
时序预测 | PyTorch基于改进Informer模型的时间序列预测,锂电池SOC估计
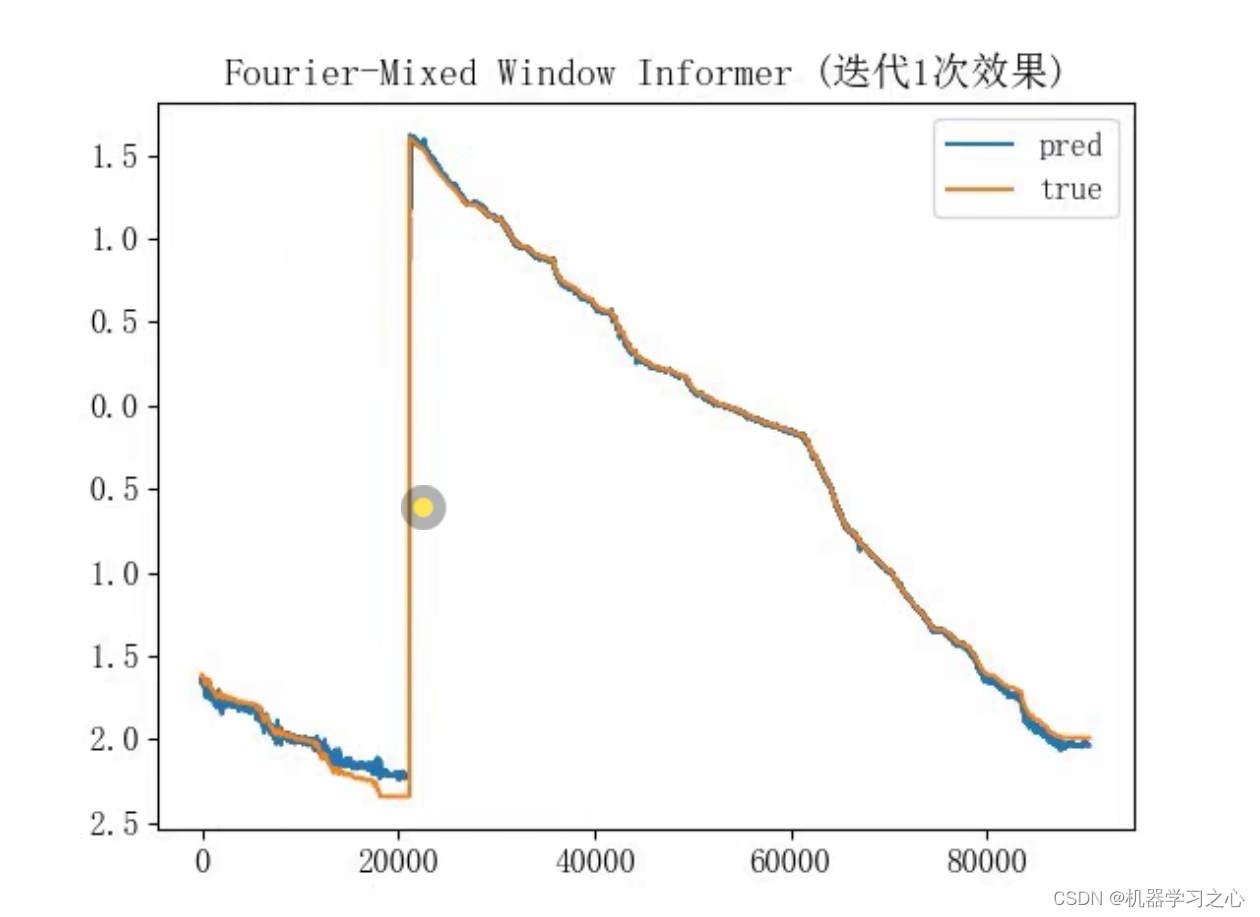
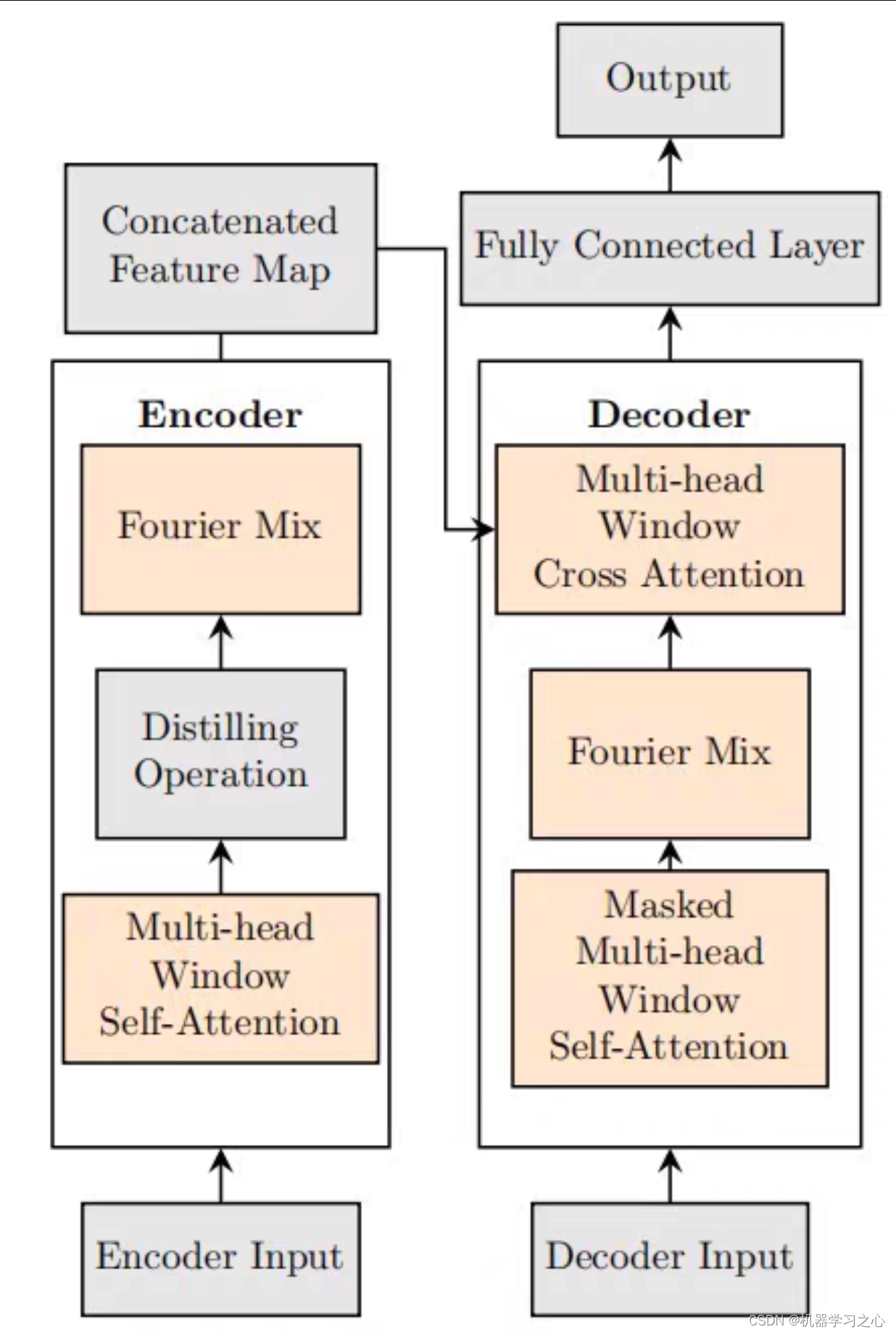
时间序列预测:informer改进模型(Fourier-Mixed Window Informer 采用傅里叶混合窗口注意力机制加速)实现高精度长期预测
PyTorch框架实现 多输出单输出 多输入多输出 单输入单输出。
import argparse
import os
import torch
import time
import numpy as np
# import os
# os.environ["KMP_DUPLICATE_LIB_OK"] = "True"
from exp.exp_model import Exp_Model
parser = argparse.ArgumentParser(description='[FWin] Long Sequences Forecasting')
parser.add_argument('--model', type=str, default='fwin',help='model of experiment, options: [informer, informerstack, informerlight(TBD)]')
parser.add_argument('--data', type=str, default='custom', help='data')
parser.add_argument('--root_path', type=str, default='./dataset/', help='root path of the data file') # csv文件路径
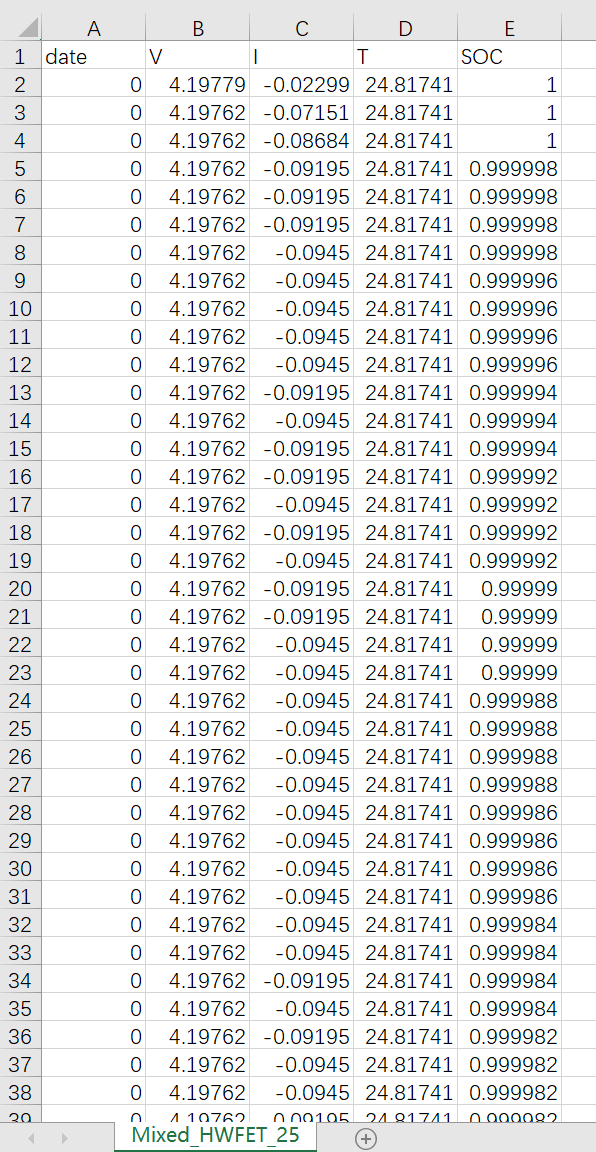
parser.add_argument('--data_path', type=str, default='Mixed_HWFET_25.csv', help='data file') # csv文件 第一列必须为date
parser.add_argument('--features', type=str, default='MS', help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
parser.add_argument('--target', type=str, default='SOC', help='target feature in S or MS task') # 需要预测的特征
parser.add_argument('--freq', type=str, default='h', help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='location of model checkpoints')
parser.add_argument('--seq_len', type=int, default=96, help='input sequence length of Informer encoder')
parser.add_argument('--label_len', type=int, default=48, help='start token length of Informer decoder')
parser.add_argument('--pred_len', type=int, default=12, help='prediction sequence length')
