环境:python 3.9 pytorch 1.8 及其以上都可以
模型创新点还未发表, 有毕业设计或者发小论文需求的同学必看,模块丰富,创新度高,性能优越!
创新点:
1. BiTCN模块:使用了BiTCN模块来提取时序空间特征。BiTCN由多个TemporalBlock组成,每个TemporalBlock都包含两个卷积层,批标准化和ReLU激活函数,以及dropout层。此外,BiTCN还应用了权重归一化处理,加速收敛并提高模型的泛化能力。
2. BiGRU模块:采用了BiGRU模块来提取时域特征。BiGRU由多个双向GRU层组成,能够有效地捕捉序列数据中的时间依赖关系,提高了模型对时间序列的建模能力。
3. 交叉注意力机制:引入了交叉注意力机制,用于在BiTCN和BiGRU输出之间建立关联。通过计算query、key和value,交叉注意力机制能够有效地融合时空特征, 这样可以同时考虑时序关系和位置关系,从而更好地捕捉时空序列数据中的特征,增强特征的表示能力来实现高精度的预测。
4. 序列平均池化和全连接层:在模型的最后阶段,采用了序列平均池化操作和全连接层进行预测。这样的设计能够将时空特征有效地映射到预测结果空间,从而实现对序列数据的准确预测。

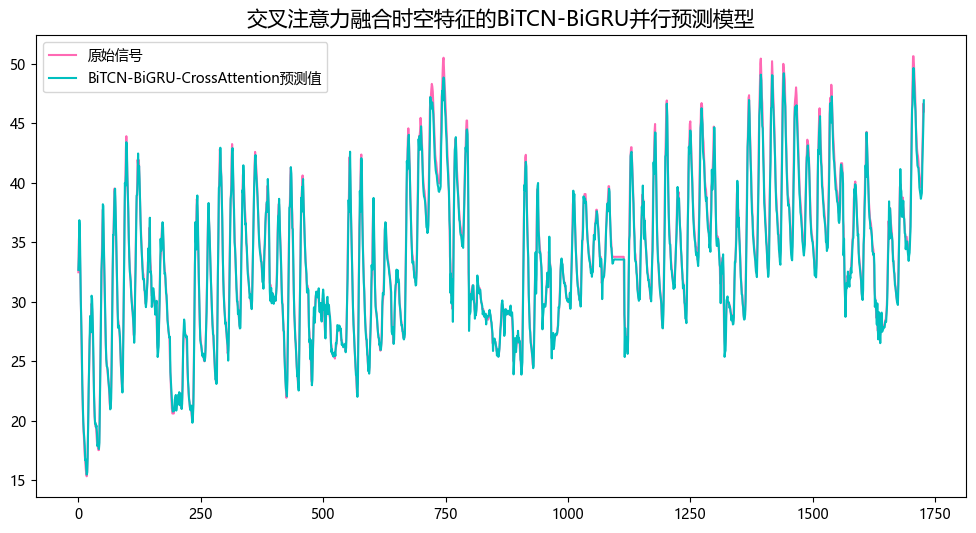
交叉注意力融合时空特征的BiTCN-BiGRU并行预测模型
注意:此次产品,我们还有配套的模型讲解和参数调节讲解!

前言
本文基于前期介绍的电力变压器( 文末附数据集 ),介绍一种基于交叉注意力融合时空特征的BiTCN-BiGRU并行预测模型,以提高时间序列数据的预测性能。 电力变压器数据集的详细介绍可以参考下文:
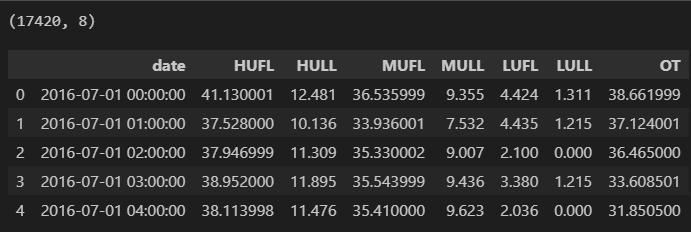
该模型 多变量特征 | 单变量序列预测都适用!
