一、项目概述
1.1 项目名称
基于深度学习的恶意流量检测平台 v3.0
1.2 项目简介
本项目是一个基于Python开发的恶意网络流量检测系统,采用深度学习(CNN、LSTM)与传统机器学习(随机森林、逻辑回归)相结合的混合架构,通过PyQt5构建可视化操作界面,支持离线数据检测和实时网卡流量捕获分析。
1.3 开发背景
随着网络攻击手段的日益复杂化和加密流量的普及,传统的基于规则的安全防护手段已难以满足需求。本项目旨在构建一个智能化、可视化的流量检测平台,为网络安全防护提供技术支撑。
二、v3.0 升级说明(相对于 v2.0)
2.1 实时检测准确率大幅提升
问题背景:v2.0 实时检测误报率极高,正常流量被大量误判为攻击。
根本原因修复:
- 特征提取对齐 CICFlowMeter
- 修复标志位统计方式:从"计数"改为"二值化"(0/1),与 CICFlowMeter 训练数据提取逻辑一致
- 修复
Flow Byts/s、Flow Pkts/s等速率特征:除数从pkt_count改为flow_duration,与训练数据一致 - 修复
Active/Idle时间计算:流过期时结束最后一个活跃期,短流不再全为 0
- 特征预处理一致性
- 检测引擎
_prepare_features新增np.clip(X, -3, 3)截断,防止实时特征分布偏移导致极端值误判 - 统一所有模型的归一化策略为 StandardScaler 单步归一化(v2.0 的
train_all_models.py使用 StandardScaler+MinMaxScaler 双重归一化,与 GUI/实时检测不一致)
- 流成熟度门槛提升
MIN_PACKETS从 5 提高到 10,PACKET_INCREMENT从 5 提高到 10- 避免不成熟流的统计特征不稳定导致的误判
- 增量重新检测机制
- 新增
detected_flow_packet_counts跟踪每个流上次检测时的包数 - 同一流在包数显著增长(≥10 个新包)后重新检测,让早期误判在特征稳定后有机会被纠正
