基于Transformer-BiGRUGlobalAttention-CrossAttention的并行预测模型!
● 基于Transformer多头注意力机制和并行计算能力!
● 基于全局注意力机制GlobalAttention优化的BiGRU!
● 基于交叉注意力融合时空特征!
● 环境框架:python 3.9 pytorch 1.8 及其以上版本均可运行
● 使用对象:论文需求、毕业设计需求者
● 代码保证:代码注释详细、即拿即可跑通。
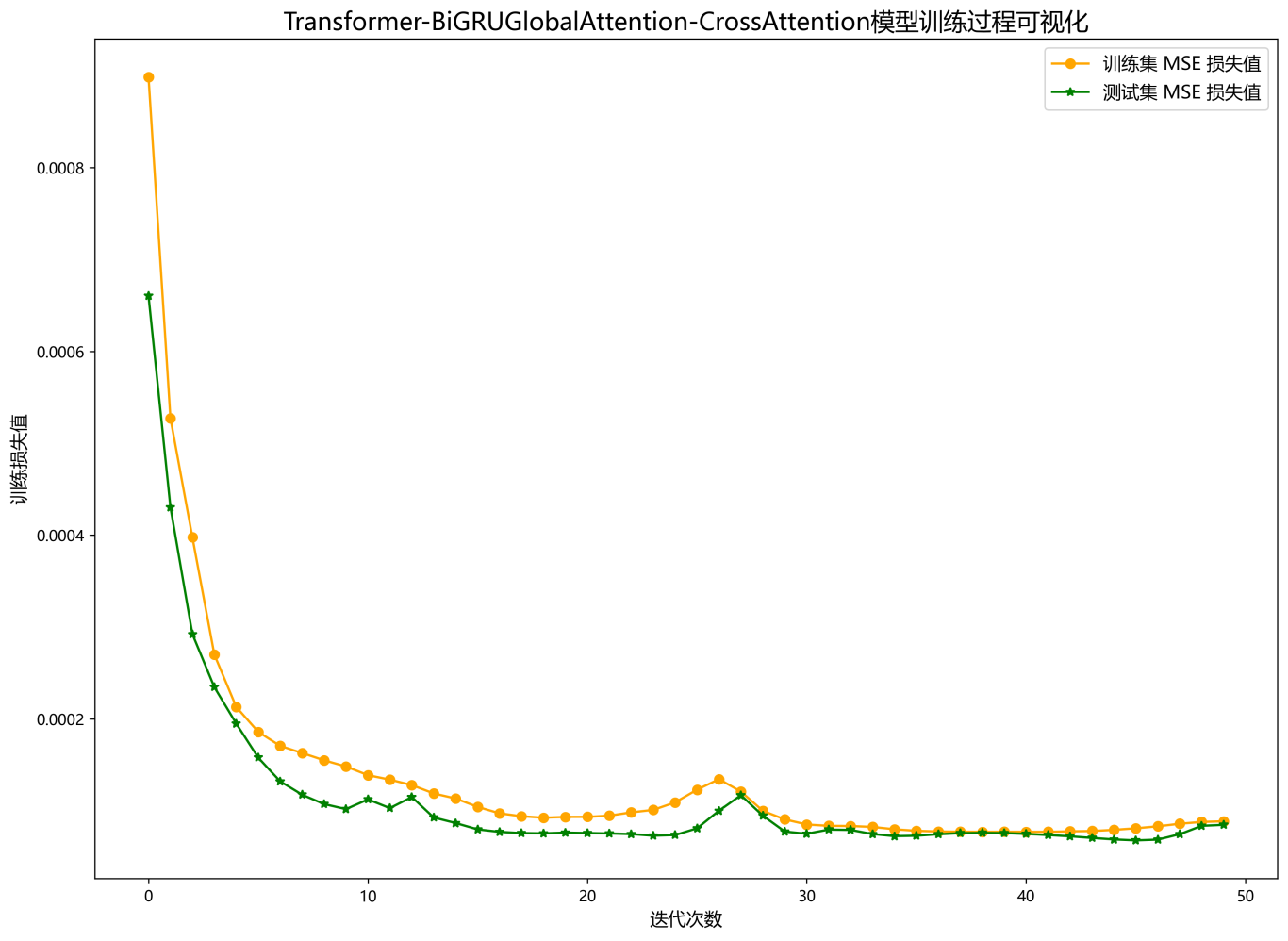
50个epoch, 训练误差极小 , 多变量特征序列Transformer-BiGRUGlobalAttention-CrossAttention
并行融合网 络模型 预测效果显著 ,模型能够充分提取时间序列的空间特征和时序特征,收敛速度快,性能优越,预测精度高,能够从序列时空特征中提取出对模型预测重要的特征,效果明显!创新度也有!!!
环境:python 3.9 pytorch 1.8 及其以上都可以
任何环境安装或者代码问题,请联系作者沟通交流,对于购买者,作者免费解决后续问题,关注微信公众号[建模先锋],联系作者;
模型创新点还未发表, 有毕业设计或者发小论文需求的同学必看,模块丰富,创新度高,性能优越!
