为防止倒卖!本全家桶停止更新!
关于此全家桶的介绍,
大家可以看看以下的文章链接,直接跳转,对python预测全家桶进行了解。
参考往期文章如下:
2.机器学习预测全家桶-Python,一次性搞定多/单特征输入,多/单步预测!最强模板!
3.机器学习预测全家桶-Python,新增CEEMDAN结合代码,大大提升预测精度!
4.机器学习预测全家桶-Python,新增VMD结合代码,大大提升预测精度!
5.Python机器学习预测+回归全家桶,再添数十种回归模型!这次千万别再错过了!
6.Python机器学习预测+回归全家桶,新增TCN,BiTCN,TCN-GRU,BiTCN-BiGRU等组合模型预测
7.调用最新mealpy库,实现215个优化算法优化CNN-BiLSTM-Attention,电力负荷预测
8.Transformer实现风电功率预测,python预测全家桶
9.几个小创新模型,KAN组合网络(LSTM、GRU、Transformer)时间序列预测
10.几个小创新模型,KAN组合网络(LSTM、GRU、Transformer)回归预测
11.接着更!seq2seq、wavenet、bert、informer、RNN时间预测模型
12.重大更新!建议所有人都下载!Python预测全家桶小白版
第一级文件夹:

第二级文件夹:
包含的数量之多,直呼过瘾!
本期新增模型:
采用最新的mealpy库实现对CNN-BiLSTM-Attention的优化。
本期新增模型功能简介:
- 本期所用的mealpy库是3.0.0版本的,包含215智能优化算法(190个官方(原始、混合、变体),25个已开发),方便修改多种智能优化算法,一键替换,简单易改!具体可参考官方链接:https://pypi.org/project/mealpy/3.0.0/
- 优化前后预测对比图自动保存
- 自动打印优化前后指标
- 采用了作者自行编写函数代码,可以一键更改单/多特征输入,单/多步预测。
结果展示:
①多变量输入单步预测结果:
选择前5天多个特征的数据作为输入,预测未来一天的负荷值。
优化前网络模型预测结果:

优化后网络模型预测结果对比图:

优化前后指标打印结果:


②多变量输入多步预测结果:
选择前5天多个特征的数据作为输入,预测未来2天的负荷值。
优化前网络模型预测结果,因为是预测未来两天,一次有两步预测结果。
第一步优化前预测结果:

第二步优化前预测结果:

优化后网络模型预测结果对比图,同样有两步:
第一步优化前后预测结果对比:

第二步优化前后预测结果对比:

优化前后指标打印结果:



本期推出的python机器学习预测全家桶一共包含了26种模型。包括如下:
单模型预测
Bagging、BiGRU、BiLSTM、BP、CART、ELM、Gradient-boosting、GRU、LSTM、Random-Forest、RBF、SVR、xgboost
组合模型预测
BiGRU-Attention、BiLSTM-Attention、CNN-BiGRU、CNN-BiGRU-Attention、CNN-BiLSTM、CNN-BiLSTM-Attention、CNN-GRU、CNN-GRU-Attention、CNN-LSTM、CNN-LSTM-Attention、GRU-Attention、LSTM-Attention
智能算法优化案例模型预测
DBO-LSTM-Attention
预计后续会继续推出:
1:各种基础、混合的可用于机器预测的新方法,并且与各种BiLSTM、Attention、GRU等的混合使用
2:各种新型的智能优化算法优化机器学习预测模型
3:将改进的智能算法用于机器学习模型的预测
4:添加其他类型的数据集用于预测
5:添加混合VMD/CEEMDAN/ICEEMDAN等的数据处理方法
承诺该全家桶永久更新!
本次代码亮点:
①一键切换多/单特征输入,多/单步预测
小淘自己编写了一个可以一键实现:多/单特征输入,多/单步预测的数据处理代码。让小白也可以轻松更改自己数据的各种输入格式。关于多/单特征输入,多/单步预测,到底是什么意思?一文讲明白!
代码定义如下:
def data_collation(data, n_in, n_out, or_dim, scroll_window, num_samples)
# 关于此函数怎么用,下面详细举例介绍:
# 构造数据,这个函数可以实现单输入单输出,单输入多输出,多输入单输出,和多输入多输出。
# 举个例子:
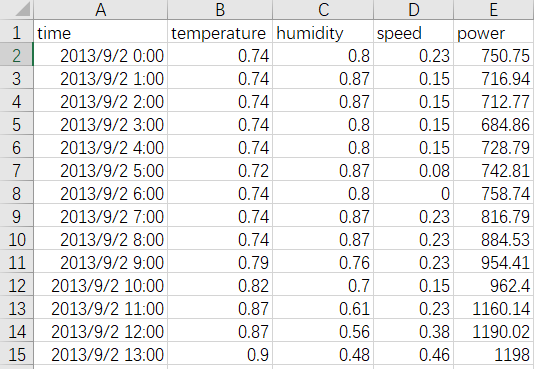
# 假如原始数据为,其中务必使得数据前n-1列都为特征,最后一列为输出
# [0.74 0.8 0.23 750.75
# 0.74 0.87 0.15 716.94
# 0.74 0.87 0.15 712.77
# 0.74 0.8 0.15 684.86
# 0.74 0.8 0.15 728.79
# 0.72 0.87 0.08 742.81
# 0.71 0.99 0.16 751.3]
#(多输入多输出为例),假如n_in = 2,n_out=2,scroll_window=1
# 输入前2行数据的特征,预测未来2个时刻的数据,滑动步长为1。
# 使用此函数后,数据会变成:
# 【0.74 0.8 0.23 750.75 0.74 0.87 0.15 716.94 712.77 684.86
# 0.74 0.87 0.15 716.94 0.74 0.87 0.15 712.77 684.86 728.79
# 0.74 0.87 0.15 712.77 0.74 0.8 0.15 684.86 728.79 742.81】
# 假如n_in = 2,n_out=1,scroll_window=2
# 输入前2行数据的特征,预测未来1个时刻的数据,滑动步长为2。
# 使用此函数后,数据会变成:
# 【0.74 0.8 0.23 750.75 0.74 0.87 0.15 716.94 712.77
# 0.74 0.87 0.15 712.77 0.74 0.8 0.15 684.86 728.79
# 0.74 0.8 0.15 728.79 0.72 0.87 0.08 742.81 751.3】
#写到这里相比大家已经完全明白次函数的用法啦!欢迎关注《淘个代码》公众号!获取更多代码!
#单输入单输出,和单输入多输出也是这么个用法!单输入无非就是数据维度变低了而已。欢迎关注《淘个代码》公众号!获取更多代码
②四种数据集,预测效果都不错,证明数据替换简单!
很多小伙伴会问到,替换数据复不复杂。本期全家桶为了实现代码对不同数据的兼容性,小淘分别对这四种不同的数据集进行了测试,效果都是不错的!放心大胆使用!四种数据分别如下:
《电力负荷预测数据1.xlsx》
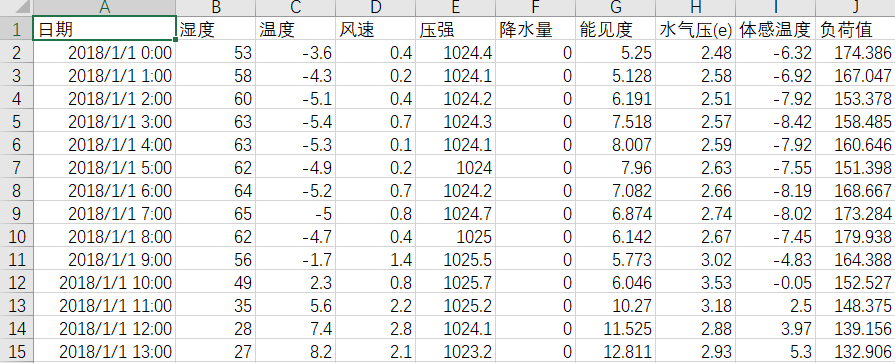
以BiGRU为例,前三行数据作为输入,预测第四个数据。滚动步长为1,展示预测效果:
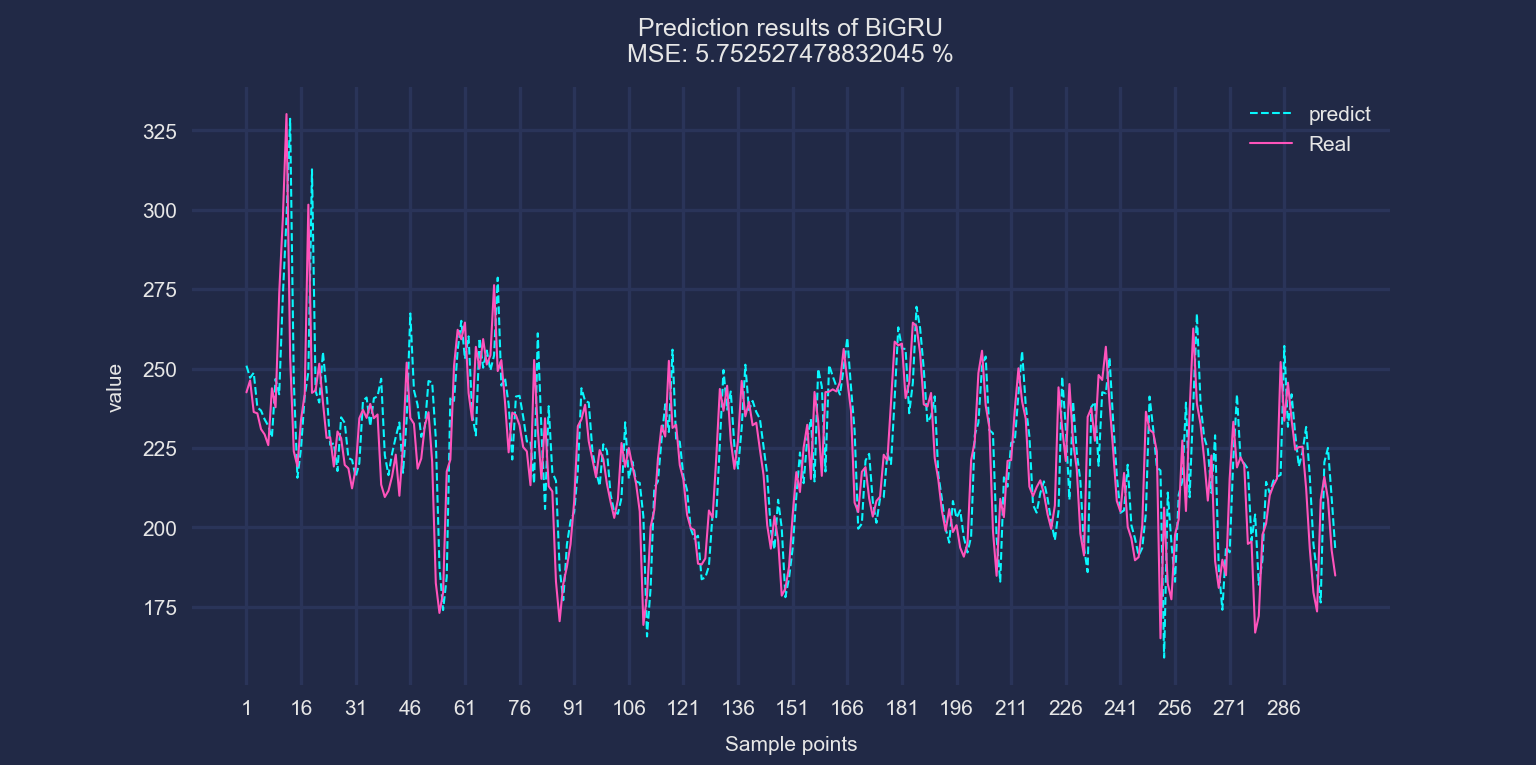
《电力负荷预测数据2.xlsx》
以BiGRU为例,前三行数据作为输入,预测第四个数据。滚动步长为1,展示预测效果:
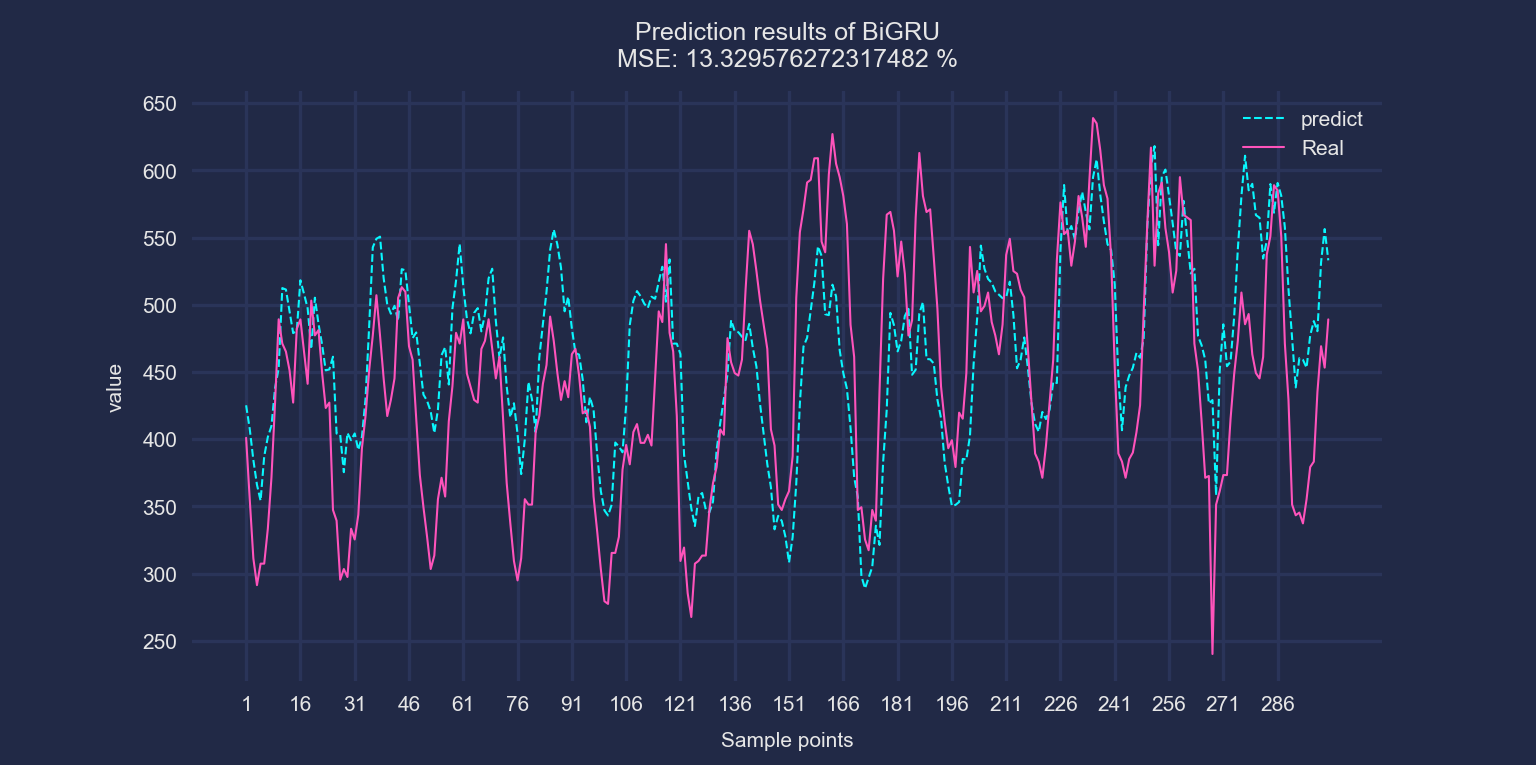
《风电场功率预测.xlsx》
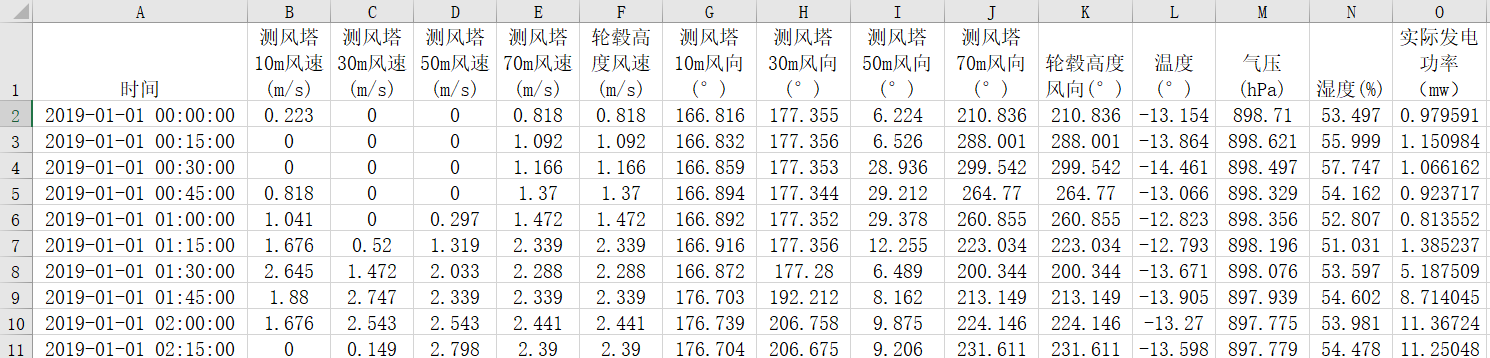
以BiGRU为例,前三行数据作为输入,预测第四个数据。滚动步长为1,展示预测效果:
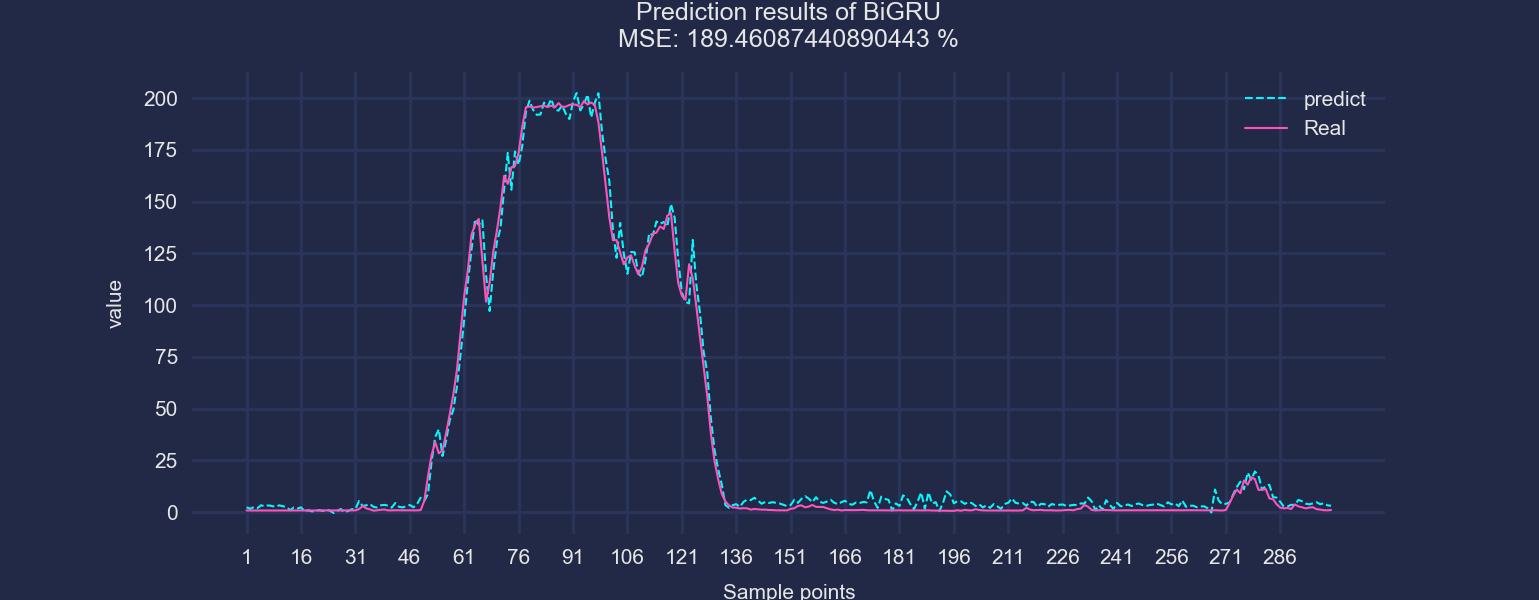
《股票预测.csv》