1 模型整体结构
模型整体结构如下所示,多特征变量时间序列数据先经过BiTCN网络提取全局空间特征,同时数据通过BiGRU网络提取时序特征,使用交叉注意力机制融合空间和时序特征, 通过计算注意力权重 ,使得模型更关注重要的特征再进行特征增强融合,最后经过全连接层进行高精度预测。
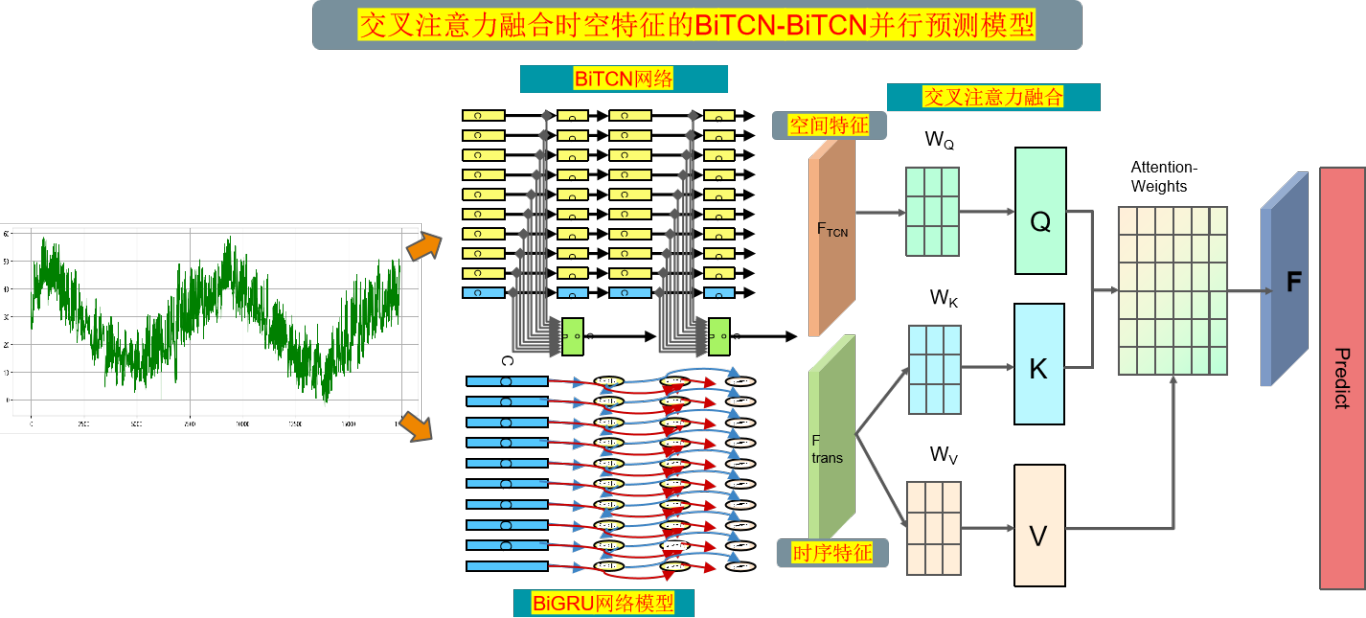
(1) 双向时空卷积网络(BiTCN):
BiTCN(双向时空卷积网络)是一种用于处理时间序列数据的神经网络模型。它主要用于提取时序空间特征,以捕捉序列数据中的空间相关性和时间依赖性。
- 双向性质:BiTCN包含两个方向的卷积操作,分别用于正向和反向的时间序列数据。这种双向设计能够有效地捕捉序列数据中前后关系,提高模型对时间依赖性的建模能力。
- 时空卷积:BiTCN使用了时空卷积操作,将卷积核在时间和空间维度上同时滑动,以获取序列数据中不同时间点和空间位置的特征信息。这种卷积操作能够有效地捕捉序列数据中的局部模式和全局趋势。