- 表格中同一
flow_id的多次检测结果更新到现有行,而非不断追加新行
- 恶意流统计修复
- 修复
malicious_flows重复累加 bug:同一流被多次检测时不再重复计数 - 新增
malicious_flow_ids集合跟踪已标记为恶意的流,流从恶意变为正常时自动 -1
- 三色展示体系
- 绿色:
Benign(正常流量) - 红色:非
Benign且置信度 ≥ 阈值(高置信度攻击) - 黄色:非
Benign但置信度 < 阈值(低置信度疑似攻击) - 恶意流统计只计红色行,阈值滑块同时控制标红/告警,避免低置信度预测造成视觉误报
2.2 训练数据集与训练流程修复
- 统一特征选取方式
- 所有训练方法(GUI 4个模型 +
train_all_models.py+retrain_rf_logistic.py)统一使用FEATURE_COLUMNS按列名选取特征 - v2.0 使用
df.iloc[:, :-1]按位置选取,CSV 列顺序不同时会导致特征错位
- RF 训练/推理一致性
- GUI
_train_rf新增 StandardScaler 并保存scaler.pkl - 检测引擎
load_rf_model新增加载scaler.pkl,推理时做 scaler 变换 - v2.0 RF 训练不做归一化、不保存 scaler,但检测引擎逻辑已准备加载 scaler,导致不一致
- load_all 默认包含 Benign
IDS2018DataLoader.load_all增加include_benign=True默认参数- v2.0
load_all只加载攻击类不含 Benign,误用会导致模型无法识别正常流量
- ICNN 维度检查
- GUI
_train_icnn新增X.shape[1] != 78检查,与 LSTM 保持一致
- 分层采样
- 所有
train_test_split调用添加stratify=y,确保各类别在训练/测试集中比例一致
