我想要让 ChatGPT 做这些事:
- 给它一份 PDF,让它分析摘要、提炼内容;
- 让它去看某个网页,帮我查询最新的信息;
- 给它一份数据表格,让它分析出数据的变化;
- 给它一份文本,让它总结、模仿出相似的风格;
- 给它一个聊天记录,让它把你的好友进行分类和打标签;
- 给它一本书,让它快速读完,并且告诉我书里都讲了什么....
是不是觉得,哇,原来 ChatGPT 还能做这些?
为什么自己在使用 ChatGPT 时没发现这些功能?
这些动作,都离不开一个动作:投喂。
相信你在 ChatGPT 的使用中,也遇到过相似的问题。
这阻碍了你很多自媒体创作进程,如何解决上面的问题呢?我们今天来谈谈投喂。
今天的分享将主要分为:
一、为什么要喂资料给它?
二、都能喂给它哪些格式的资料?
三、它吃掉资料后,是怎么进行工作的
四、投喂的方式和方法
五、如何输出想要的结果/提问和设定
一、为什么要为资料给它?
我们知道,ChatGPT 本身的公开数据库更新到 21 年 9 月,4.0 版本最近也支持了联网插件。
但是,我们想要使用 ChatGPT 分析的数据/文本往往存在两种状况:
1、这是私人数据,未被公开,ChatGPT 没有
2、这是联网公开内容,但是未被 ChatGPT 收录
也就是说,并非我们询问的问题资料都在 ChatGPT 的数据库中,因此我们需要教它。
家里来了一个机器人,还不会使用洗碗机。
你把洗碗机的使用手册投喂给他,它就能迅速掌握这些知识。
不但可以立刻帮你洗碗,还能针对洗碗机的原理、构造和你侃侃而谈。
为了让 ChatGPT 更能明白我们的指令,我们有必要进行知识投喂。
甚至我们畅想,未来我们每个人脖子上也有一个接口,可以接受这样的知识投喂。
数据传输后,我们迅速掌握了这些知识,再也不用死记硬背。
二、都能喂给它哪些格式的资料?
1、投喂这些资料都支持什么格式?
原则上:各种电子书或者文档都可以,pdf、excel、ppt、word...统统没问题。
也就是说:只要是文本,都 ok。
比如:图像、图片形式的内容,我们也可以通过 ocr 转换成文本,投喂进去。
比如:短视频的内容,你可以通过飞书妙记把视频转为文字,投喂进去。
比如:公众号、网页里的内容,只要是文本,也可以直接复制投喂进去。
2、投喂有没有限制?
文件的大小:
理论上文件大小没有限制。
难点不在大小,而在于如何对长文档进行处理,切分。
比如你喂了 1M 的文件,它很快可以处理完并协同你工作。
你喂了 30M 的文本,半天过后它仍然在分析文档……
ChatGPT 网页版对话的长度:
受限于 OpenAI 接口对 token 数量的限制,最常用、也最廉价的 ChatGPT 3.5 的 token 限制是 4096 tokens,可以简单粗暴的认为是 2000 字。
超过了会怎样?网页会直接提示红字超过token限制,需要把字数控制在2000字以内。
三、它吃掉资料后,是怎么进行工作的
注意:这个部分涉及原理,非开发人员请远离。
【普通用户可以出去溜达一会儿,到第四个章节你们再回来】
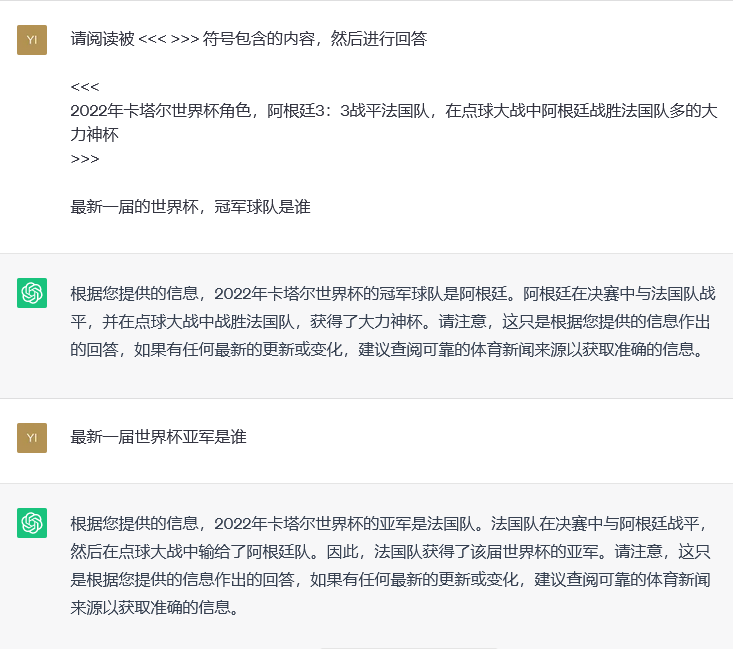
在 ChatGPT 界面中,我们可以尝试使用如下的方式进行数据的投喂
我们通过在对话中提供更多的信息,来实现最简单的数据投喂
如果是更多的内容则很难、无法在对话框中进行投喂。此时我们需要别的方式来进行处理:
finetuning是捏了个小人,会自主回答。
embedding就是做了个说明书,只回答说明书里边有的,没有回答不了。
一个非常发散,一个则更加收敛。
这种方式是在 OpenAI 训练的模型之上,使用自己的小数据集来进行微调。这种方式会让模型在特定的领域(取决于数据集)成为专家。但是训练的效果需要不断的去检验,而且检验的数据集也必须覆盖面很大。
例如使用这种方式训练出来的:
提问:我们家的到家月嫂和别人家的月嫂有什么不一样?
它回答:
到家月嫂是一个纯洁的工作
你会觉得???嗯?什么意思?它说这话是什么意思?怎么还能联想到那里!
这就是典型的发散型回答。
Embedding
Embedding 是对文本进行向量化处理,从而对两端文本可以进行向量比较,获取两端文本的相似性。
通过这种方式,就可以把长文本切分成小块(Chunk),通过对用户问题的命中来选取相应的内容,然后交给 ChatGPT 进行后续处理。
如,汉堡的向量和三明治的向量相似性,就要大于和桌子的向量相似性。
如一段文本是,“我家快递用顺丰”,这句话就和“你家物流用什么”这个问题具有强相似性。
所以这种方式也往往用于在线客服的开发。
一般工具的处理方式(粗)
大量的工具如 ChatPDF,都是使用 embedding 的方式进行处理,处理的流程为
1.用户输入长文本,工具对长文本按照策略切分成为文本块
2.对每一个文本块进行向量计算(Embedding)并存储到向量数据
3.用户提问进行向量计算
4.从向量数据看寻找和用户提问相似度最高的内容
5.整合命中的内容,连同用户的问题,调用 OpenAI Chat 接口进行处理
6.返回用户回答
好了,枯燥的原理部分我们说完了。乡亲们可以回来了!