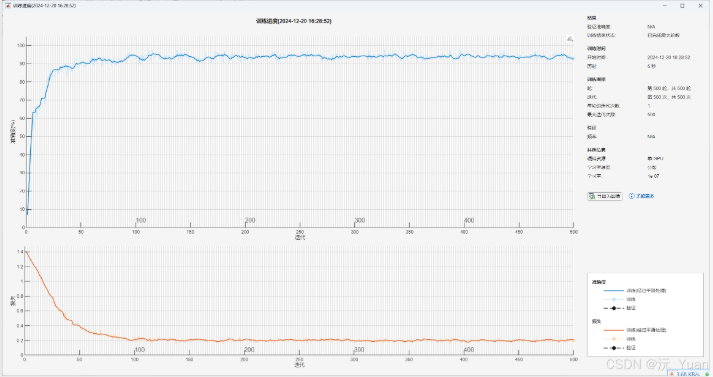
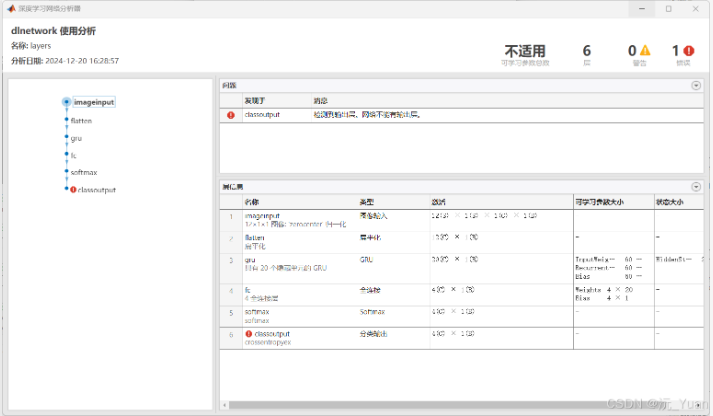
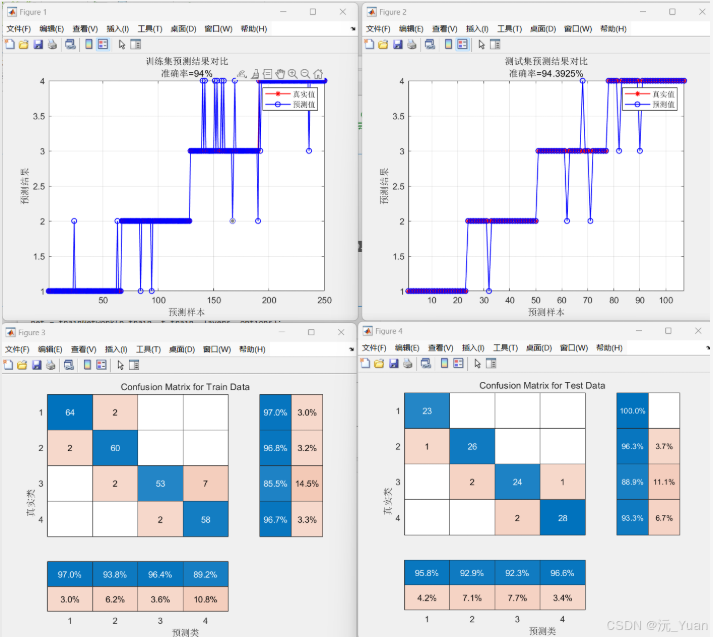
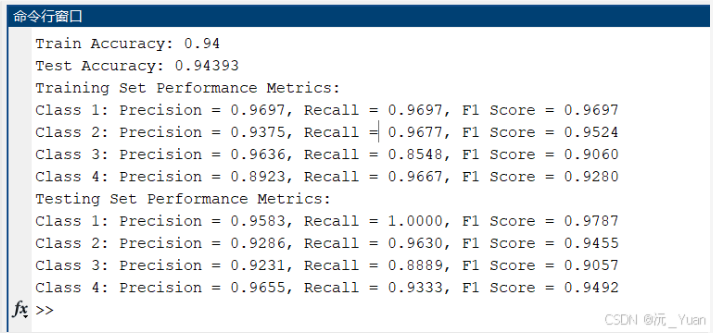
随着深度学习的不断发展,循环神经网络(RNN)在处理时间序列和自然语言处理等领域表现出了强大的能力。然而,传统RNN存在梯度消失和梯度爆炸问题,导致其在长序列任务中的表现受限。为了应对这些问题,门控循环单元(Gated Recurrent Unit,GRU)应运而生。GRU是一种高效的循环神经网络变体,能够在保持信息的同时减少计算复杂度。本文将详细解析GRU的原理、结构以及其在多分类预测中的应用。
一、GRU
GRU是一种改进型的循环神经网络,最早由Chung等人在2014年提出。它通过引入门控机制(Gate Mechanism),能够在长时间序列中有效捕获信息。相比于长短时记忆网络(LSTM),GRU结构更简单,参数更少,同时能够达到与LSTM相近的性能。
GRU的核心在于两个门:
更新门(Update Gate):决定当前状态中保留多少历史信息,以及添加多少新信息。
重置门(Reset Gate):决定丢弃多少历史信息。
二、GRU的核心结构与工作原理
GRU的核心组件包括:
1. 隐藏状态(Hidden State)
隐藏状态是GRU的记忆单元,存储当前时间步的信息。
2. 更新门(Update Gate)
更新门控制新信息与旧信息的权重平衡
3. 重置门(Reset Gate)
重置门决定需要丢弃多少历史信息
4. 候选隐藏状态(Candidate Hidden State)
候选隐藏状态是当前时间步新的信息
5. 隐藏状态更新
最终的隐藏状态通过更新门结合当前状态和历史状态计算得出
三、GRU的优势
参数更少:相比LSTM,GRU没有单独的记忆细胞(Cell State),只需两个门(LSTM有三个门),因此训练更高效。
长依赖捕获:通过门控机制,GRU能够有效缓解梯度消失问题。
简单易用:由于其结构较为简单,GRU在许多实际任务中可达到与LSTM相近甚至更优的性能。