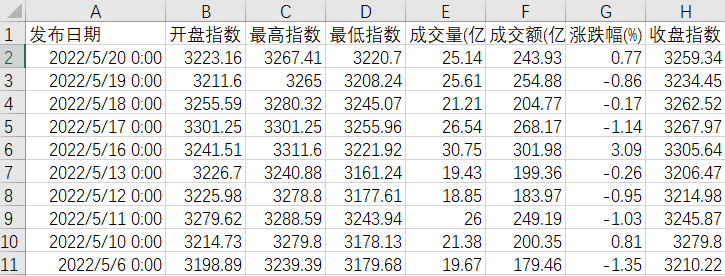
以BiGRU为例,前三行数据作为输入,预测第四个数据。滚动步长为1,展示预测效果:
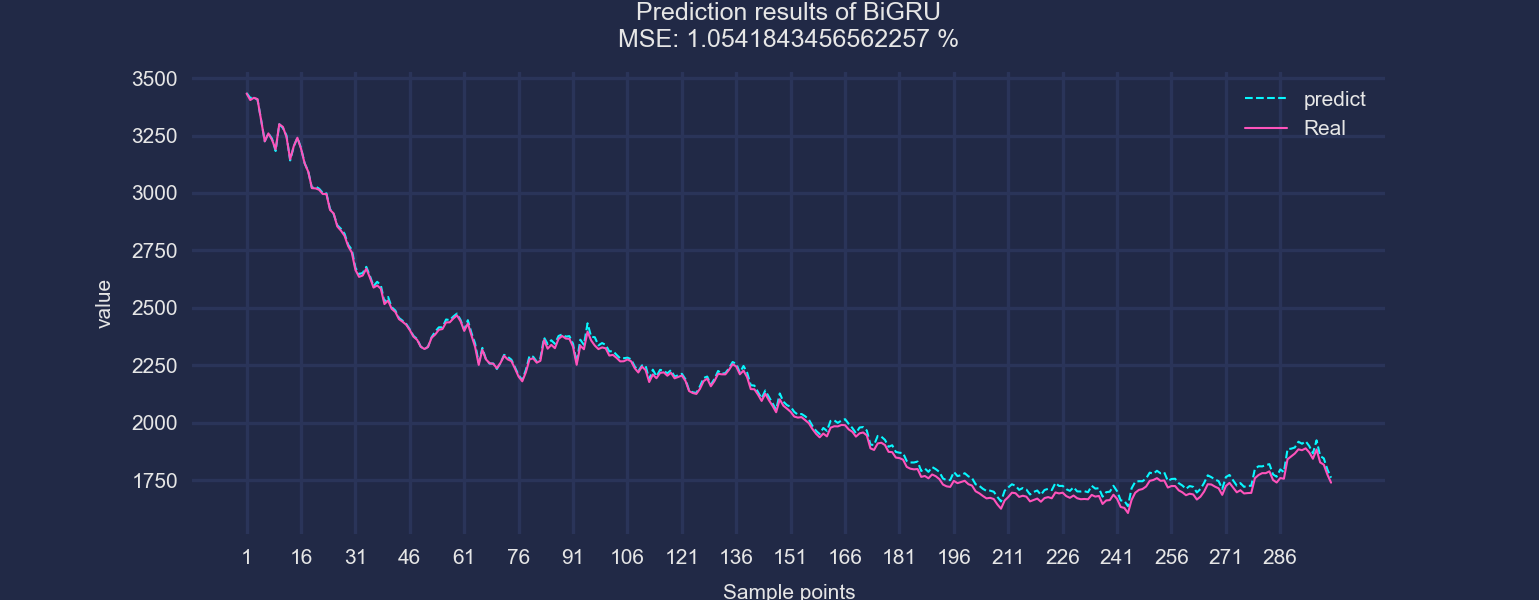
四种数据全是真实的数据!
只要你的数据格式也是这样,前几列是特征,最后一列是输出值。此代码就完全适用!
③代码注释逐行详细,适合新手小白!
# 这里来个多特征输入,单步预测的案例
n_in = 3 # 输入前3行的数据
n_out = 1 # 预测未来1个时刻的数据
or_dim = values.shape[1] # 记录特征数据维度
num_samples = 2000 # 可以设定从数据中取出多少个点用于本次网络的训练与测试。
scroll_window = 1 #如果等于1,下一个数据从第二行开始取。如果等于2,下一个数据从第三行开始取
res = data_collation(values, n_in, n_out, or_dim, scroll_window, num_samples)
# 把数据集分为训练集和测试集
values = np.array(res)