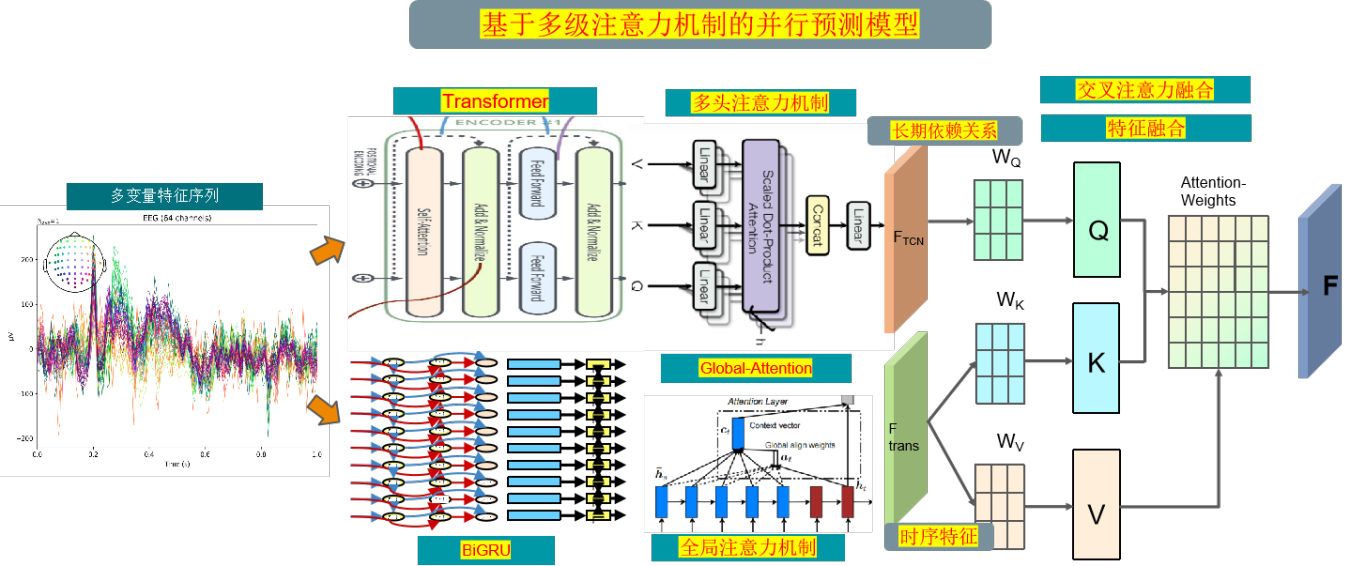
创新点:
1. 利用 Transformer 来提取序列中的长期依赖关系的时序特征,采用并行结构,加快模型的训练和推理速度,提高模型对关键信息的感知能力;
2.通过双向门控循环单元(BiGRU)同时从前向和后向对序列进行建模,以更好地捕获序列中的依赖关系,同时应用全局注意力机制GlobalAttention,对BiGRU的输出进行加权处理,使模型能够聚焦于序列中最重要的部分,提高预测性能;
3. 利用交叉注意力进行并行网络时空特征的融合,这样可以同时考虑时序关系和位置关系,从而更好地捕捉时空序列数据中的特征, 增强特征的表示能力来实现高精度的预测。
在多个数据集上表现出高精度的预测性能!
注意:此次产品,我们还有配套的模型讲解(方便学习网络结构)和参数调节讲解!


同时,代码配套精美的绘图与深度学习预测模型特征重要性可视化实现!
模型训练可视化图:
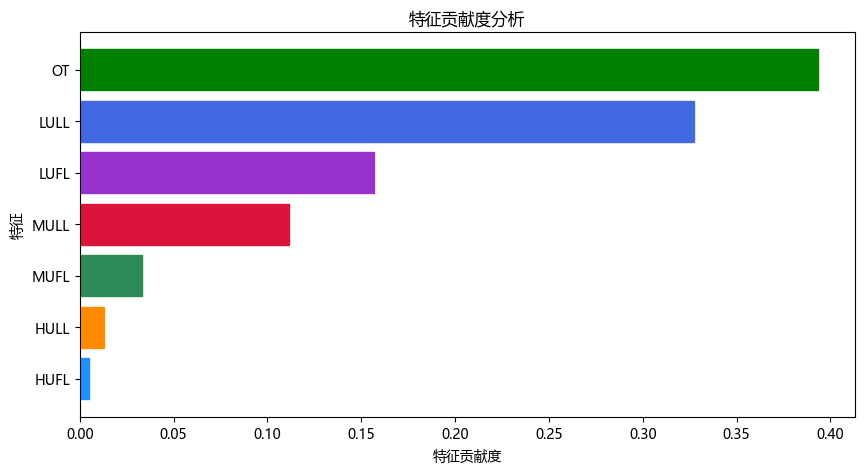
多特征贡献度可视化分析图:
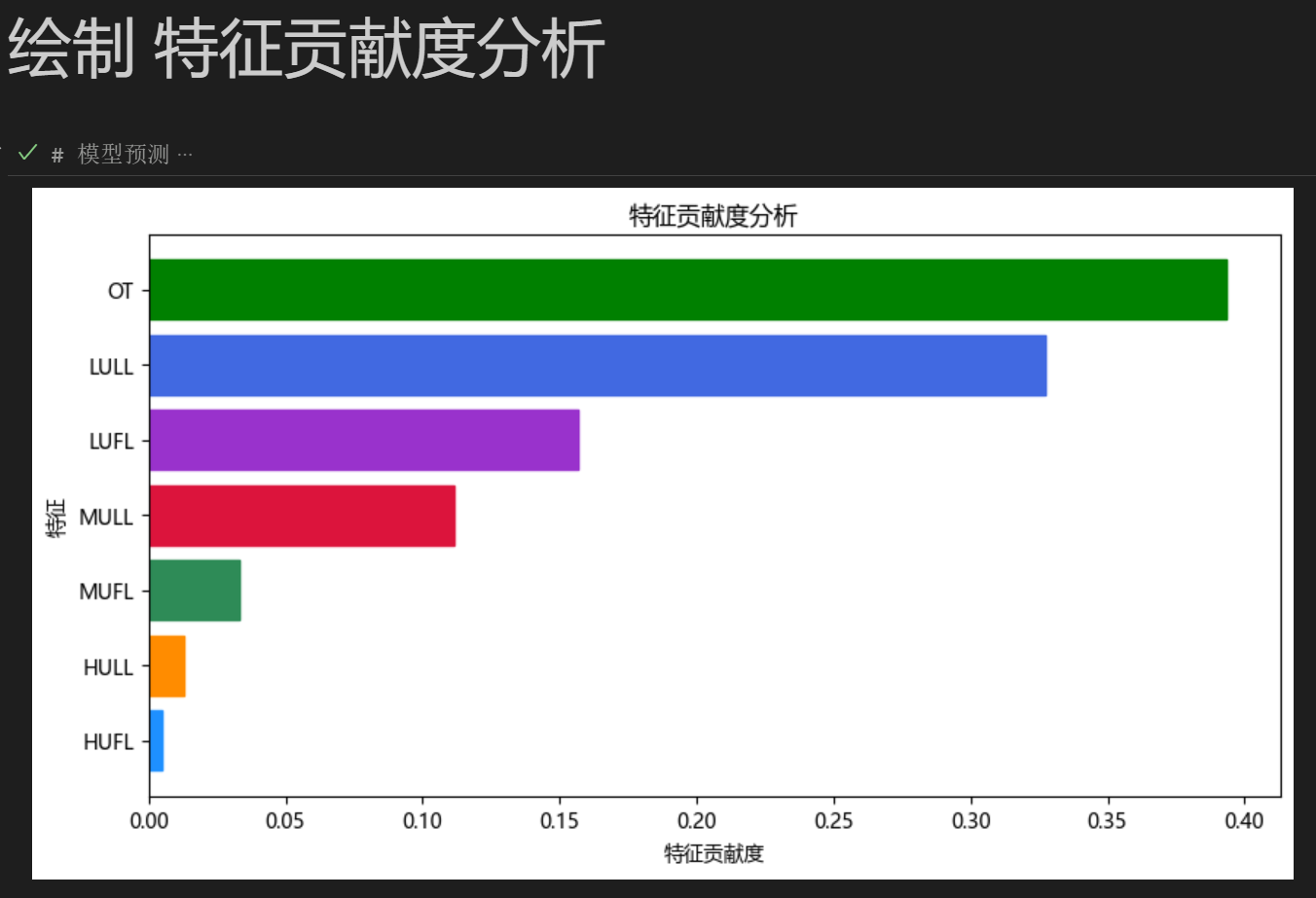
此分析代码是我们团队原创,如何利用 深度学习 训练好的模型 在对多特征预测任务 中进行特征重要性(贡献度)可视化!(也可以用于其他深度学习模型做特征重要性可视化,代码适用性高)
前言
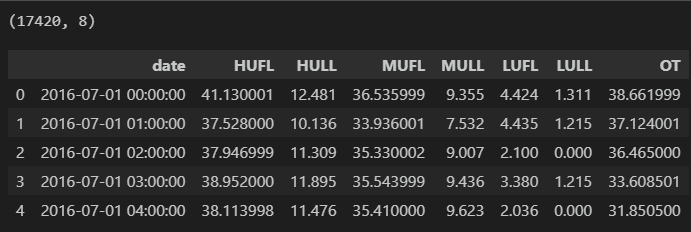
本文基于前期介绍的电力变压器( 文末附数据集 ),介绍一种基于Transformer-BiGRUGlobalAttention-CrossAttention并行预测模型,以提高时间序列数据的预测性能。 电力变压器数据集的详细介绍可以参考下文:
1 模型整体结构
模型整体结构如下所示,多特征变量时间序列数据先经过基于多头注意的Transformer编码器层提取长期依赖特征,同时数据通过基于GlobalAttention优化的BiGRU网络提取全局时序特征,使用交叉注意力机制进行 特征融合, 通过计算注意力权重 ,使得模型更关注重要的特征再进行特征增强融合,最后经过全连接层进行高精度预测。
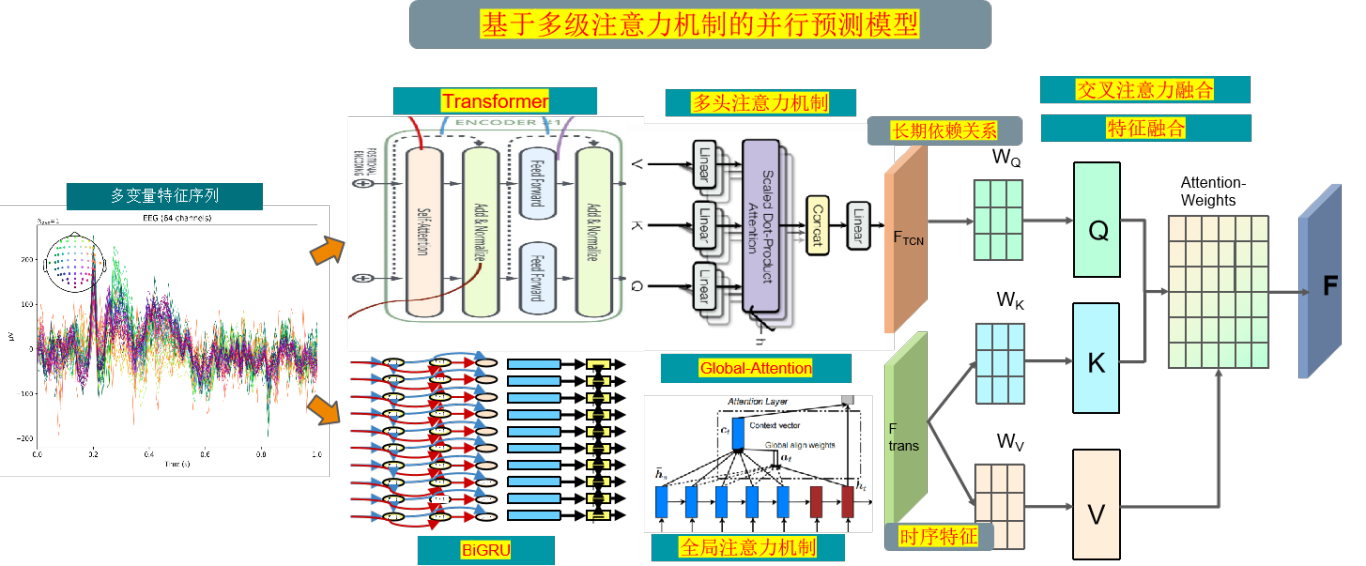
分支一:通过基于多头注意的Transformer编码器层模型,Transformer是一种基于自注意力机制的序列建模方法,通过注意力机制来建模序列中不同位置之间的依赖关系,能够捕捉序列中的全局上下文信息。Transformer是一种基于自注意力机制的序列建模方法,通过注意力机制来建模序列中不同位置之间的依赖关系,能够捕捉序列中的全局上下文信息。
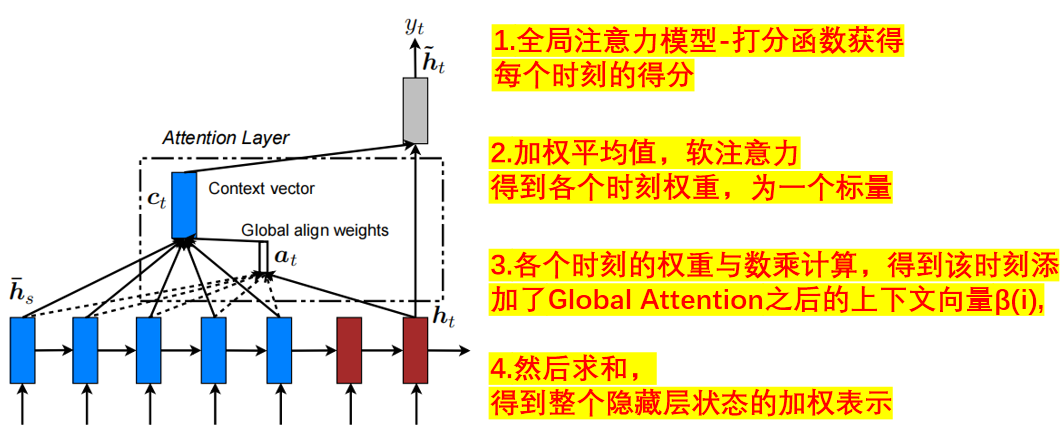
分支二:多特征序列数据同时通过基于GlobalAttention优化的BiGRU网络,GlobalAttention是一种用于加强模型对输入序列不同部分的关注程度的机制。在 BiGRU 模型中,全局注意力机制可以帮助模型更好地聚焦于输入序列中最相关的部分,从而提高模型的性能和泛化能力。在每个时间步,全局注意力机制计算一个权重向量,表示模型对输入序列各个部分的关注程度,然后将这些权重应用于 BiGRU 输出的特征表示,通过对所有位置的特征进行加权,使模型能够更有针对性地关注重要的时域特征, 提高了模型对多特征序列时域特征的感知能力;
并行预测:
- 模型采用并行结构,能够同时预测多个时间步的目标。
- 并行预测可以加快模型的训练和推理速度,并且能够充分利用时序数据中的信息,提高预测性能。
交叉注意力机制特征融合:使用交叉注意力机制融空间和时序特征,可以通过计算注意力权重,学习时空特征中不同位置之间的相关性,可以更好地捕捉时空序列数据中的特征,提高模型性能和泛化能力。
全局注意力机制:
Global Attention Mechanism
2 多特征变量数据集制作与预处理
2.1 导入数据
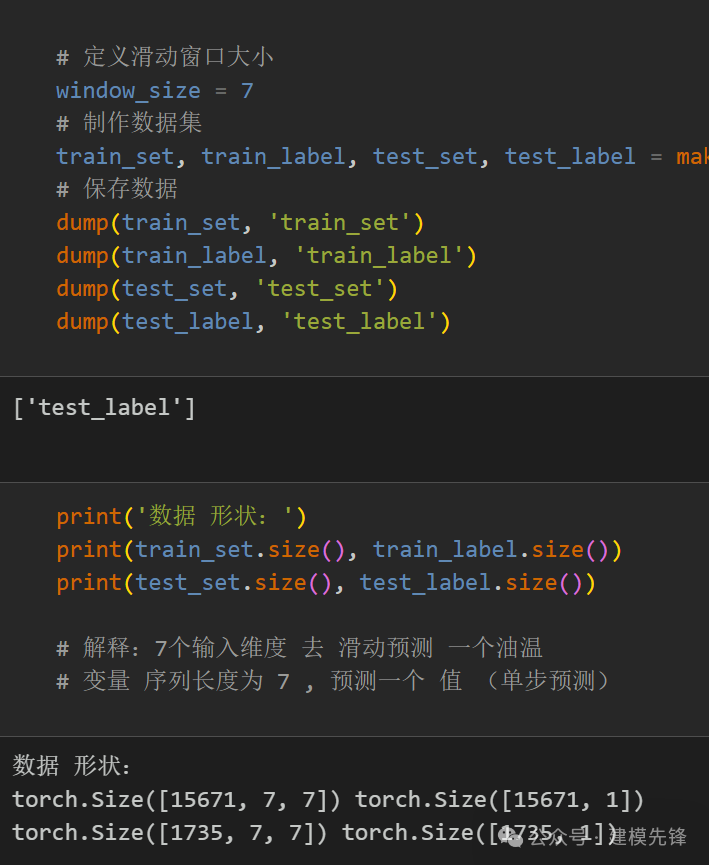
2.2 制作数据集
制作数据集与分类标签
3 交叉注意力机制
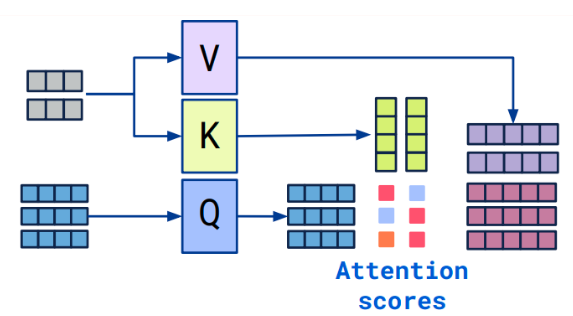
3.1 Cross attention概念
- Transformer架构中混合两种不同嵌入序列的注意机制
- 两个序列必须具有相同的维度
- 两个序列可以是不同的模式形态(如:文本、声音、图像)
- 一个序列作为输入的Q,定义了输出的序列长度,另一个序列提供输入的K&V
3.2 Cross-attention算法
- 拥有两个序列S1、S2
- 计算S1的K、V
- 计算S2的Q
- 根据K和Q计算注意力矩阵
- 将V应用于注意力矩阵
- 输出的序列长度与S2一致
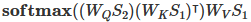
