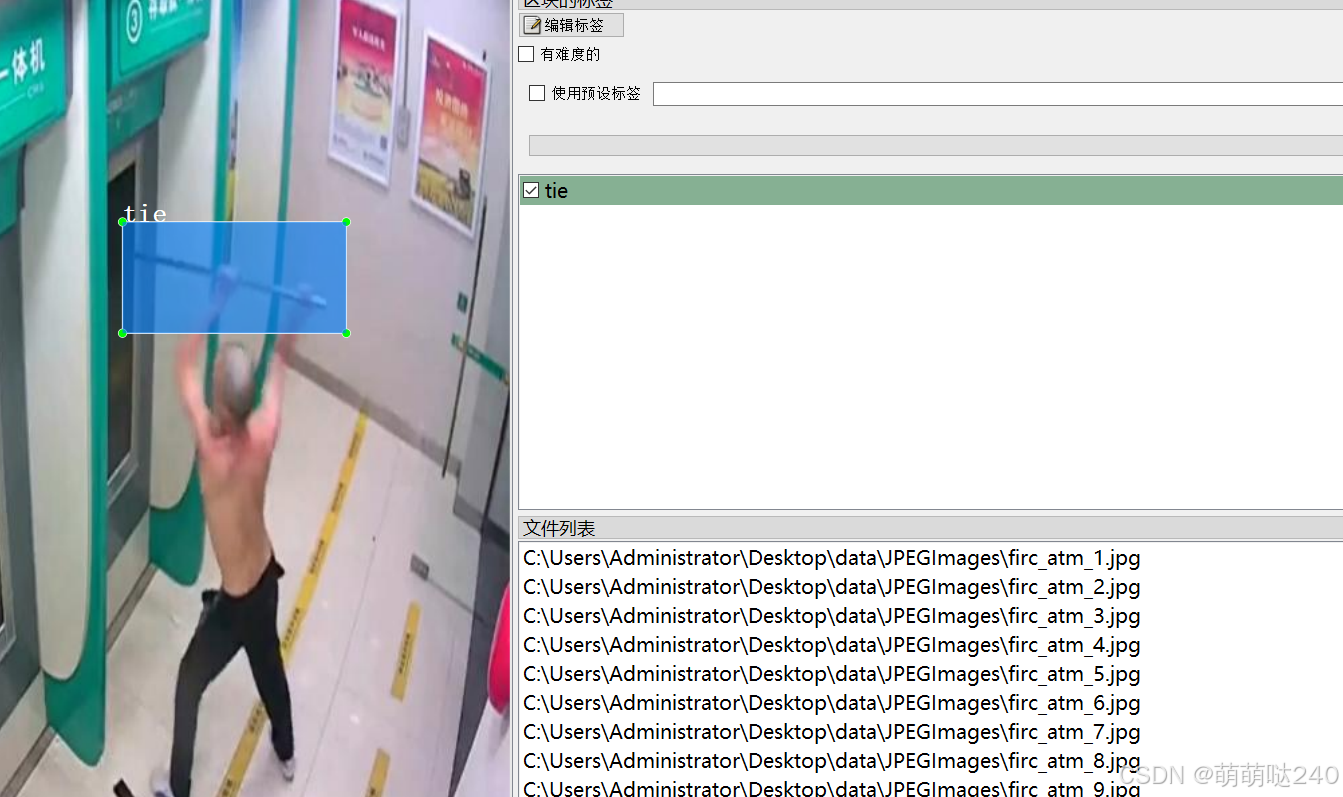
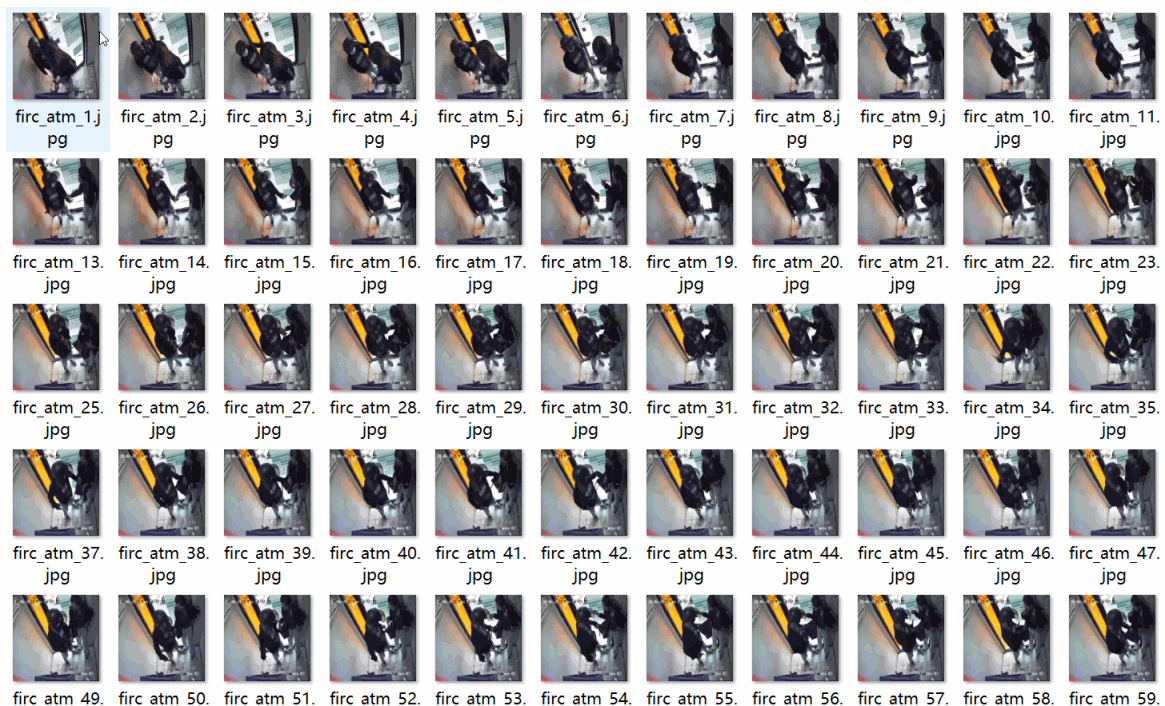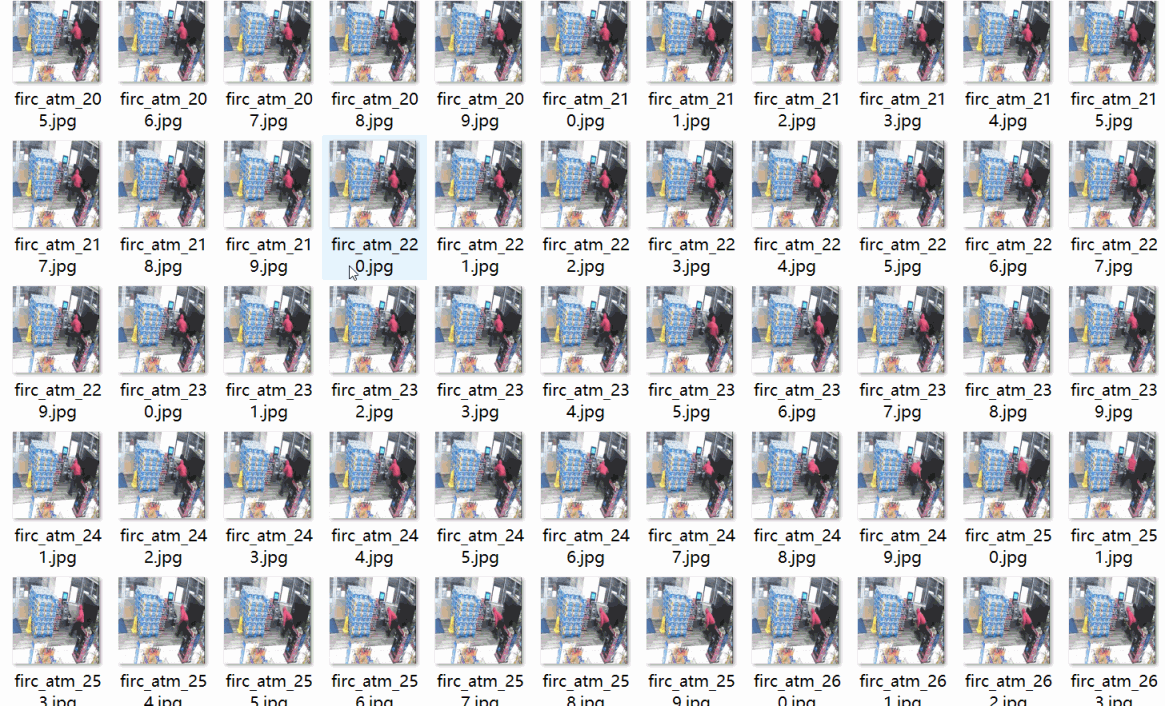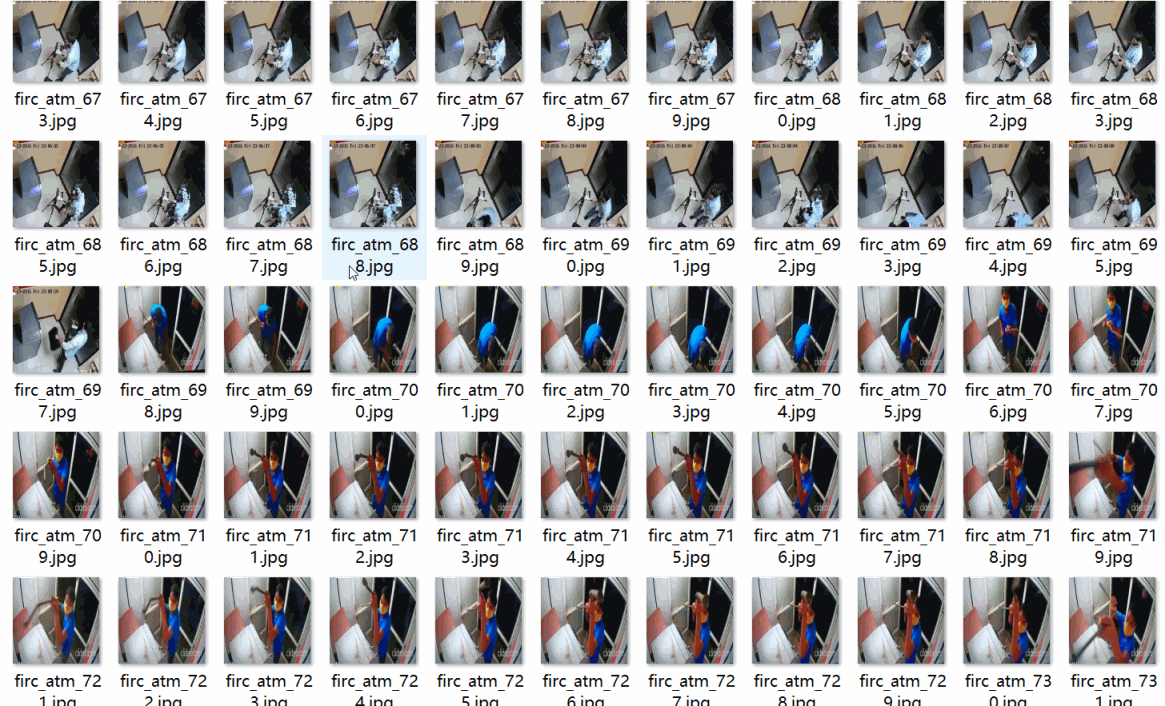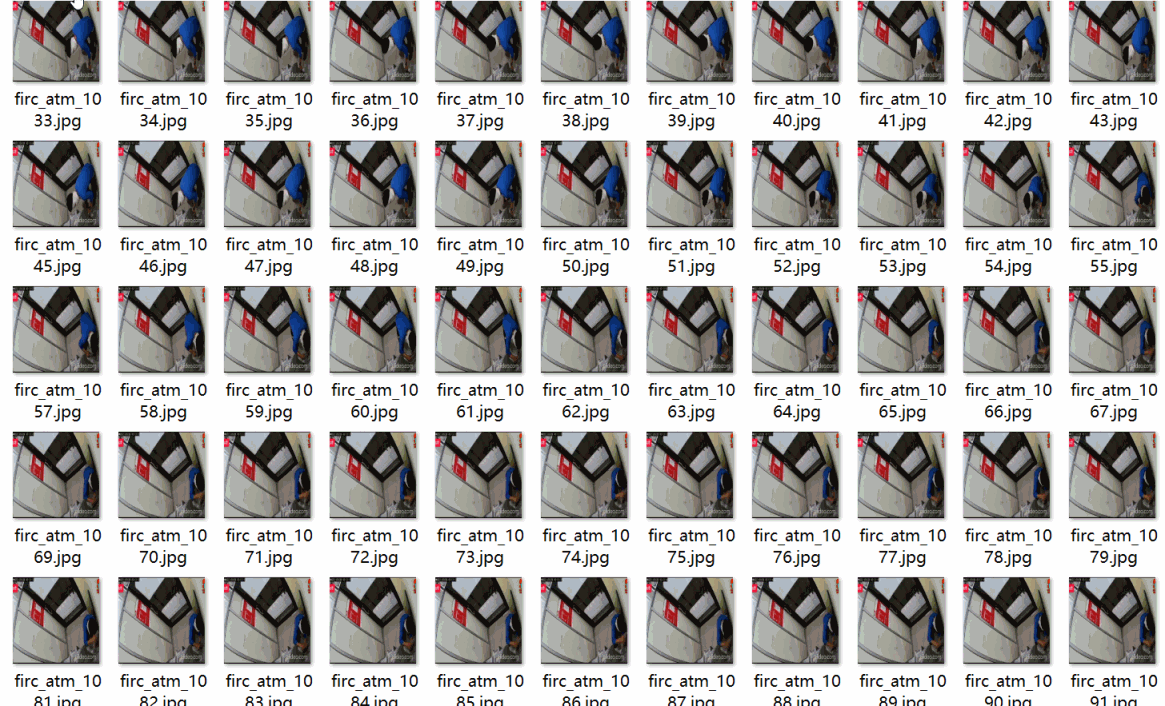
重要说明:数据集来自大约9段视频截取,看起来场景有点重复,请认真看图片预览确认符合要求在下载 数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1251 标注数量(xml文件个数):1251 标注数量(txt文件个数):1251 标注类别数:5 标注类别名称:["dao","qiang","tie","wuti","zhongwu"] 对应中文为,刀,枪,铁器,物体,重物 每个类别标注的框数: dao 框数 = 156 qiang 框数 = 129 tie 框数 = 642 wuti 框数 = 234 zhongwu 框数 = 188 总框数:1349 使用标注工具:labelImg 标注规则:对类别进行画矩形框 图片分辨率:640x640 特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注 图片预览:
标注例子: