本项目实现了对甲骨文的识别,其中主要的代码在jiaguwen项目下面,数据集爬取代码文件夹里面是爬取数据集的爬虫代码。
在jiaguwen项目下datasets下面是数据集,分为训练集和测试集,每个文件夹的子文件夹里面的所有图片代表同一个字的甲骨文。
model.py是构建的模型
train.py是训练代码
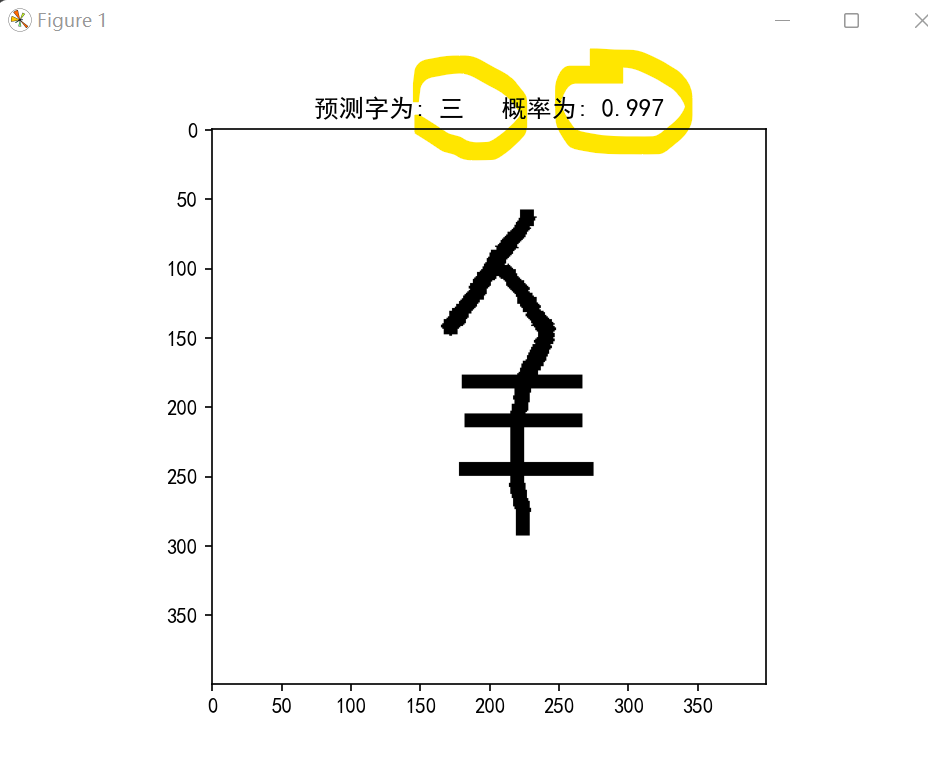
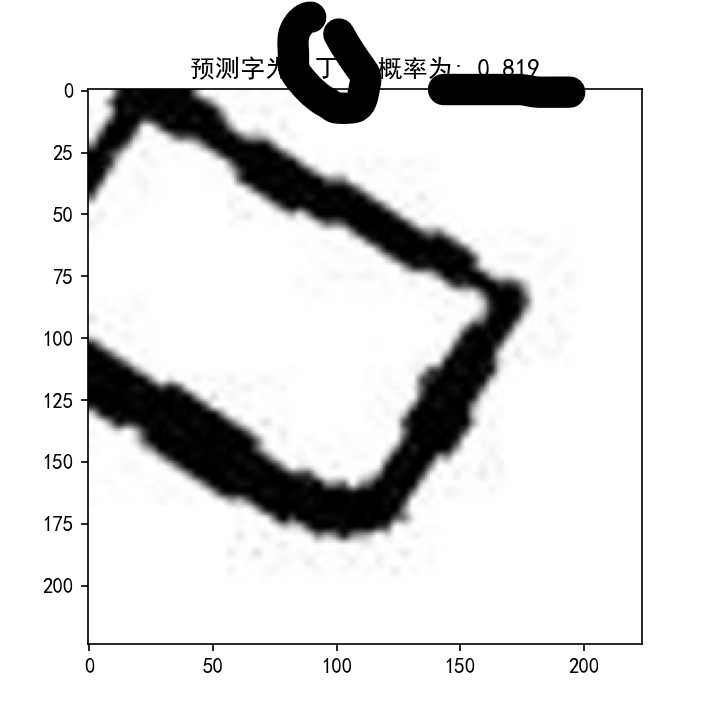
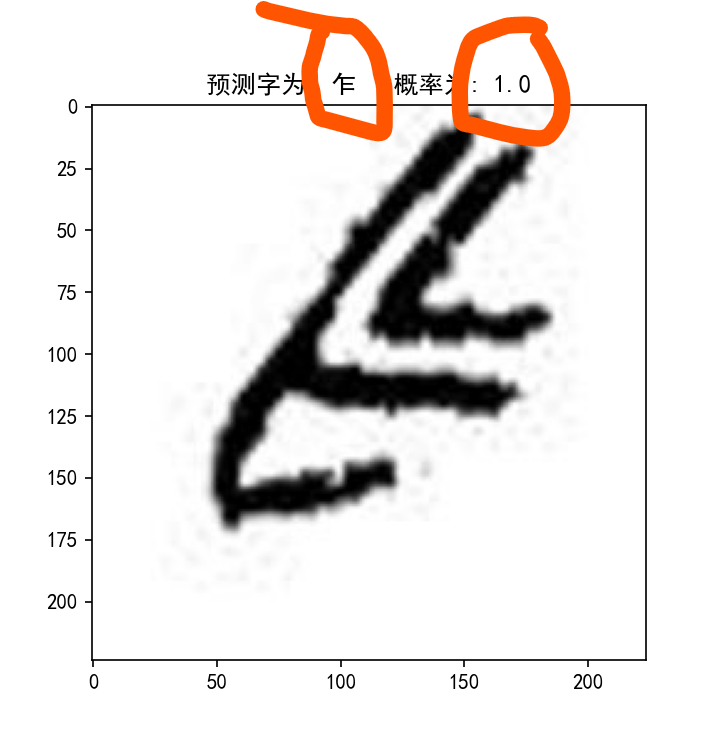
predict.py是测试单张图片并显示结果的代码,可修改相应的图片路径进行测试
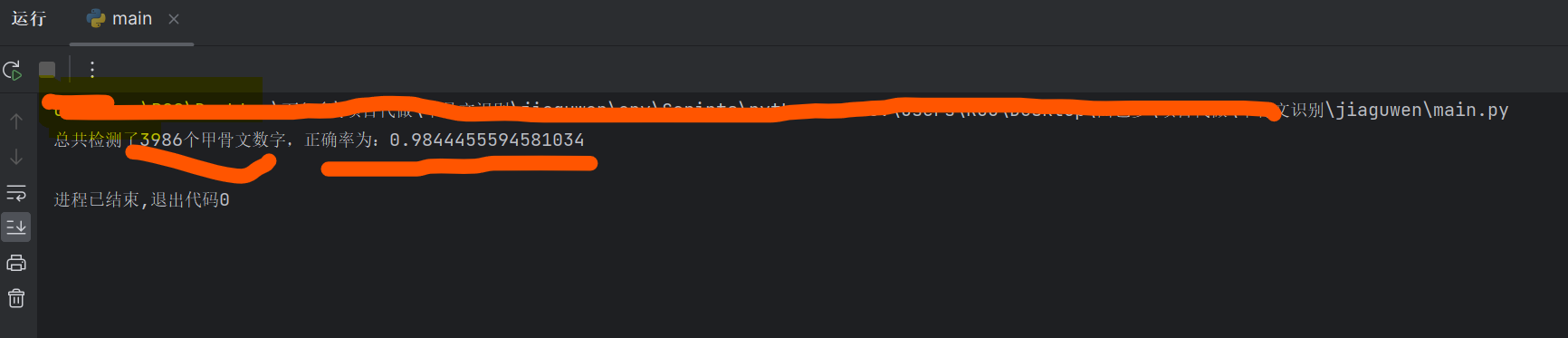
main.py是测试多张甲骨文图片并统计结果的代码
我预训练好的98%以上准确率的模型在results文件夹下
部分检测效果如下: