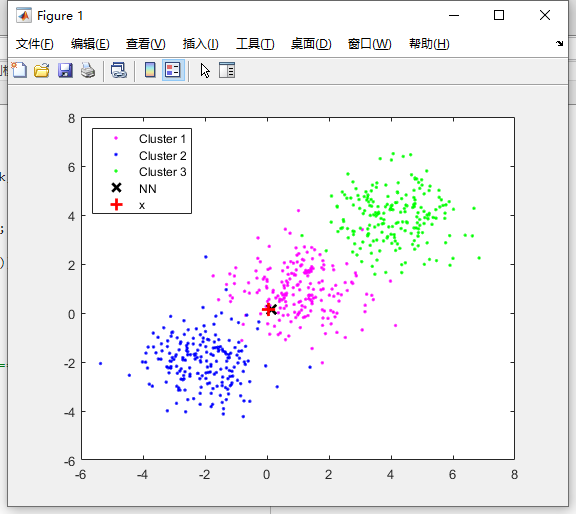
主要步骤:
数据准备阶段:
1. 生成合成数据集 `X`。
2. 定义聚类层数 `L` 和每个层次的子集数量 `l`。
聚类阶段:
1. 对数据集进行 K 均值聚类。
2. 存储每个簇的数据点、中心点和半径。
树搜索阶段:
1. 初始化参数,如待判定样本 `x`、阈值 `B`、当前层数 `CurL` 和节点指针 `p`。
2. 在循环中,从当前节点的子节点中选择一个最有可能的节点。
3. 如果当前节点是叶子节点,则检查是否有更近的邻居点。
4. 如果当前节点不是叶子节点,则进入下一层继续搜索。
输出结果:
输出最近邻点 `Xnn` 和其索引。