摘要
本文基于最新的基于深度学习的目标检测算法 (YOLOv5、YOLOv6、YOLOv8)以及YOLOv9) 对头盔数据集进行训练与验证,得到了最好的模型权重文件。使用Streamlit框架来搭建交互式Web应用界面,可以在网页端实现模型对图像、视频和实时摄像头的目标检测功能,在网页端用户可以调整检测参数(IoU、检测置信度等)。本数据集标注了行人头盔目标,且已转换成YOLO格式的标注文件。本博文介绍了完整的YOLO算法综述、数据集介绍、关键技术解析以及系统功能演示
环境搭建
l 打开Anaconda prompt (管理员打开)
l 进入项目目录:cd xxxxxxxx (如果在非c盘,需要先f: (以f盘为例))
l 创建一个conda虚拟环境:conda create -n st python=3.10
l 进入虚拟环境:conda activate st
l 安装依赖环境:pip install -r requirements.txt、
l 登录时默认的用户名为111,密码也为111

项目打开:(无登录界面,默认使用CPU检测):streamlit run app.py
(无登录界面,默认使用GPU检测):streamlit run app_gpu.py
(有登录界面,默认使用CPU检测):streamlit run login.py
(有登录界面,默认使用GPU检测):streamlit run login_gpu.py
YOLO算法综述
YOLO(You Only Look Once)系列算法是一系列用于实时目标检测的深度学习算法,由Joseph Redmon等人开发。该系列算法的主要思想是将目标检测问题转化为单一的回归问题,通过一个神经网络直接从整幅图像中输出目标的类别和边界框坐标,从而实现快速准确的目标检测。YOLO系列算法的主要版本包括YOLO、YOLOv2、YOLOv3、YOLOv4、YOLOv5、YOLOv6、YOLOv7、YOLOv8和YOLOv9等,每个版本都在前一版本的基础上进行了改进和优化,以提高检测精度和速度。下面将详细介绍每个版本的特点和改进。
l YOLO(You Only Look Once):它将目标检测问题转化为一个单一的回归问题,并通过一个卷积神经网络直接输出目标的类别和边界框坐标。YOLO将图像分割为 S × S 个格子(grid),每个格子负责检测该格子内的目标,并输出目标的类别概率以及边界框的位置信息。由于采用单一网络直接输出结果,YOLO在速度上具有优势,但在小目标检测和定位精度上存在一定问题。
l YOLOv2:YOLOv2在YOLO的基础上进行了改进和优化,主要包括使用更深的网络结构(Darknet-19)、采用多尺度预测和Anchor Boxes等技术。多尺度预测可以提高模型对不同尺度目标的检测能力,Anchor Boxes可以更好地适应不同形状的目标,并提高定位精度。此外,YOLOv2还引入了批标准化(Batch Normalization)和卷积替代池化(Convolutional With Pooling)等技术来提高模型的训练速度和精度。
l YOLOv3:YOLOv3在YOLOv2的基础上进一步改进,主要包括引入残差网络(ResNet)作为主干网络、采用多尺度预测以及使用更细粒度的Anchor Boxes等技术。引入ResNet可以提高模型的特征提取能力,多尺度预测可以进一步提高模型对不同尺度目标的检测能力,使用更细粒度的Anchor Boxes可以提高模型的定位精度。此外,YOLOv3还采用了特征融合和跨尺度连接等技术来提高模型的检测性能。