- 多层结构:BiTCN通常由多个TemporalBlock组成,每个TemporalBlock包含两个卷积层,批标准化和ReLU激活函数,以及dropout层。这种多层结构能够逐渐提取抽象层次的时序空间特征,从而提高模型的表示能力。
- 权重归一化:为了加速收敛并提高模型的泛化能力,BiTCN通常会对卷积核进行权重归一化处理。这种处理能够有效地减少训练过程中的梯度消失和爆炸问题,从而提高模型的稳定性和泛化能力。
(2) 双向门控循环单元(BiGRU):
BiGRU(双向门控循环单元)是一种用于处理序列数据的神经网络模型,它结合了循环神经网络(RNN)和门控机制的优点,能够有效地捕捉序列数据中的长期依赖关系和局部模式。
- 双向性质:BiGRU包含两个方向的GRU单元,分别用于正向和反向的序列数据。这种双向设计使得模型能够同时考虑到序列数据中前后位置的信息,从而更好地理解序列中的上下文关系。
- 门控机制:GRU单元通过门控机制来控制信息的流动,包括重置门(reset gate)和更新门(update gate)。这些门控机制能够有效地控制信息的传递和保存,防止梯度消失或爆炸,并且提高模型对长期依赖关系的建模能力。
- 隐藏状态:BiGRU具有隐藏状态,可以在每个时间步上捕获序列数据的信息。这些隐藏状态包含了模型对序列数据的理解和表示,可以用于后续任务的预测。