# Informer decoder input: concat[start token series(label_len), zero padding series(pred_len)]
#FWin hyperparameter
parser.add_argument('--window_size', type=int, default=24, help='window size for winformer')
parser.add_argument('--dwindow_size', type=int, default=0, help='decoder window size for winformer, if 0 then use window_size')
parser.add_argument('--num_windows', type=int, default=4, help='number of window for swinformer')
parser.add_argument('--enc_in', type=int, default=4, help='encoder input size') # csv文件中的特征数 (除date列之外的列数)
parser.add_argument('--dec_in', type=int, default=4, help='decoder input size') # csv文件中的特征数 (除date列之外的列数)
parser.add_argument('--c_out', type=int, default=1, help='output size') # 若前边的--features为 MS或S 则为1 否则为csv文件中的特征数
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
parser.add_argument('--n_heads', type=int, default=8, help='num of heads')
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
parser.add_argument('--s_layers', type=str, default='3,2,1', help='num of stack encoder layers')
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
parser.add_argument('--factor', type=int, default=5, help='probsparse attn factor')
parser.add_argument('--padding', type=int, default=0, help='padding type')
parser.add_argument('--distil', action='store_false', help='whether to use distilling in encoder, using this argument means not using distilling', default=True)
parser.add_argument('--dropout', type=float, default=0.05, help='dropout')
parser.add_argument('--attn', type=str, default='prob', help='attention used in encoder, options:[prob, full]')