l YOLOv4:YOLOv4是YOLO系列算法的最新版本,它在YOLOv3的基础上进行了进一步的改进和优化,主要包括引入更深更宽的网络结构(CSPDarknet53)、采用更多的数据增强和正则化技术以及使用更大的Batch Size等。CSPDarknet53是一种全新的网络结构,可以提高模型的特征提取能力和泛化能力,更多的数据增强和正则化技术可以进一步提高模型的鲁棒性和泛化能力,使用更大的Batch Size可以提高模型的训练速度和稳定性。此外,YOLOv4还引入了模型融合和跨域训练等技术来进一步提高模型的检测性能。
l YOLOv5:YOLOv5 是由ultralytics团队开发的目标检测算法,通过简化模型结构和优化训练流程,实现了更快的训练速度和更高的检测精度。YOLOv5采用了CSPDarknet53作为骨干网络,采用了CSP(Cross Stage Partial)结构,提高了模型的效率和准确性。YOLOv5引入了自适应训练策略,可以根据硬件资源自动调整训练超参数,提高了模型的泛化能力。YOLOv5具有多尺度训练和推理的能力,可以在不同大小的目标上取得良好的检测效果。
l YOLOv6:YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用。本框架同时专注于检测的精度和推理效率,在工业界常用的尺寸模型中:YOLOv6-nano 在 COCO 上精度可达 35.0% AP,在 T4 上推理速度可达 1242 FPS;YOLOv6-s 在 COCO 上精度可达 43.1% AP,在 T4 上推理速度可达 520 FPS。在部署方面,YOLOv6 支持 GPU(TensorRT)、CPU(OPENVINO)、ARM(MNN、TNN、NCNN)等不同平台的部署,极大地简化工程部署时的适配工作。
l YOLOv7:YOLOv7是一种优秀的端到端检测算法。YOLOv7由Alexey Bochkovskiy和Chien-Yao Wang等人(YOLOv4团队)于2022年提出。在 5 FPS 到 120 FPS 的范围内,YOLOv7 的速度和准确性都超过了所有已知的物体检测器,在 30 FPS 的所有已知实时物体检测器中,YOLOv7 的准确性最高,达到 56.8% AP。
l YOLOv8:YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本。是一款强大、灵活的目标检测和图像分割工具,它提供了最新的 SOTA 技术。提供了一个全新的SOTA模型。基于缩放系数也提供了N/S/M/L/X不同尺度的模型,以满足不同部署平台和应用场景的需求;网络结构上引入C2F和SPPF模块,并对不同尺度的模型进行了精心微调,提升网络特征提取能力及模型性能的同时,平衡模型的推理速度;采用Anchor-Free代替Anchor-Based,对网络输出头进行解耦,分离类别预测和目标框的回归,同时去掉置信度分支;采用TaskAlignedAssigner 动态正样本分配策略,提高样本的生成质量;引入了 Distribution Focal Loss用于目标框的回归。