- 多层结构:BiGRU通常由多个双向GRU层组成,每一层都能够提取不同层次的序列特征。通过堆叠多个层,模型可以逐渐提高对序列数据的抽象能力和表征能力。
(3) 交叉注意力融合:
- 使用交叉注意力机制融空间和时序特征,可以通过计算注意力权重,学习时空特征中不同位置之间的相关性,可以更好地捕捉时空序列数据中的特征,提高模型性能和泛化能力。
2 多特征变量数据集制作与预处理
2.1 导入数据
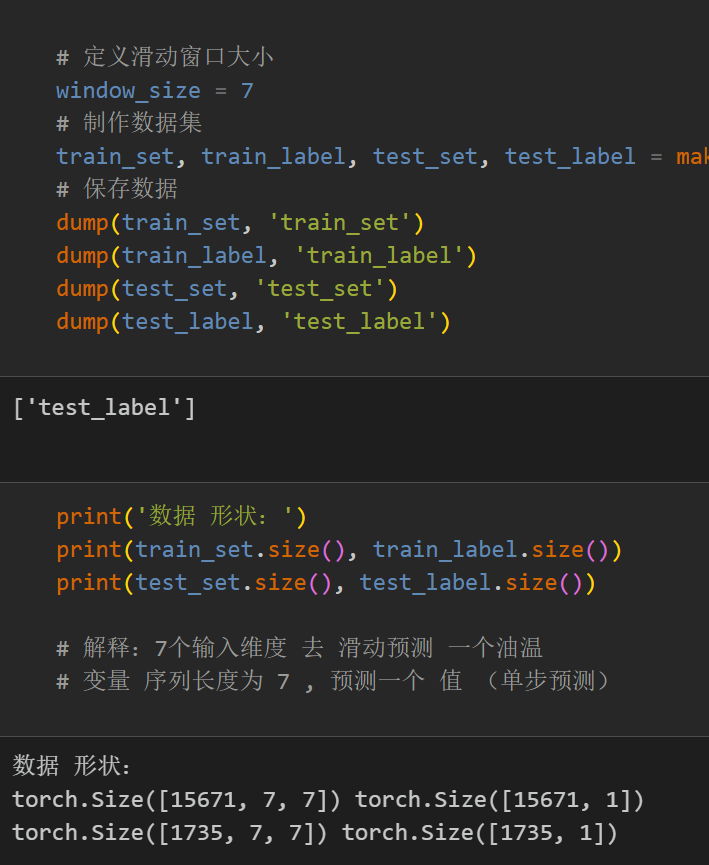
2.2 制作数据集
制作数据集与分类标签
3 交叉注意力机制
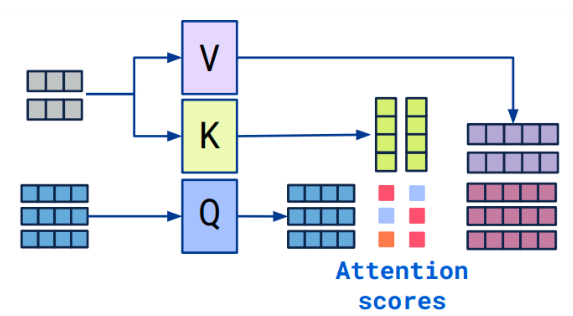
3.1 Cross attention概念
- Transformer架构中混合两种不同嵌入序列的注意机制
- 两个序列必须具有相同的维度
- 两个序列可以是不同的模式形态(如:文本、声音、图像)
- 一个序列作为输入的Q,定义了输出的序列长度,另一个序列提供输入的K&V
3.2 Cross-attention算法
- 拥有两个序列S1、S2