parser.add_argument('--embed', type=str, default='timeF', help='time features encoding, options:[timeF, fixed, learned]')
parser.add_argument('--activation', type=str, default='gelu',help='activation')
parser.add_argument('--output_attention', action='store_true', help='whether to output attention in ecoder')
parser.add_argument('--do_predict', action='store_true', help='whether to predict unseen future data')
parser.add_argument('--mix', action='store_false', help='use mix attention in generative decoder', default=True)
parser.add_argument('--cols', type=str, nargs='+', help='certain cols from the data files as the input features')
parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')
parser.add_argument('--itr', type=int, default=1, help='experiments times')
parser.add_argument('--train_epochs', type=int, default=1, help='train epochs') #迭代次数 一般3-10次
parser.add_argument('--batch_size', type=int, default=256, help='batch size of train input data') # batch_size
parser.add_argument('--patience', type=int, default=3, help='early stopping patience') # 早停
parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate')
parser.add_argument('--des', type=str, default='test',help='exp description')
parser.add_argument('--loss', type=str, default='mse',help='loss function')
parser.add_argument('--lradj', type=str, default='type1',help='adjust learning rate')
parser.add_argument('--use_amp', action='store_true', help='use automatic mixed precision training', default=False)
parser.add_argument('--inverse', action='store_true', help='inverse output data', default=True) # 输出结果反归一化
parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')
