本文是运用jupyter notebook来撰写代码
提供全代码
下方是简单将结果展示,与CSDN博客相连--保真
#导入需要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
from pandas import Series
from sklearn.metrics import mean_squared_error
from math import sqrt
from statsmodels.tsa.seasonal import seasonal_decompose
import statsmodels
import statsmodels.api as sm
from statsmodels.tsa.arima_model import ARIMA
%matplotlib inline
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
import seaborn as sns
df = pd.read_csv("order_train0.csv")#访问数据

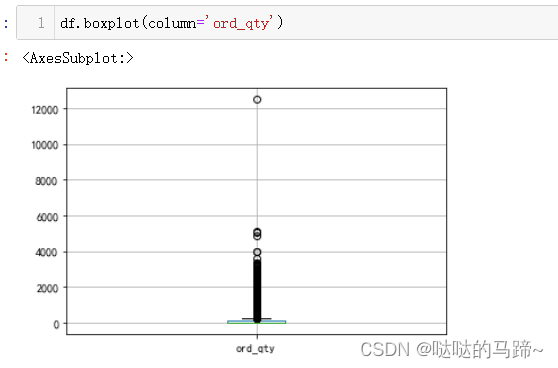
#从上方可以看出,价格最大值去到47911,最大需求去到12480,远大于一般商品
#查看价格分布、需求分布状况

#检验数据是否呈现正态分布
def KsNormDetect(df): # 输出结果是服从正态分布的数据列的名字
from scipy.stats import kstest
list_norm_T = [] # 用来储存服从正态分布的数据列的名字
for col in df.columns:
*********** # 计算均值
*********** # 计算标准差
*********** # 计算P值
if res<=0.05: # 判断p值是否服从正态分布,p<=0.05 则服从正态分布,否则不服从
print(f'{col}该列数据服从正态分布------')
print('均值为:%.3f,标准差为:%.3f' % (u, std))
print('-'*40)
**************
else: # 这一段实际上没什么必要
print(f'!!!{col}该列数据不服从正态分布**********')
print('均值为:%.3f,标准差为:%.3f' % (u, std))
print('*'*40)
KsNormDetect(df[['item_price', 'ord_qty']])

# 对待处理数据中心服从正态分布的数据列
def three_sigma(Ser1): # Ser1:表示传入DataFrame的某一列
rule = []
***********************
***********************
print(len(out))
return out # 返回落在3sigma之外的行索引值
def delete_out3sigma(data, list_norm): # data:待检测的DataFrame;list_norm:服从正态分布的数据列名
out_index = [] # 保存要删除的行索引
for col in list_norm: # 对每一列分别用3sigma原则处理
***************************
***************************
****************** # 去除 out_index 中的重复元素
print(f'\n所删除的行索引共计{len(delete_)}个:\n',delete_)
data.drop(delete_,inplace=True) # 根据 delete_ 删除对应行的数据
df = data
return df
delete_out3sigma(df,['item_price','ord_qty'])

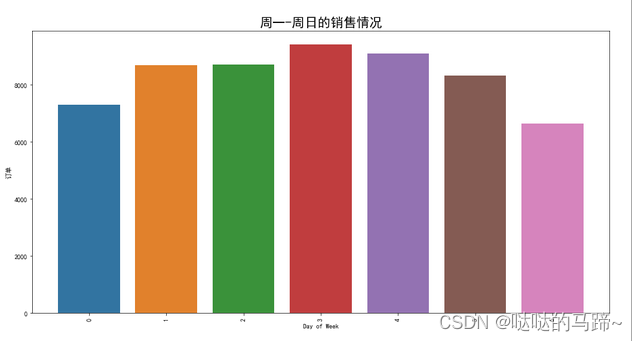
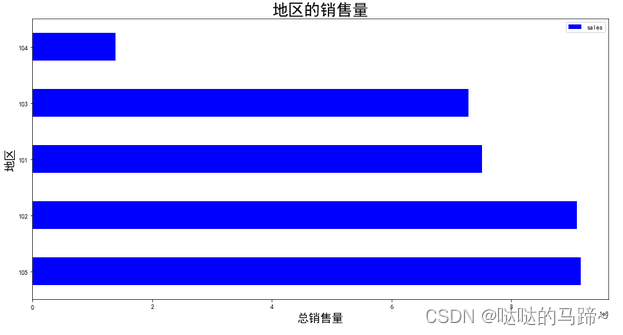
#再次查看分布状况

![]() 编辑
编辑

![]() 编辑
编辑









![]() 编辑
编辑