在融合过程中,我们将经过Transformer的时序特征作为查询序列,GlobalAttention优化的BiGRU提取的全局空间特征作为键值对序列。通过计算查询序列与键值对序列之间的注意力权重,我们可以对不同特征之间的关联程度进行建模。
4 基于多级注意力机制的并行高精度预测模型
4.1 定义 网络模型
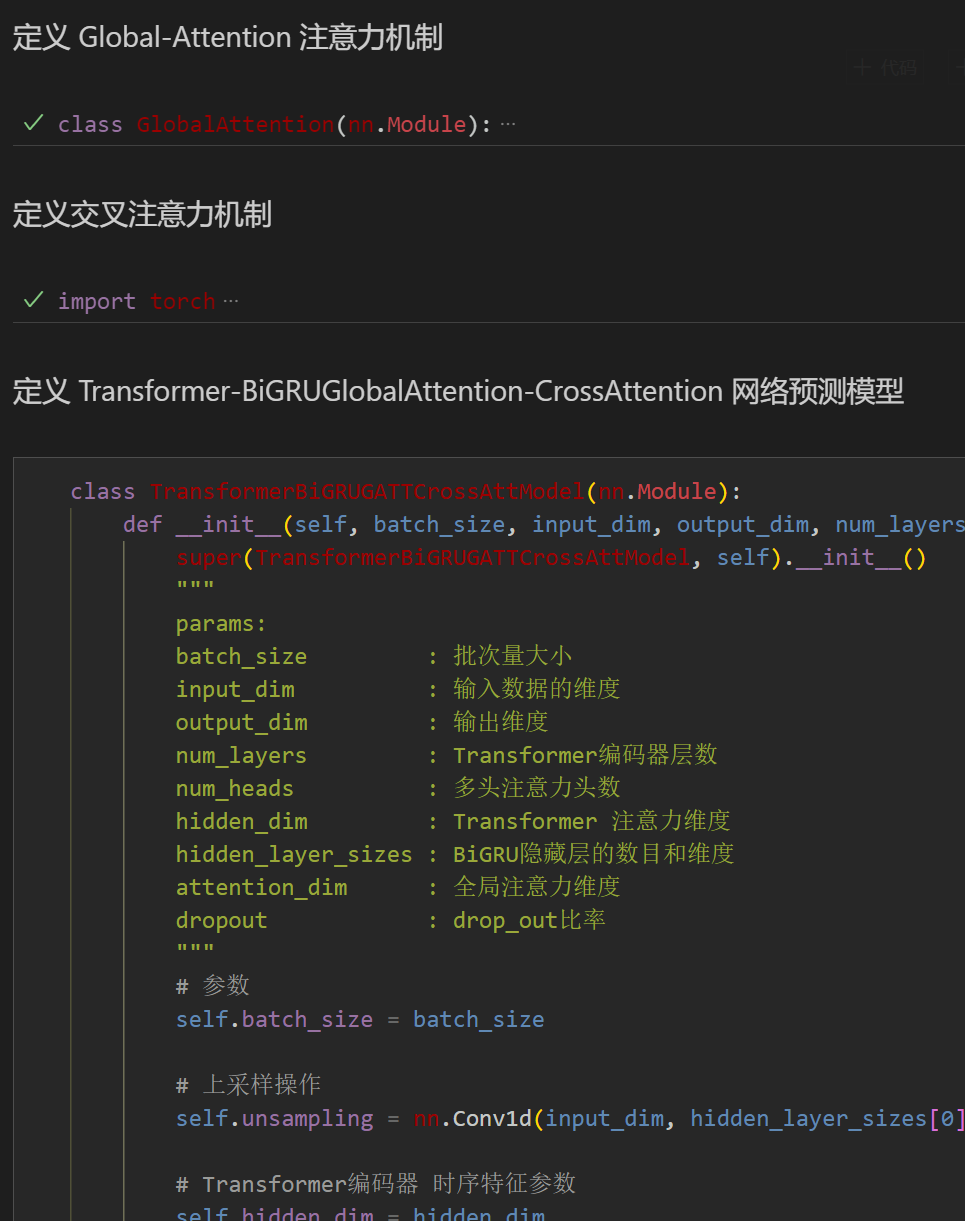
注意:输入数据形状为 [64, 7, 7], batch_size=64 ,7代表序列长度(滑动窗口取值), 维度7维代表7个变量的维度。
4.2 设置参数,训练模型
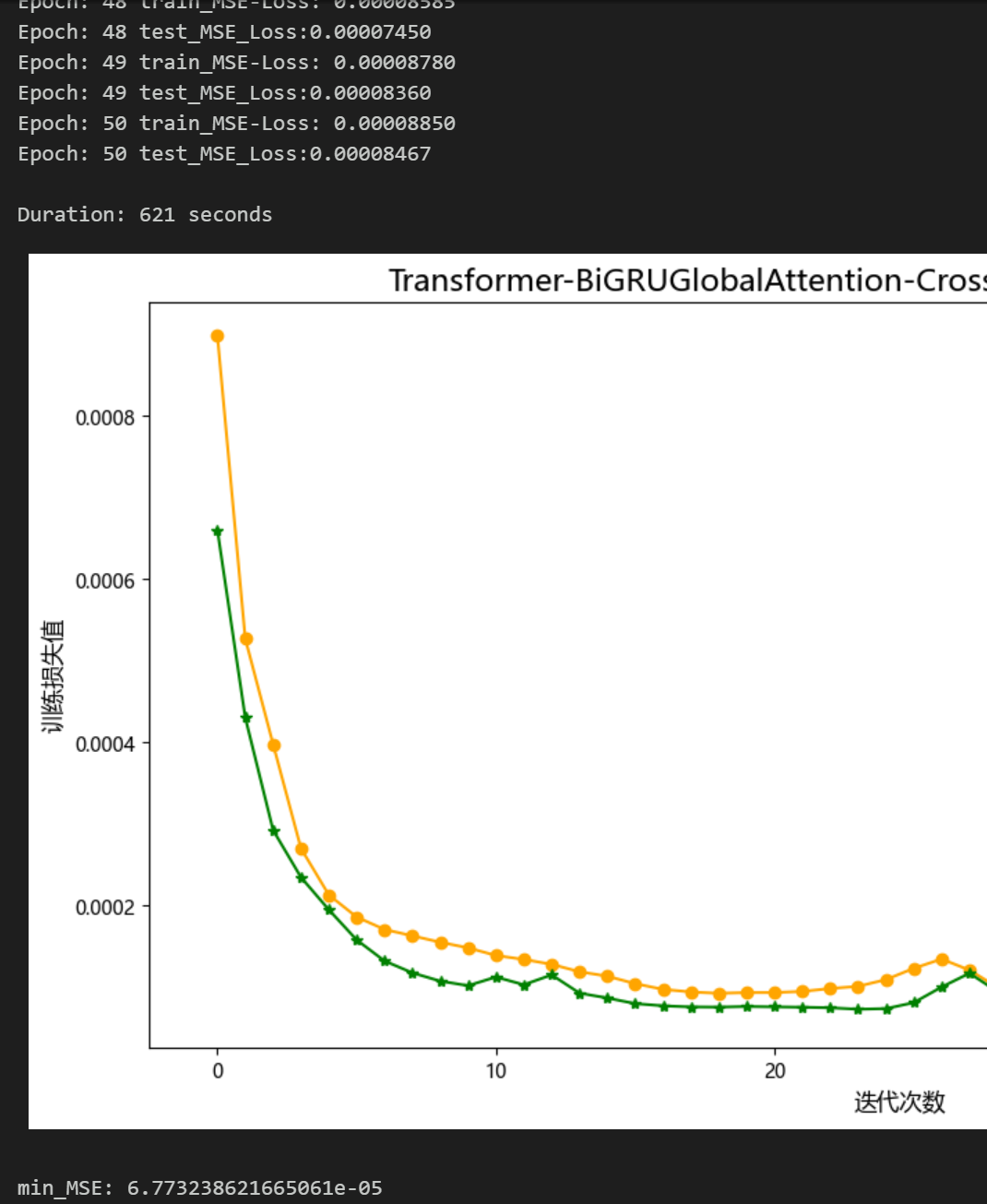
50个epoch, 训练误差极小 , 多变量特征序列Transformer-BiGRUGlobalAttention-CrossAttention并行融合网络模型 预测效果显著 ,模型能够充分提取时间序列的空间特征和时序特征,收敛速度快,性能优越,预测 精度高,能够从序列时空特征中提取出对模型预测重要的特征,效果明显!
注意调整参数:
- 可以适当增加Transformer编码器层数和隐藏层的维度、多头注意力头数,微调学习率;