parser.add_argument('--gpu', type=int, default=0, help='gpu')
parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)
parser.add_argument('--devices', type=str, default='0,1,2,3',help='device ids of multile gpus')
parser.add_argument('--save_prediction', action='store_true', default=True, help='whether to save prediction output') # 保存测试结果
args = parser.parse_args()
args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else False
if args.use_gpu and args.use_multi_gpu:
args.devices = args.devices.replace(' ','')
device_ids = args.devices.split(',')
args.device_ids = [int(id_) for id_ in device_ids]
args.gpu = args.device_ids[0]
data_parser = {
'ETTh1':{'data':'ETTm1.csv','T':'OT','M':[4,4,4],'S':[1,1,1],'MS':[4,4,1]},
'ETTh2':{'data':'ETTh2.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},
'ETTm1':{'data':'ETTm1.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},
'ETTm2':{'data':'ETTm2.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},
'WTH':{'data':'WTH.csv','T':'WetBulbCelsius','M':[12,12,12],'S':[1,1,1],'MS':[12,12,1]},
'ECL':{'data':'ECL.csv','T':'MT_320','M':[321,321,321],'S':[1,1,1],'MS':[321,321,1]},
'Solar':{'data':'solar_AL.csv','T':'POWER_136','M':[137,137,137],'S':[1,1,1],'MS':[137,137,1]},
}
if args.data in data_parser.keys():
data_info = data_parser[args.data]
args.data_path = data_info['data']
args.target = data_info['T']
args.enc_in, args.dec_in, args.c_out = data_info[args.features]
args.s_layers = [int(s_l) for s_l in args.s_layers.replace(' ','').split(',')]
args.detail_freq = args.freq
args.freq = args.freq[-1:]
print('Args in experiment:')
print(args)