# 将前面处理好的DataFrame(data)转换成numpy数组,方便后续的数据操作。
n_train_number = int(num_samples * 0.85)
# 计算训练集的大小。
# 设置85%作为训练集
# int(...) 确保得到的训练集大小是一个整数。
model = BaggingRegressor(n_estimators=60)
# 创建Bagging模型
model.fit(vp_train, vt_train)
# 使用训练数据(vp_train和vt_train)来训练模型。
# vp_train是输入特征,vt_train是目标变量。
# fit方法将会应用前面定义的网络结构和训练参数来训练模型。
# 作出预测
yhat = model.predict(vp_test)
# 使用模型对测试集的输入特征(vp_test)进行预测。
# yhat是模型预测的输出值。
yhat = yhat.reshape(-1, 1)
# 将预测值yhat重塑为二维数组,以便进行后续操作。
模型结果展示
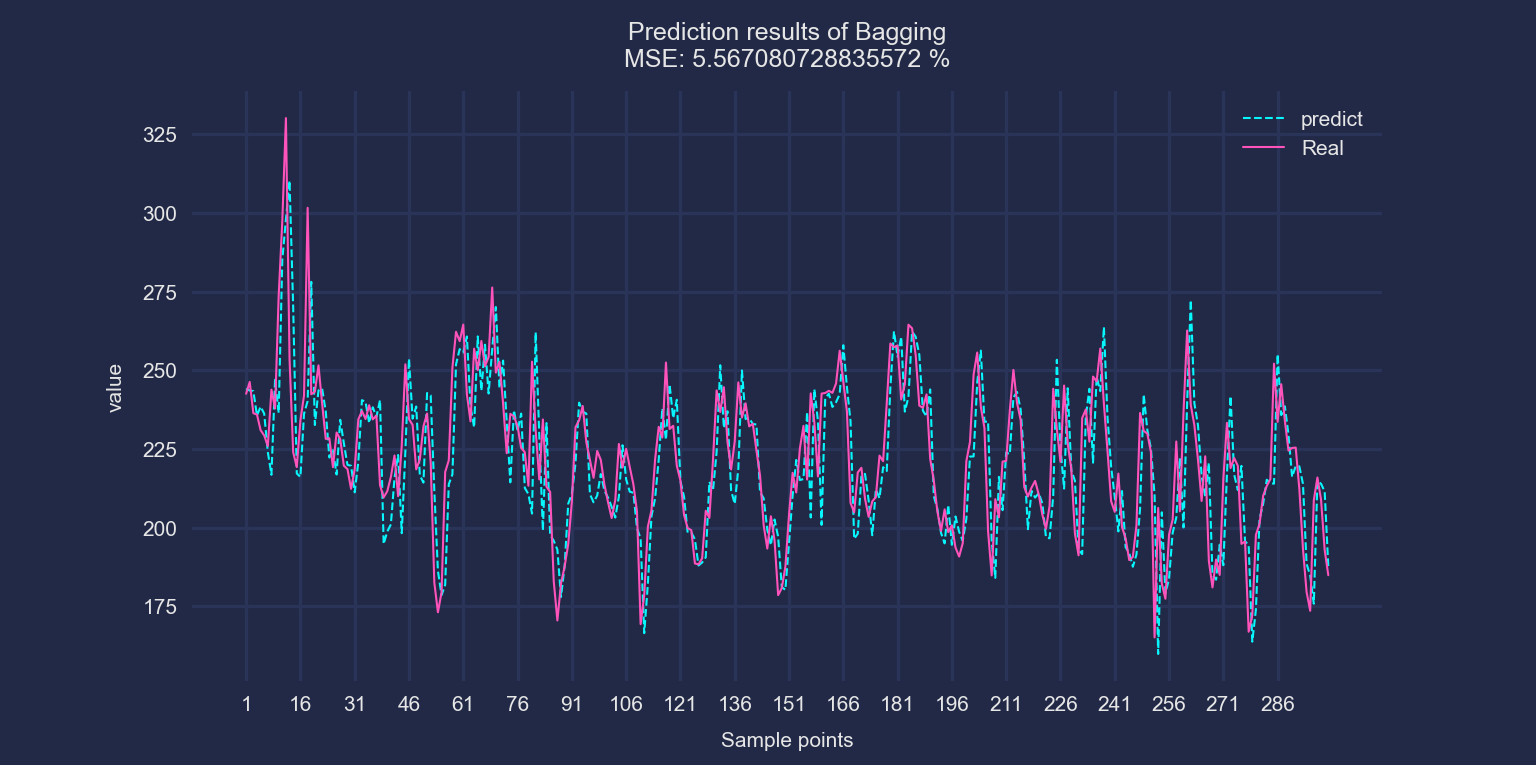
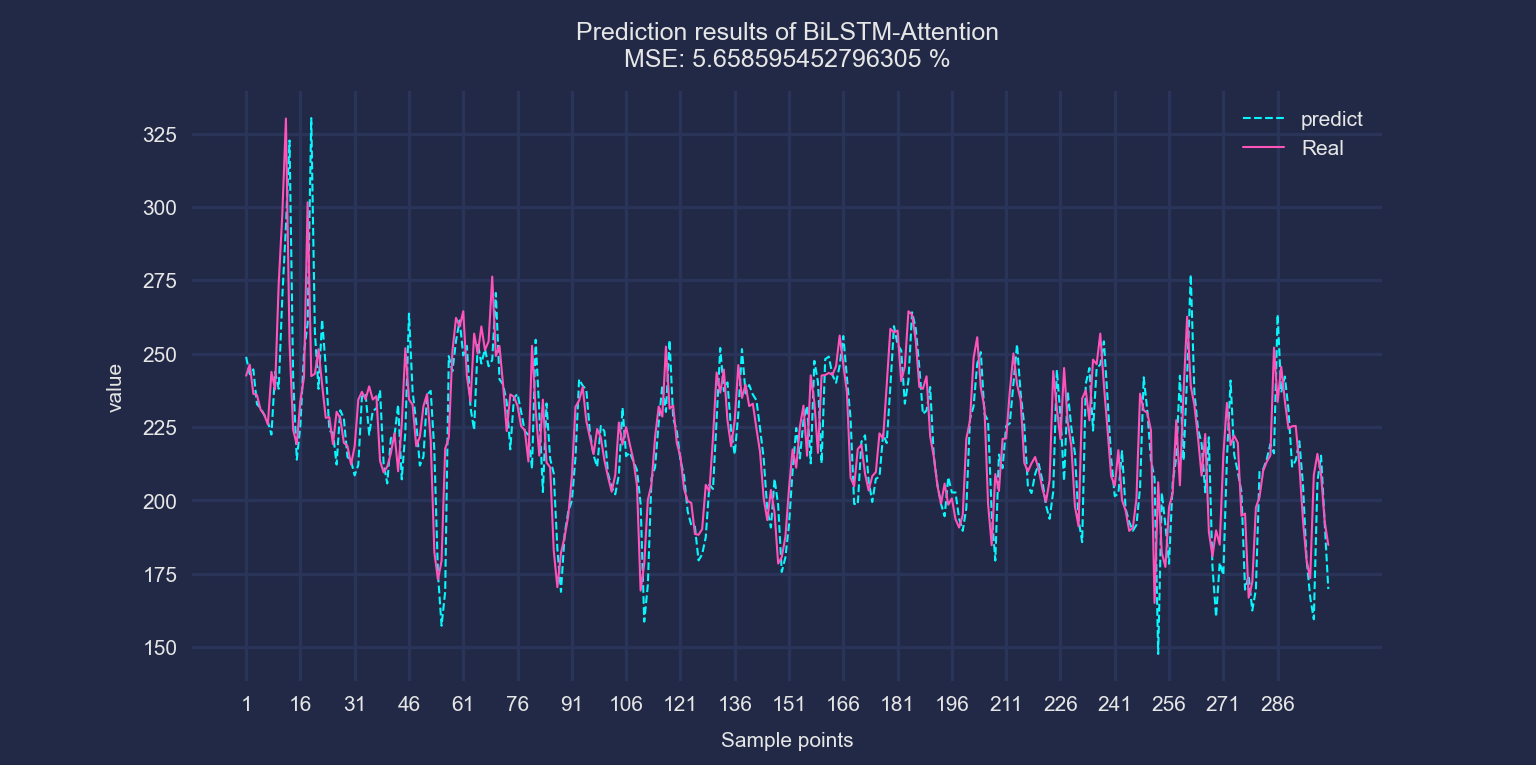
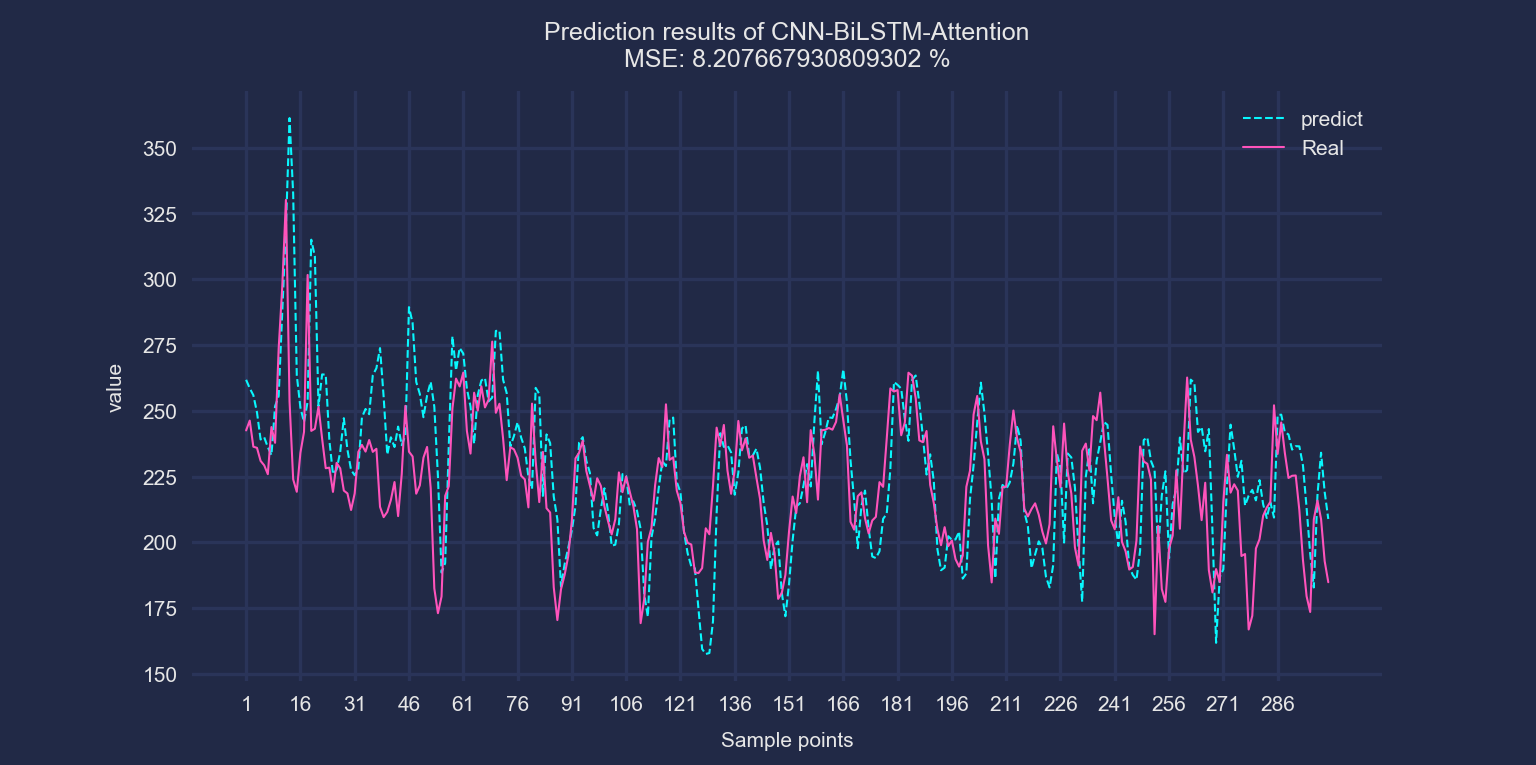
