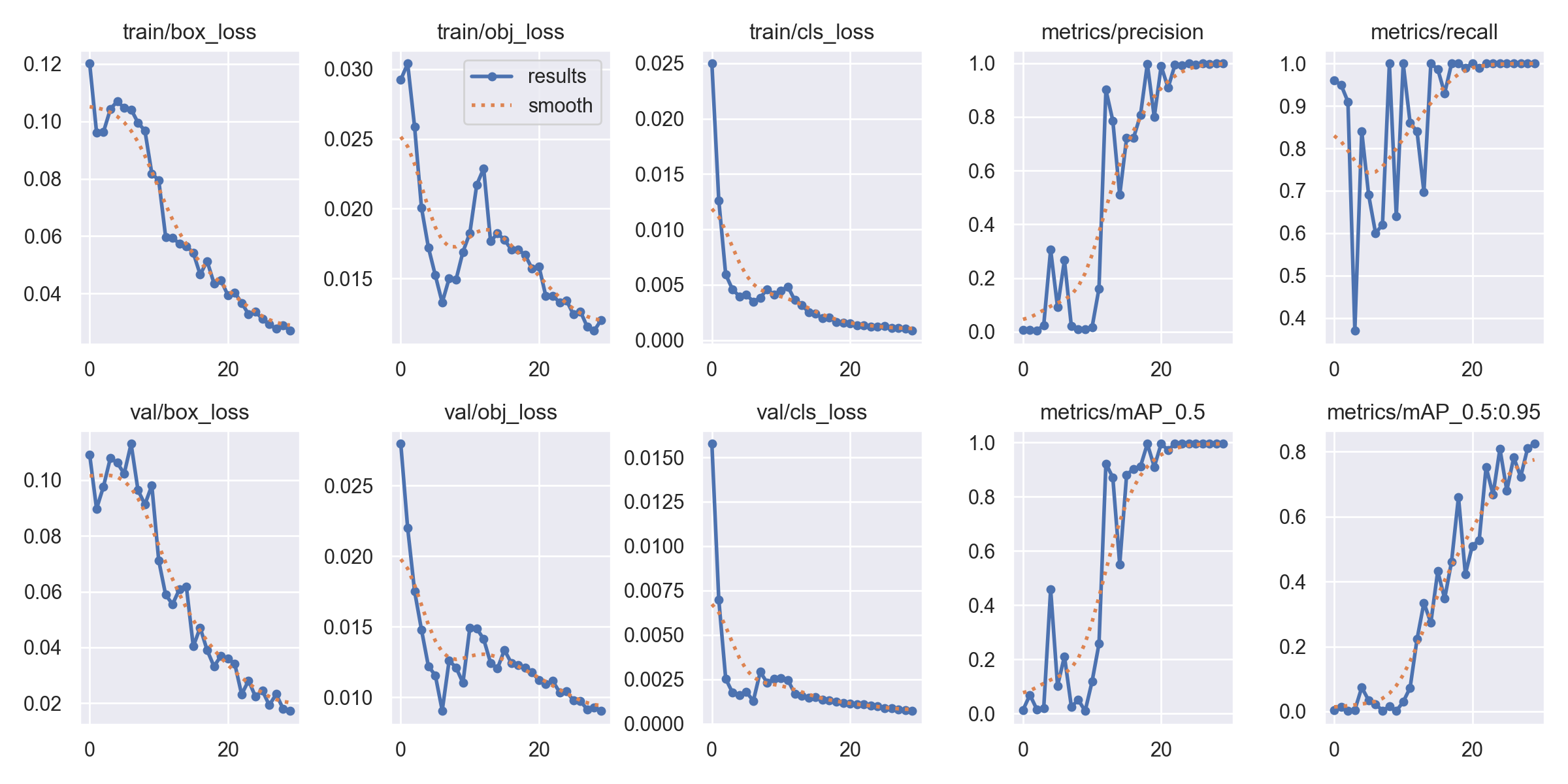
- 使用下述命令即可开启训练,训练的文件会保存在runs下
python train.py --data stamp.yaml --weights yolov5s.pt --img 640 --batch-size 4 --epochs 30
5.3 检测
- 上述训练完成后,找到最新的训练权重文件,即exp1或exp2,数字大代表着其是最近的训练,选择最近训练的权重文件,替换掉下述的参数weights参数,检测命令:
python detect.py --weights runs/train/exp/weights/best.pt --source dataset/Stamp/images/1.png
6 结果