- 调整BiGRU层数和每层神经元个数,增加更多的 epoch (注意防止过拟合)
- 可以改变滑动窗口长度(设置合适的窗口长度)
5 模型评估与可视化
5.1 结果可视化
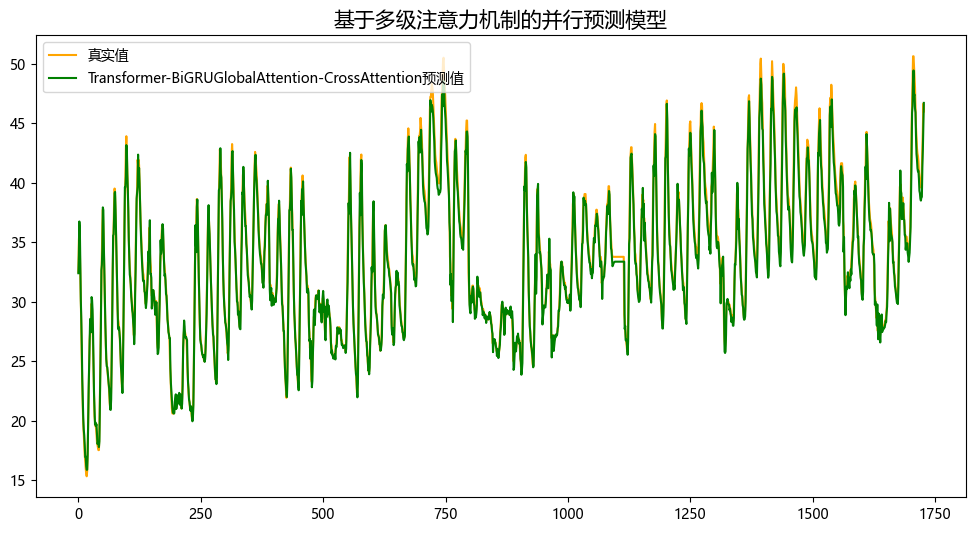
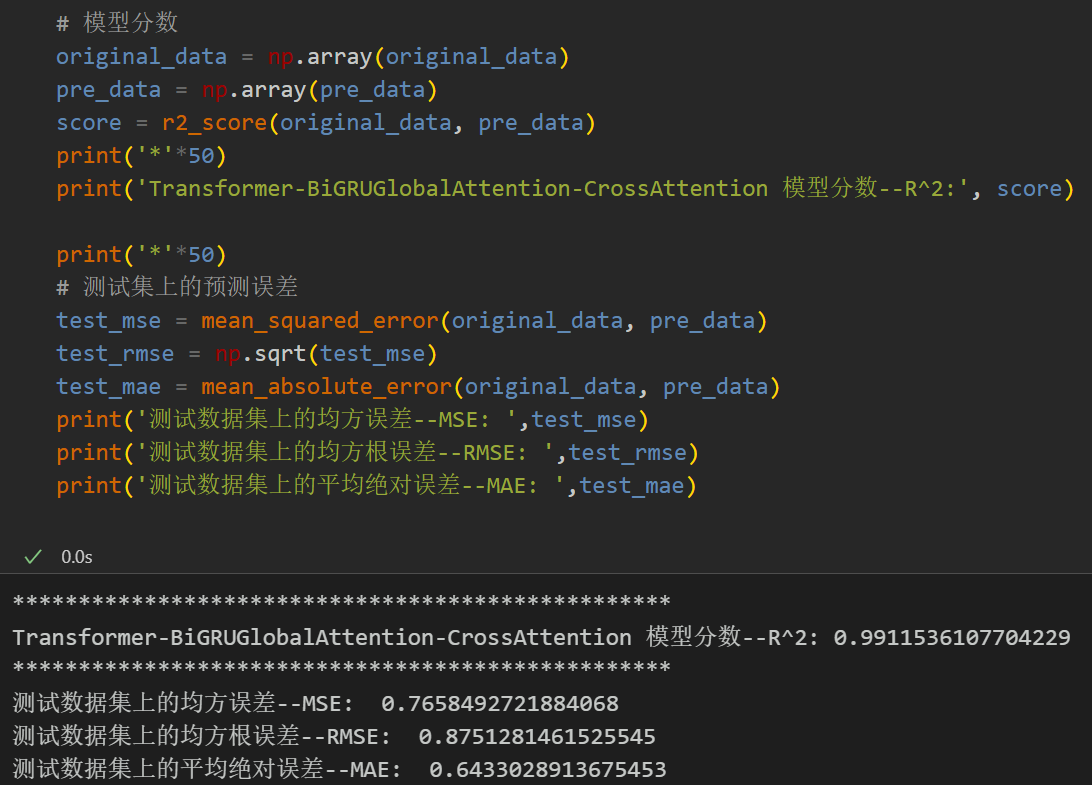
5.2 模型评估
5.3 特征可视化
有建模需求或论文指导的朋友请关注公众号,联系博主

往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较
风速预测(四)基于Pytorch的EMD-Transformer模型
风速预测(五)基于Pytorch的EMD-CNN-LSTM模型
风速预测(六)基于Pytorch的EMD-CNN-GRU并行模型
CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)
CEEMDAN +组合预测模型(CNN-LSTM + ARIMA)
CEEMDAN +组合预测模型(Transformer - BiLSTM + ARIMA)
CEEMDAN +组合预测模型(CNN-Transformer + ARIMA)