l YOLOv9:YOLOv9引入了程序化梯度信息(Programmable Gradient Information, PGI),这是一种全新的概念,旨在解决深层网络中信息丢失的问题。传统的目标检测网络在传递深层信息时,往往会丢失对最终预测至关重要的细节,而PGI技术能够保证网络在学习过程中保持完整的输入信息,从而获得更可靠的梯度信息,提高权重更新的准确性。这一创新显著提高了目标检测的准确率,为实时高精度目标检测提供了可能。此外,YOLOv9采用了全新的网络架构——泛化高效层聚合网络(Generalized Efficient Layer Aggregation Network, GELAN)。GELAN通过梯度路径规划,优化了网络结构,利用传统的卷积操作符实现了超越当前最先进方法(包括基于深度卷积的方法)的参数利用效率。这一设计不仅提高了模型的性能,同时也保证了模型的高效性,使YOLOv9能够在保持轻量级的同时,达到前所未有的准确度和速度。在MS COCO这样的挑战性数据集上的验证结果显示,YOLOv9在目标检测领域设置了新的性能基准,无论是在效率、速度还是准确性方面,YOLOv9都展示了卓越的性能
实验数据集
本系统使用的头盔行人数据集手动标注了头盔和行人这两个类别,数据集总计1100张图片。该数据集中类别都有大量的旋转和不同的光照条件,有助于训练出更加鲁棒的检测模型。本文实验的头盔行人检测识别数据集包含训练集887张图片,验证集213张图片。
关键技术
Streamlit
Streamlit 是一个开源应用程序框架,旨在简化为机器学习和数据科学构建 web 应用程序的过程。近年来,它在应用 ML 社区中获得了很大的吸引力。 Streamlit 成立于 2018 年,是前谷歌工程师在部署机器学习模型和仪表盘时遇到的挑战所带来的挫折。使用 Streamlit 框架,数据科学家和机器学习实践者可以在几个小时内构建自己的预测分析 web 应用程序。不需要依赖前端工程师或 HTML 、 CSS 或 Javascript 知识,因为这一切都是用 Python 完成的。一个简单的Streamlit初始界面如下图所示。
Streamlit的官方Github仓库:https://github.com/streamlit/streamlit
Streamlit的官方文档:https://streamlit.io/
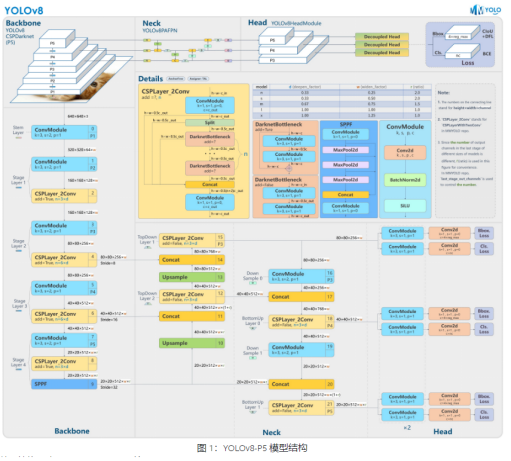
YOLOv8
YOLOv8 是 Ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,在还没有开源时就收到了用户的广泛关注。YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。总而言之,Ultralytics 开源库的两个主要优点是:(1)融合众多当前 SOTA 技术于一体;(2)未来将支持其他 YOLO 系列以及 YOLO 之外的更多算法
YOLOv8 算法的核心特性和改动可以归结为如下:
l 提供了一个全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于 YOLACT 的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
l 骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是无脑一套参数应用所有模型,大幅提升了模型性能。不过这个 C2f 模块中存在 Split 等操作对特定硬件部署没有之前那么友好了
l Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从 Anchor-Based 换成了 Anchor-Free
l Loss 计算方面采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss
YOLOv8官方Github:https://github.com/ultralytics/ultralytics
mmyolo官方参考资料:https://mmyolo.readthedocs.io/zh-cn/dev/recommended_topics/algorithm_descriptions/yolov8_description.html
YOLOv5
YOLOv5 是一个面向实时工业应用而开源的目标检测算法,受到了广泛关注。让 YOLOv5 爆火的原因不单纯在于 YOLOv5 算法本身的优异性,更多的在于开源库的实用和鲁棒性。简单来说 YOLOv5 开源库的主要特点为:
l 友好和完善的部署支持
l 算法训练速度极快,在 300 epoch 情况下训练时长和大部分 one-stage 算法如 RetinaNet、ATSS 和 two-stage 算法如 Faster R-CNN 在 12 epoch 的训练时间接近
l 框架进行了非常多的 corner case 优化,功能和文档也比较丰富
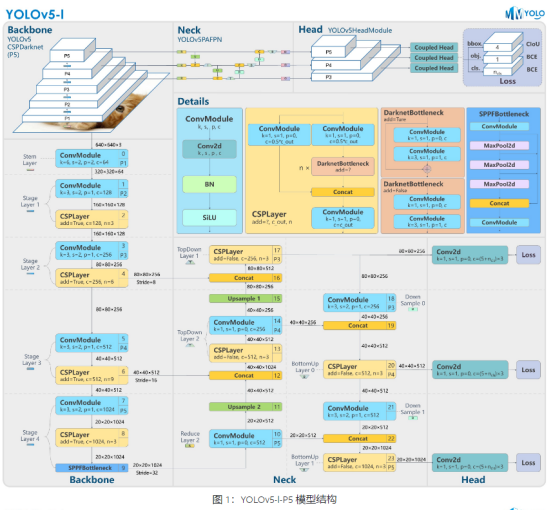
其他变体配置(n、s、m、x)与YOLOv5-l结构相同,唯一区别是模块数量与通道数
YOLOv5官方GitHub:https://github.com/ultralytics/yolov5
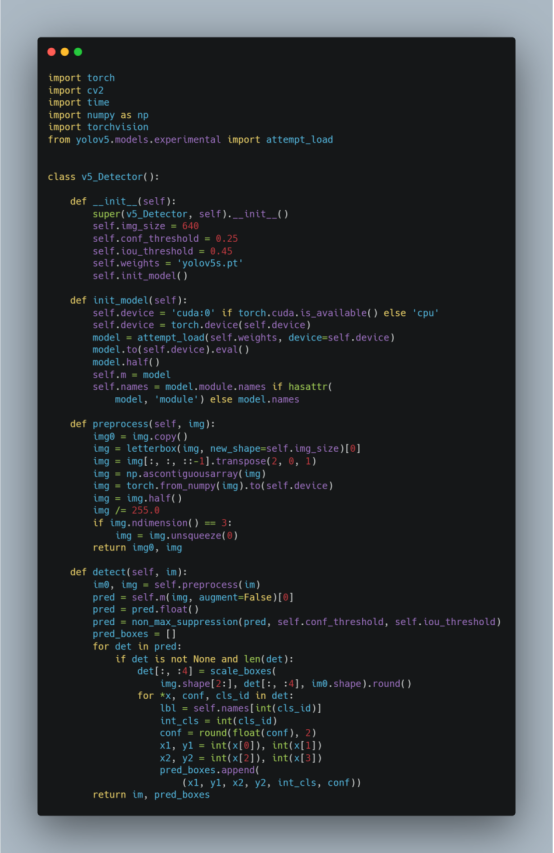
YOLOv5封装成一个类:
YOLOv9
摘要:当今的深度学习研究主要关注设计最佳目标函数,以实现模型预测与真实值的高度一致性,并开发合适的架构以确保预测过程中信息的充分利用。然而,传统方法往往忽视了在特征提取和空间转换的多层处理过程中,输入数据可能遭受的信息损失问题。本研究深入探讨了深度网络中数据传递过程中的信息损失问题,特别是信息瓶颈和可逆函数的挑战。提出了一种新概念——可编程梯度信息(PGI),旨在解决深度网络处理复杂任务时遇到的信息变化挑战。通过PGI,可以在计算目标函数时保留完整的输入信息,从而提供准确的梯度信息以优化网络权重。进一步地,本文设计了一种创新的轻量级网络架构,即广义高效层聚合网络(GELAN),展示了PGI在提升轻量级模型性能方面的有效性。通过在MS COCO数据集上进行目标检测任务的实验验证,证明了GELAN在参数效率方面超越了依赖深度可分卷积的现有技术。PGI的适用性跨越从轻量级到大型模型,能够在无需大型预训练数据集的条件下,实现从头开始训练模型的性能优势。
PGI主要包括个组成部分,即主分支、辅助可逆分支以及多级辅助信息;PGI的推理流程仅涉及主分支,避免了额外推理成本的产生。这一设计精巧地应对了深度学习中的关键挑战,通过两个关键组件提升模型性能:
辅助可逆分支:引入此组件是为了解决随着网络深度增加而引发的信息瓶颈问题。这种信息瓶颈会干扰损失函数生成有效梯度的能力,辅助可逆分支通过保持信息流动的完整性来克服这一障碍
多级辅助信息:此部分旨在解决深度监督可能导致的误差累积问题,尤其是在拥有多个预测分支的结构和轻量级模型中。通过引入多级辅助信息,模型能够更有效地学习并减少误差传播
Generalized ELAN:GELAN是通过融合两个先进的网络设计理念——具有梯度路径规划能力的CSPNet和ELAN——而诞生的。这种设计致力于实现一个既轻量又快速且精确的网络架构,全面优化了网络性能和效率。在此基础上,研究者对ELAN的应用范围进行了扩展,使其不再局限于传统的卷积层堆叠方式,而是能够灵活地适配各种计算单元,显著提升了网络的通用性和适应性。
