本期文章采用小龙虾优化算法(Crayfish optimization algorithm,COA)优化极限学习机(ELM),实现数据分类。该方法也可以用于其他故障分类。
代码目录
小龙虾优化算法是于2023年9月最新发表在Artifcial Intelligence Review的一个算法,该算法的收敛能力还是很不错的。
此次的分类案例中,选用的是公用的UCI数据集。
ELM极限学习机初始的权值阈值都是随机生成的,因此不一定是最佳的。采用智能算法优化ELM的权值阈值,使得输入与输出有更加完美的映射关系,以此来提高ELM数据分类模型的精度。
分类案例
COA-ELM的分类案例,采用的数据是UCI数据集中的乳腺癌分类数据集(Wisconsin Diagnostic Breast Cancer Data — wdbc),该数据一共分为两类。接下来看分类效果。
标准ELM模型分类结果:
混淆矩阵结果图:
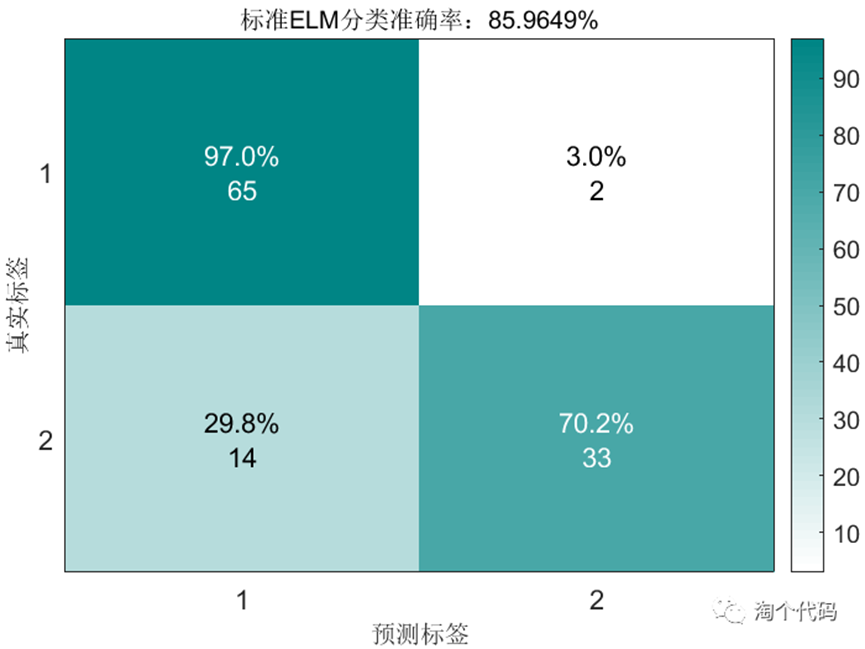
简单说一下这个图该怎么理解。请大家横着看,每行的数据加起来是100%,每行的数据个数加起来就是测试集中第一类数据的真实个数。以第一行为例,测试集中一共有67个数据是属于第一类的,而在67个数据中,有65个预测正确,有2个预测成了第2类。其他行均这样理解。
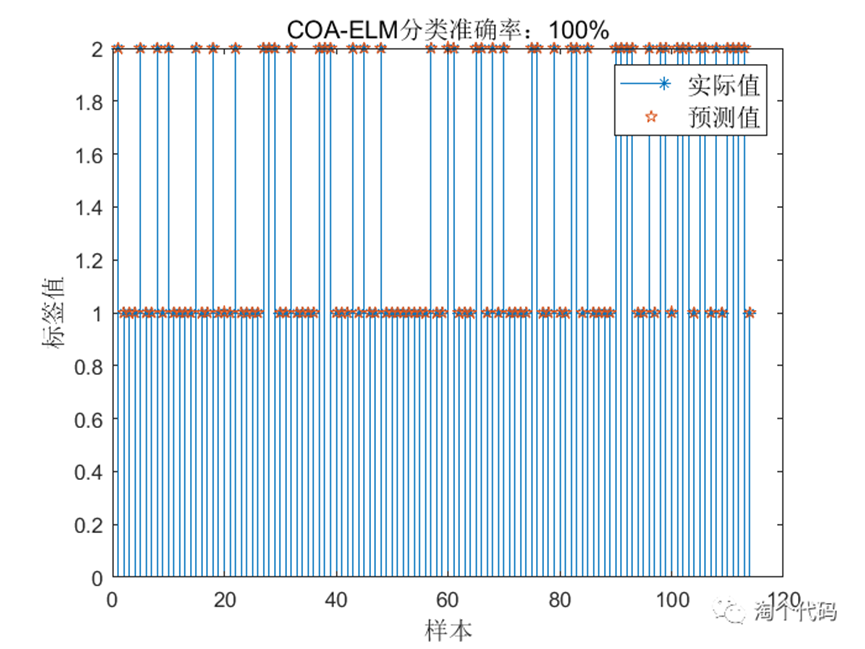
下面这个图是另一种结果展现方式,在一些论文中会用这种方式展示结果。

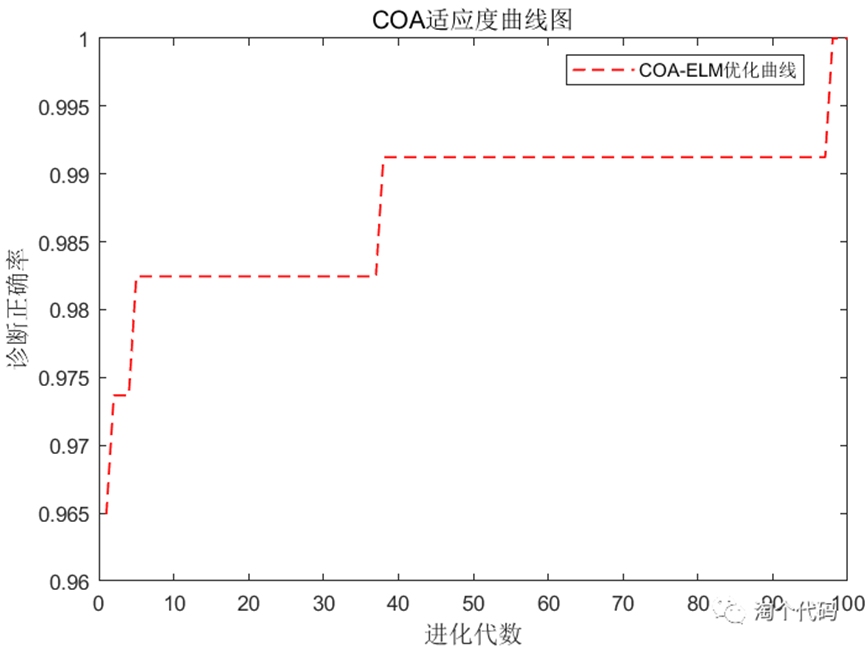
COA-ELM分类结果:

03 代码展示
%% 初始化clearclose allclcwarning offaddpath(genpath(pwd));load wdbc.mat data = WDBC;data=data(randperm(size(data,1)),:); %此行代码用于打乱原始样本,使训练集测试集随机被抽取,有助于更新预测结果。input=data(:,2:end);output =data(:,1);%% 划分训练集和测试集m=fix(size(data,1)*0.8); %训练的样本数目%训练集input_train=input(1:m,:)';output_train=output(1:m,:)';% 测试集input_test=input(m+1:end,:)';output_test=output(m+1:end,:)';%% 数据归一化[inputn,inputps]=mapminmax(input_train,0,1);inputn_test=mapminmax('apply',input_test,inputps); %测试集%% 获取输入层节点、输出层节点个数inputnum=size(input_train,1);outputnum=size(output_train,1);disp('/////////////////////////////////')disp('ELM网络结构...')disp(['输入层的节点数为:',num2str(inputnum)])disp(['输出层的节点数为:',num2str(outputnum)])hiddennum = 8; %隐含层节点 %% 没有优化前的ELM网络,构建ELM分类器并预测disp(' ')disp('标准的ELM网络:')activation='sin';[IW,B,LW,TF,TYPE] = elmtrain(inputn,output_train,hiddennum,activation,1);Tn_sim = elmpredict(inputn_test,IW,B,LW,TF,TYPE);test_accuracy=(sum(output_test==Tn_sim))/length(output_test);% 画图figureset(gca,'looseInset',[0 0 0 0])stem(output_test,'*')hold onplot(Tn_sim','p')xlabel('样本','fontsize',12,'fontname','TimesNewRoman');ylabel('标签值','fontsize',12,'fontname','TimesNewRoman');title(['标准ELM分类准确率:',num2str(test_accuracy*100),'%'],'fontsize',12,'fontname','TimesNewRoman');legend('实际值','预测值','fontsize',12,'fontname','TimesNewRoman');%画方框图confMat = confusionmat(output_test,Tn_sim'); %output_test是真实值标签figure;set(gca,'looseInset',[0 0 0 0])% set(gcf,'unit','centimeters','position',[5 2 23 15])zjyanseplotConfMat(confMat.'); xlabel('预测标签','fontsize',12,'fontname','TimesNewRoman');ylabel('真实标签','fontsize',12,'fontname','TimesNewRoman');title(['标准ELM分类准确率:',num2str(test_accuracy*100),'%'],'fontsize',12,'fontname','TimesNewRoman');hold off%% 采用COA优化ELMTYPE=1;[Alpha_score,bestchrom,trace]=COA(inputnum,hiddennum,TYPE,activation,inputn,output_train,inputn_test,output_test);% PSOCHOA%% 优化后结果分析figureset(gca,'looseInset',[0 0 0 0])plot(1-trace,'r--','linewidth',1)legend('COA-ELM优化曲线')title('COA适应度曲线图','fontsize',12,'fontname','TimesNewRoman');xlabel('进化代数','fontsize',12,'fontname','TimesNewRoman');ylabel('诊断正确率','fontsize',12,'fontname','TimesNewRoman');x=bestchrom;%% 把最优初始阀值权值赋予ELM重新训练与预测[W,B1,LW,activation] = angintrain(x,inputnum,hiddennum,inputn,output_train,activation,TYPE);
代码中注释非常详细,简单易懂。
代码附带UCI常用的数据集及其解释。大家可以自行尝试别的数据进行分类。附带COA算法在CEC2005函数的测试代码。