多特征变量序列预测(二)——CNN-LSTM-Attention风速预测模型
多特征变量序列预测(三)——CNN-Transformer风速预测模型
多特征变量序列预测(四) Transformer-BiLSTM风速预测模型
多特征变量序列预测(五) CEEMDAN+CNN-LSTM风速预测模型
多特征变量序列预测(六) CEEMDAN+CNN-Transformer风速预测模型
基于麻雀优化算法SSA的CEEMDAN-BiLSTM-Attention的预测模型
基于麻雀优化算法SSA的CEEMDAN-Transformer-BiGRU预测模型
多特征变量序列预测(七) CEEMDAN+Transformer-BiLSTM预测模型
多特征变量序列预测(八)基于麻雀优化算法的CEEMDAN-SSA-BiLSTM预测模型
多特征变量序列预测(11) 基于Pytorch的TCN-GRU预测模型
VMD + CEEMDAN 二次分解,CNN-LSTM预测模型
VMD + CEEMDAN 二次分解,CNN-Transformer预测模型
END
1. 版权声明:原创不易,转载请注明转自微信公众号[建模先锋]
2. 喜欢的朋友可以点个关注,给文章点个“在看”,分享朋友圈或讨论群
3. 关注微信公众[建模先锋], 回复”变压器“免费获取变压器数据集