以电力负荷预测数据1为例进行展示。模型输入为前三行的湿度、温度、风速、压强、降水量、能见度、水气压(e)、体感温度(AT)和负荷值数据。预测下一个时刻的负荷值。滚动步长为1。
Bagging模型:

BiLSTM-Attention模型:

CNN-BiLSTM-Attention模型:

DBO-LSTM-Attention对比模型
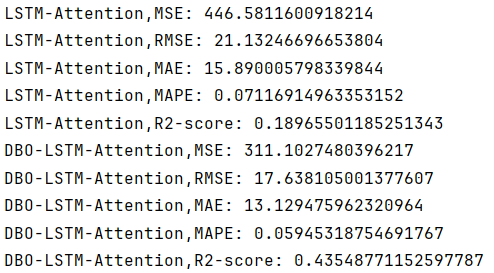
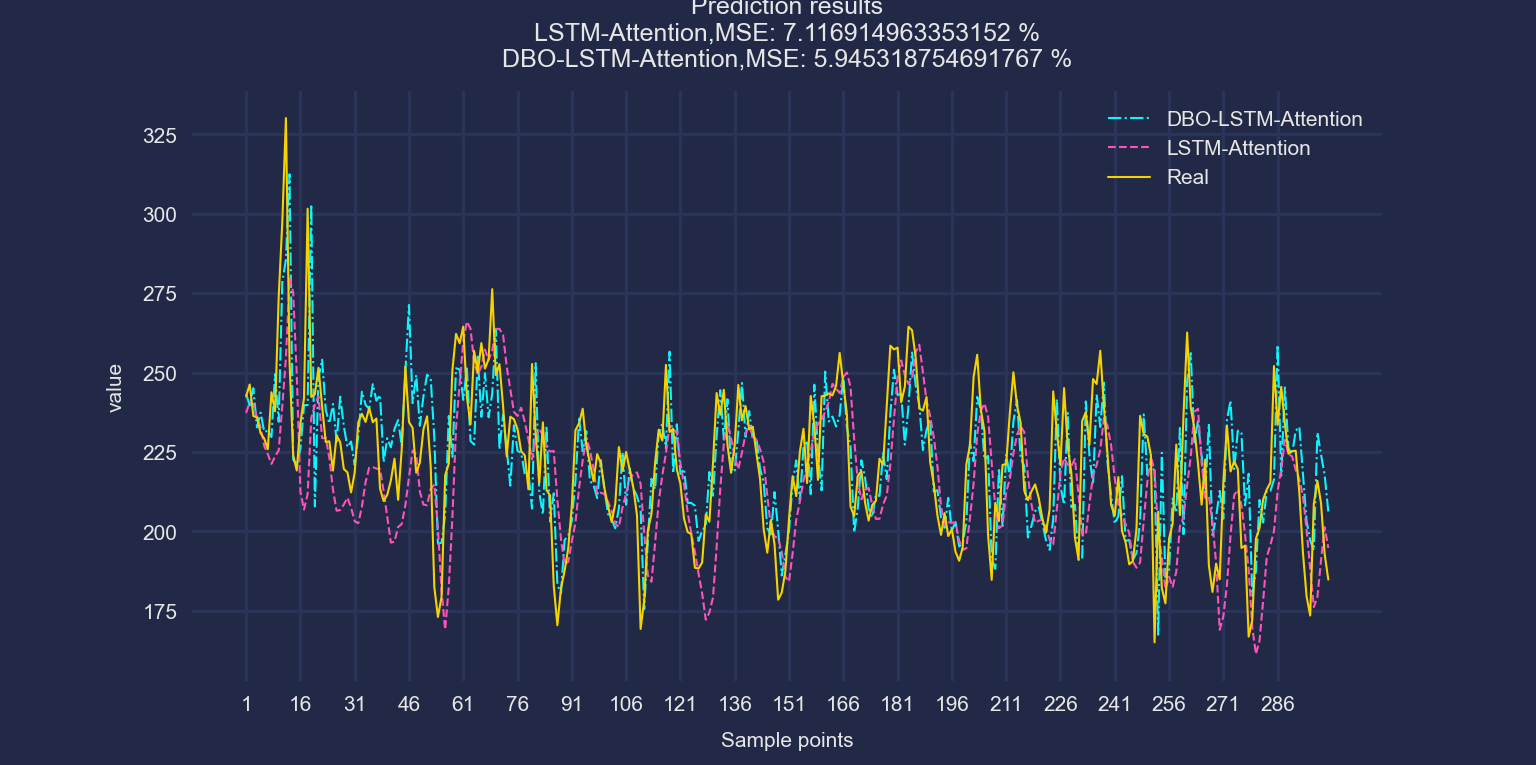
剩下的模型就不再一一展示了。模型均可一键出结果。替换数据也是极其方便!
模型调用的包大致如下,不用GPU也可以运行。作者使用的是python3.9版本。目前亲测3.12是不能用的哈。
# 调用相关库
import os # 导入os模块,用于操作系统功能,比如环境变量
import math # 导入math模块,提供基本的数学功能
import pandas as pd # 导入pandas模块,用于数据处理和分析
import openpyxl
from math import sqrt # 从math模块导入sqrt函数,用于计算平方根