- 计算S1的K、V
- 计算S2的Q
- 根据K和Q计算注意力矩阵
- 将V应用于注意力矩阵
- 输出的序列长度与S2一致
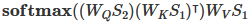
在融合过程中,我们将经过Transformer的时序特征作为查询序列,TCN提取的全局空间特征作为键值对序列。通过计算查询序列与键值对序列之间的注意力权重,我们可以对不同特征之间的关联程度进行建模。
4 基于BiTCN-BiGRU-CrossAttention的高精度预测模型
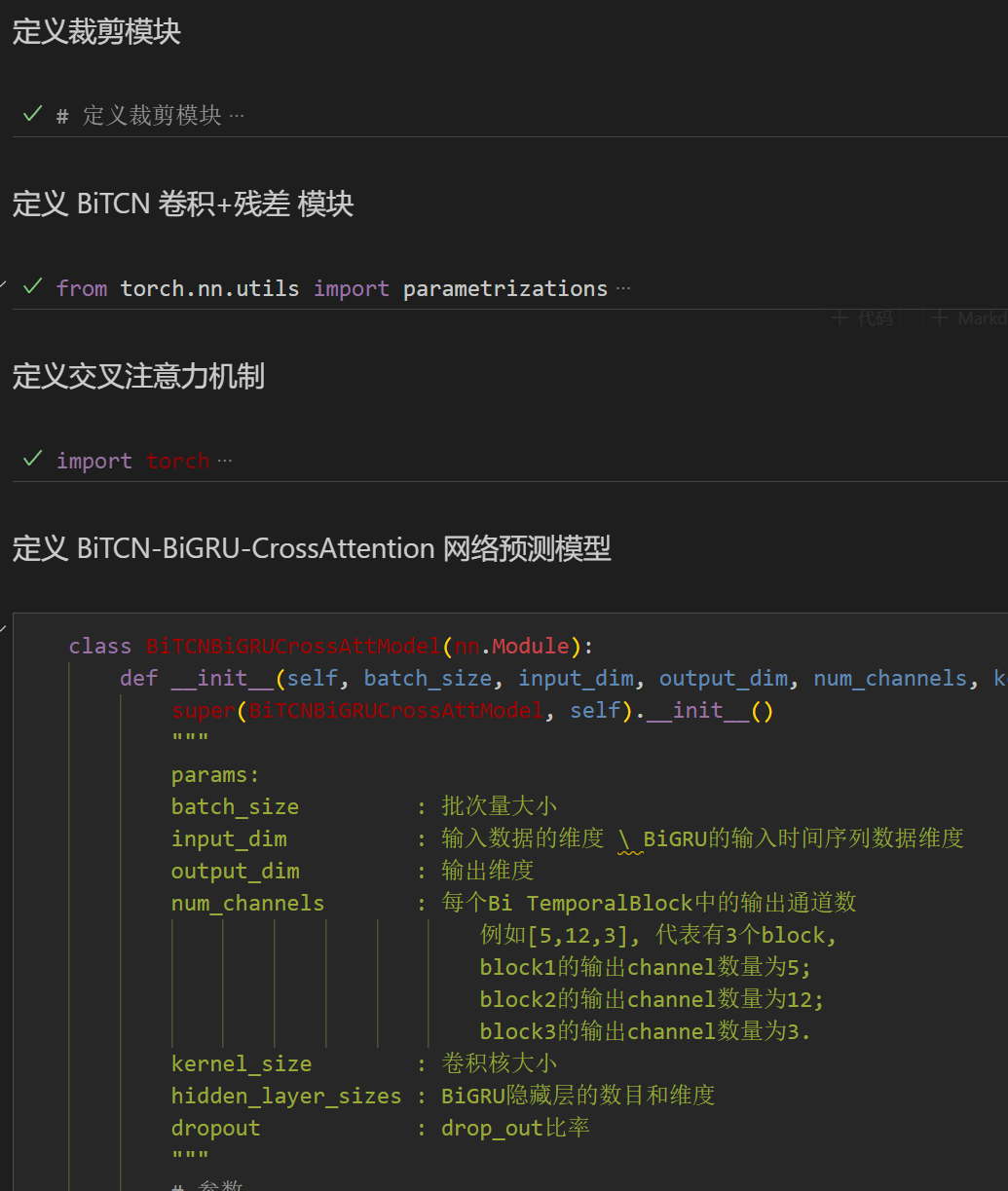
4.1 定义网络模型
4.2 设置参数,训练模型
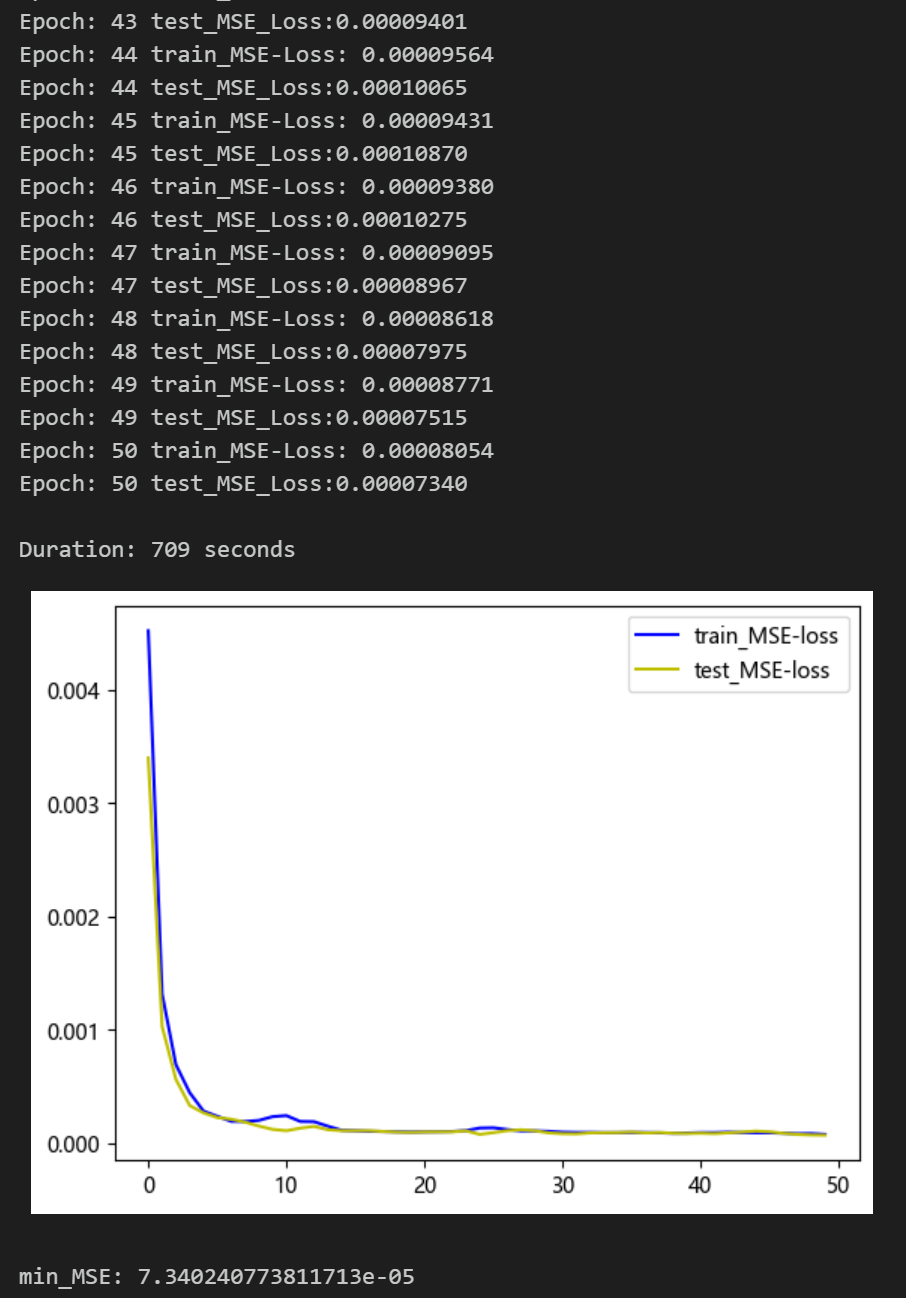
50个epoch,训练误差极小,多变量特征BiTCN-BiGRU-CrossAttention融合网络模型预测效果显著,模型能够充分提取时间序列的空间特征和时序特征,收敛速度快,性能优越,预测精度高,交叉注意力机制能够对不同特征之间的关联程度进行建模,从序列时空特征中于提取出对模型预测重要的特征,效果明显!