论文地址:https://arxiv.org/abs/2402.13616
Yolov9源代码:https://github.com/WongKinYiu/yolov9
系统界面及功能演示
l 系统登录与注册:包含用户注册、创建用户、重设密码登功能(默认的用户名为111,密码也为111)
l 登录后系统界面左侧可调整:选择模型、置信度、IoU、选择设备、是否保存检测结果、选择检测任务等功能
l 图像检测:点击Browse files按钮上传本地图像(图像和项目路径下不要出现中文,为方便测试在项目的test_images目录下存放测试图片,在test_videos目录下存放测试视频),在项目的upload_files目录会保存用户上传的图片;之后点击开始检测按钮系统会自动检测图片,并在右侧显示检测后的结果,在上方显示测试相关信息,下方显示检测结果,用户可下载结果(默认下载格式为csv文件),系统会在saved_results保存结果图片
l 视频检测:点击Browse files按钮上传本地视频(图像和项目路径下不要出现中文,为方便测试在项目的test_images目录下存放测试图片,在test_videos目录下存放测试视频),在项目的upload_files目录会保存用户上传的视频;之后点击开始检测按钮系统会自动检测图片,并在右侧显示检测后的结果,在上方显示测试相关信息,下方显示检测结果,用户可下载结果(默认下载格式为csv文件),系统会在saved_results保存结果视频
l 摄像头检测:选择摄像头检测任务后,系统会自动打开本机摄像头并调用算法实时检测,系统会在saved_results保存结果视频
模型训练及结果
在实验结果与分析部分,我们使用精度和召回率等指标来评估模型的性能,还通过损失曲线和PR曲线来分析训练过程。在训练阶段,我们使用了前面介绍的数据集进行训练,使用了YOLOv8算法对数据集训练,总计训练了100个epochs。从下图可以看出,随着训练次数的增加,模型的训练损失和验证损失都逐渐降低,说明模型不断地学习到更加精准的特征。在训练结束后,我们使用模型在数据集的验证集上进行了评估,得到了以下结果。
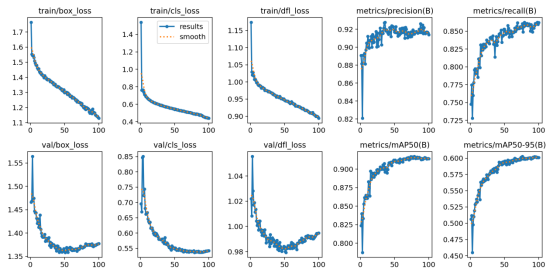
Ultralytics框架下的YOLOv8m模型的训练结果
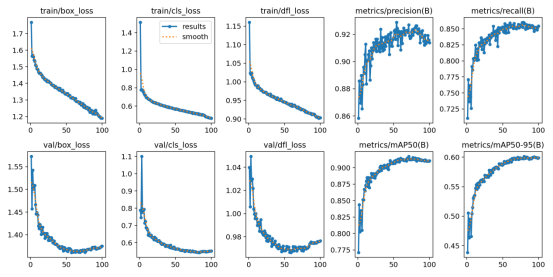
Ultralytics框架下的YOLOv5s模型的训练结果
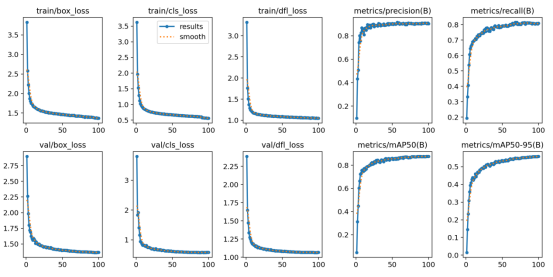
Ultralytics框架下的YOLOv6s模型的训练结果
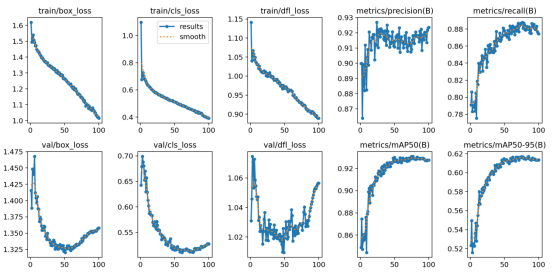
Ultralytics框架下的YOLOv9c模型的训练结果
综上,本博文训练得到的YOLOv8模型在数据集上表现良好,具有较高的检测精度和鲁棒性,可以在实际场景中应用。另外本博主对整个系统进行了详细测试,最终开发出一版流畅的高精度目标检测系统界面。另外本博文的PDF与更多的目标检测识别系统请关注笔者的微信公众号 BestSongC,在后台回复20240524来获取,后续会有更多的项目首发于该公众号。完整的UI界面、测试图片视频、代码文件等均已打包上传,感兴趣的朋友可从以下链接获取:。
完整项目目录如下所示

注意事项:
(1)注意:虚拟产品一经售出概不退款!
(2)版权所有,未经许可禁止转载及用于商业化用途