from numpy import concatenate # 从numpy模块导入concatenate函数,用于数组拼接
import matplotlib.pyplot as plt # 导入matplotlib.pyplot模块,用于绘图
import numpy as np # 导入numpy模块,用于数值计算
import tensorflow as tf # 导入tensorflow模块,用于深度学习
from sklearn.preprocessing import MinMaxScaler # 导入sklearn中的MinMaxScaler,用于特征缩放
from sklearn.preprocessing import StandardScaler # 导入sklearn中的StandardScaler,用于特征标准化
from sklearn.preprocessing import LabelEncoder # 导入sklearn中的LabelEncoder,用于标签编码
from sklearn.metrics import mean_squared_error # 导入sklearn中的mean_squared_error,用于计算均方误差
from tensorflow.keras.layers import * # 从tensorflow.keras.layers导入所有层,用于构建神经网络
from tensorflow.keras.models import * # 从tensorflow.keras.models导入所有模型,用于构建和管理模型
from sklearn.metrics import mean_squared_error, mean_absolute_error,r2_score # 导入额外的评估指标
from pandas import DataFrame # 从pandas导入DataFrame,用于创建和操作数据表
from pandas import concat # 从pandas导入concat函数,用于DataFrame的拼接
import keras.backend as K # 导入keras的后端接口
from scipy.io import savemat, loadmat # 从scipy.io导入savemat和loadmat,用于MATLAB文件的读写
from sklearn.neural_network import MLPRegressor # 从sklearn.neural_network导入MLPRegressor,用于创建多层感知器回归模型
from keras.callbacks import LearningRateScheduler # 从keras.callbacks导入LearningRateScheduler,用于调整学习率
from tensorflow.keras import Input, Model, Sequential # 从tensorflow.keras导入Input, Model和Sequential,用于模型构建
import mplcyberpunk
from qbstyles import mpl_style
import copy
# 导入copy模块,用于对象的复制。
import random
# 导入random模块,用于生成随机数。
from scipy.io import savemat, loadmat
# 从scipy.io模块导入savemat和loadmat函数,用于读写MATLAB格式的文件。
from numpy import concatenate
# 从numpy模块导入concatenate函数,用于数组的连接。
from matplotlib.pylab import mpl
# 从matplotlib.pylab模块导入mpl,用于配置matplotlib的一些参数。