4.3 模型评估和可视化
预测结果可视化
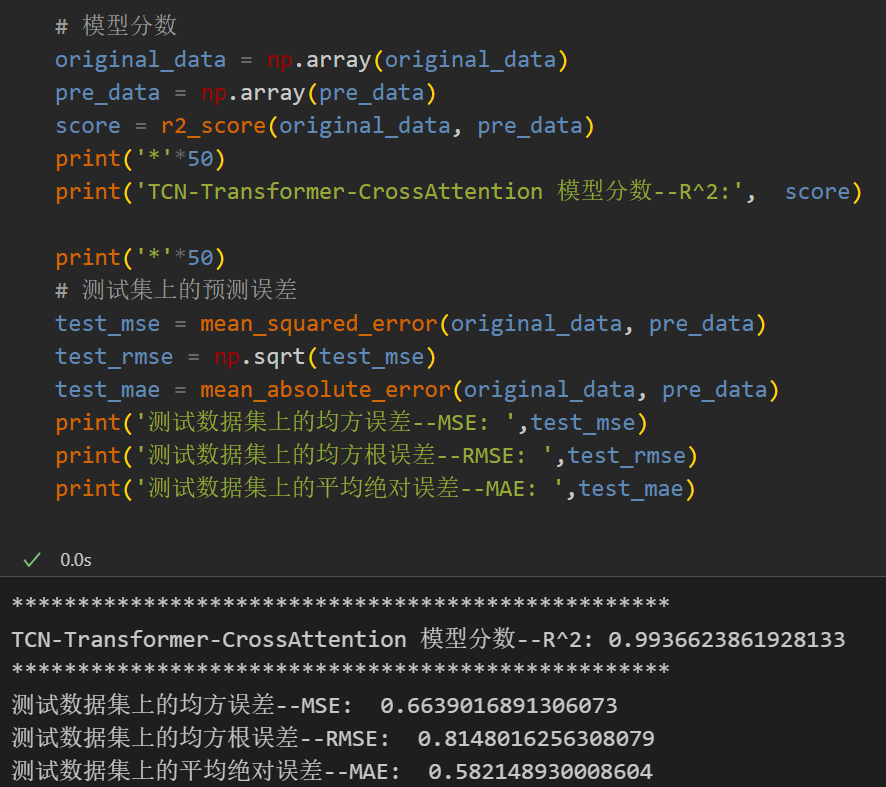
模型评估
往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较
风速预测(四)基于Pytorch的EMD-Transformer模型
风速预测(五)基于Pytorch的EMD-CNN-LSTM模型
风速预测(六)基于Pytorch的EMD-CNN-GRU并行模型
CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)
CEEMDAN +组合预测模型(CNN-LSTM + ARIMA)
CEEMDAN +组合预测模型(Transformer - BiLSTM + ARIMA)
CEEMDAN +组合预测模型(CNN-Transformer + ARIMA)
多特征变量序列预测(二)——CNN-LSTM-Attention风速预测模型
多特征变量序列预测(三)——CNN-Transformer风速预测模型
多特征变量序列预测(四) Transformer-BiLSTM风速预测模型
多特征变量序列预测(五) CEEMDAN+CNN-LSTM风速预测模型
多特征变量序列预测(六) CEEMDAN+CNN-Transformer风速预测模型
基于麻雀优化算法SSA的CEEMDAN-BiLSTM-Attention的预测模型
基于麻雀优化算法SSA的CEEMDAN-Transformer-BiGRU预测模型
多特征变量序列预测(七) CEEMDAN+Transformer-BiLSTM预测模型
多特征变量序列预测(八)基于麻雀优化算法的CEEMDAN-SSA-BiLSTM预测模型
多特征变量序列预测(11) 基于Pytorch的TCN-GRU预测模型
VMD + CEEMDAN 二次分解,CNN-LSTM预测模型
VMD + CEEMDAN 二次分解,CNN-Transformer预测模型
高创新 | CEEMDAN + SSA-TCN-BiLSTM-Attention预测模型