- 模型文件分别保存 scaler 和 label_encoder
train_all_models.py中 CNN/LSTM/RF 训练完成后分别保存scaler.pkl和label_encoder.pkl到各自模型目录- v2.0 CNN/LSTM 模型未保存 scaler,推理时检测引擎找不到 scaler 不做归一化
2.3 模型重训练
- 随机森林:重新训练后测试准确率从 ~70% 提升至 89.81%
- 逻辑回归:重新训练后测试准确率从 ~70% 提升至 85.97%
- 使用修复后的正确标签(消除标签覆盖 bug 后的 CSE-CIC-IDS2018 数据)
- 每类最多采样 50,000 条,使用
class_weight='balanced'处理类别不平衡
三、技术架构
3.1 核心技术栈
技术领域
使用技术
版本要求
深度学习框架
PyTorch
≥1.12.0
GUI开发
PyQt5
≥5.15.0
机器学习
scikit-learn
≥1.0.0
数据处理
pandas, numpy
≥1.3.0, ≥1.21.0
数据可视化
matplotlib
≥3.5.0
网络抓包
scapy
≥2.4.5
数据库
SQLite3
三、功能模块
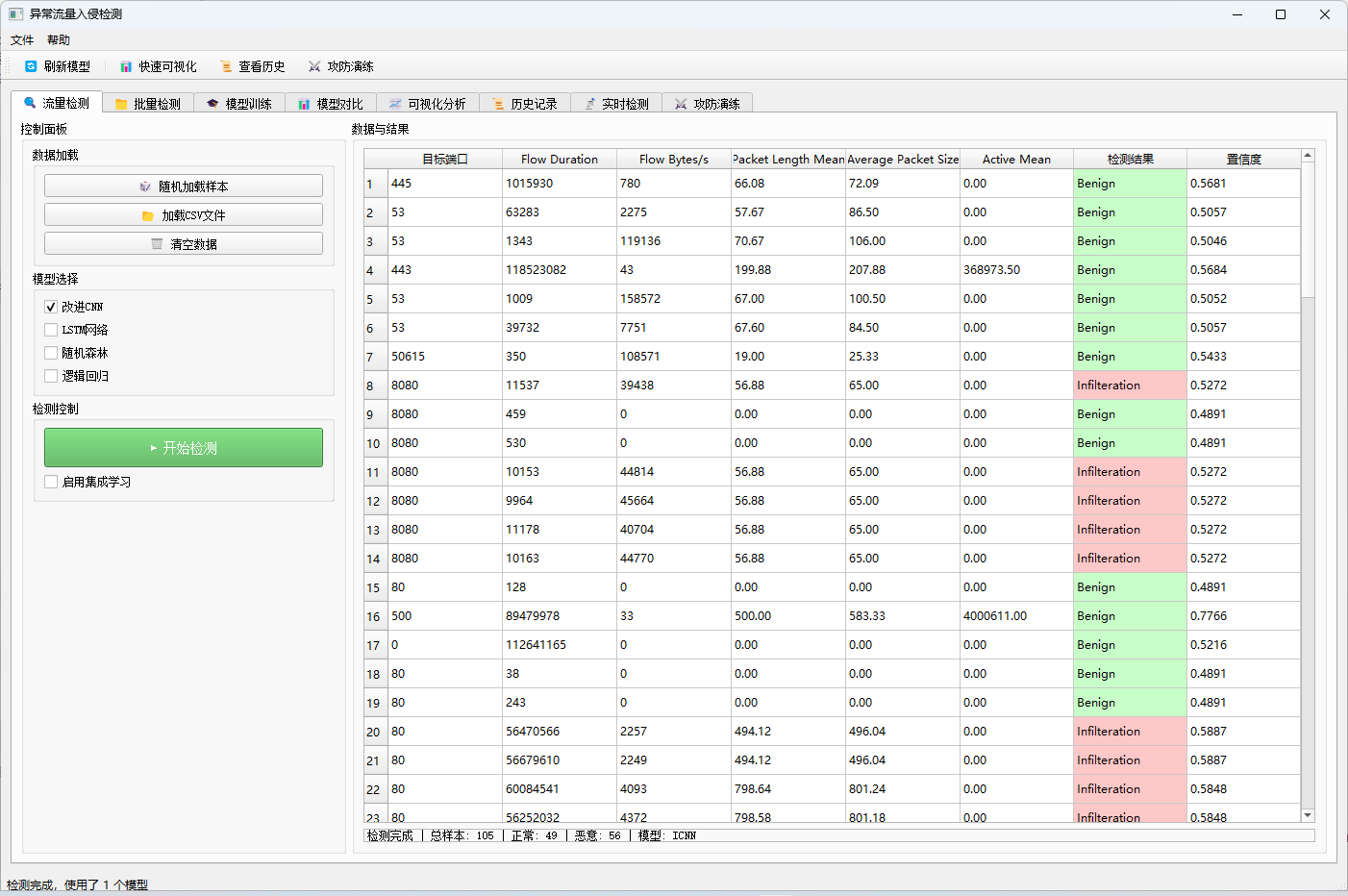
3.1 流量检测模块
- 随机样本检测:从数据集中随机抽取样本进行快速检测
- 文件导入检测:支持CSV格式数据文件导入检测
- 多模型选择:可同时选择多个模型进行检测对比
- 集成学习:支持多模型软投票/硬投票的集成预测
- 结果可视化:检测结果实时显示,支持置信度展示
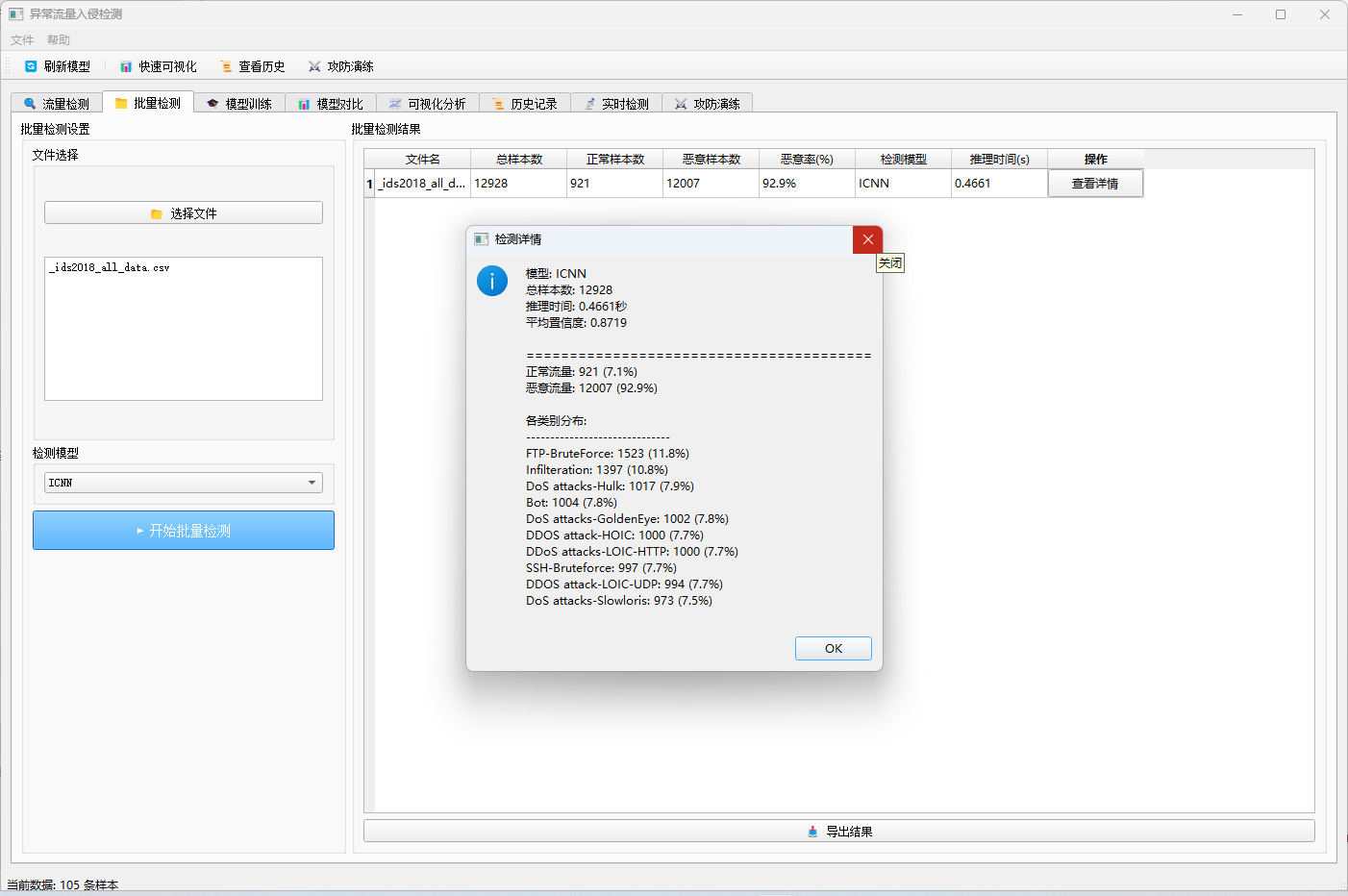
3.2 批量检测模块
- 多文件处理:支持同时选择多个CSV文件进行批量检测
- 进度显示:实时显示检测进度
- 结果统计:批量检测结果汇总统计(总样本数、正常/恶意样本数、恶意率)
- 详情查看:支持查看单个文件的详细检测结果
- 报告导出:支持检测结果导出为CSV格式
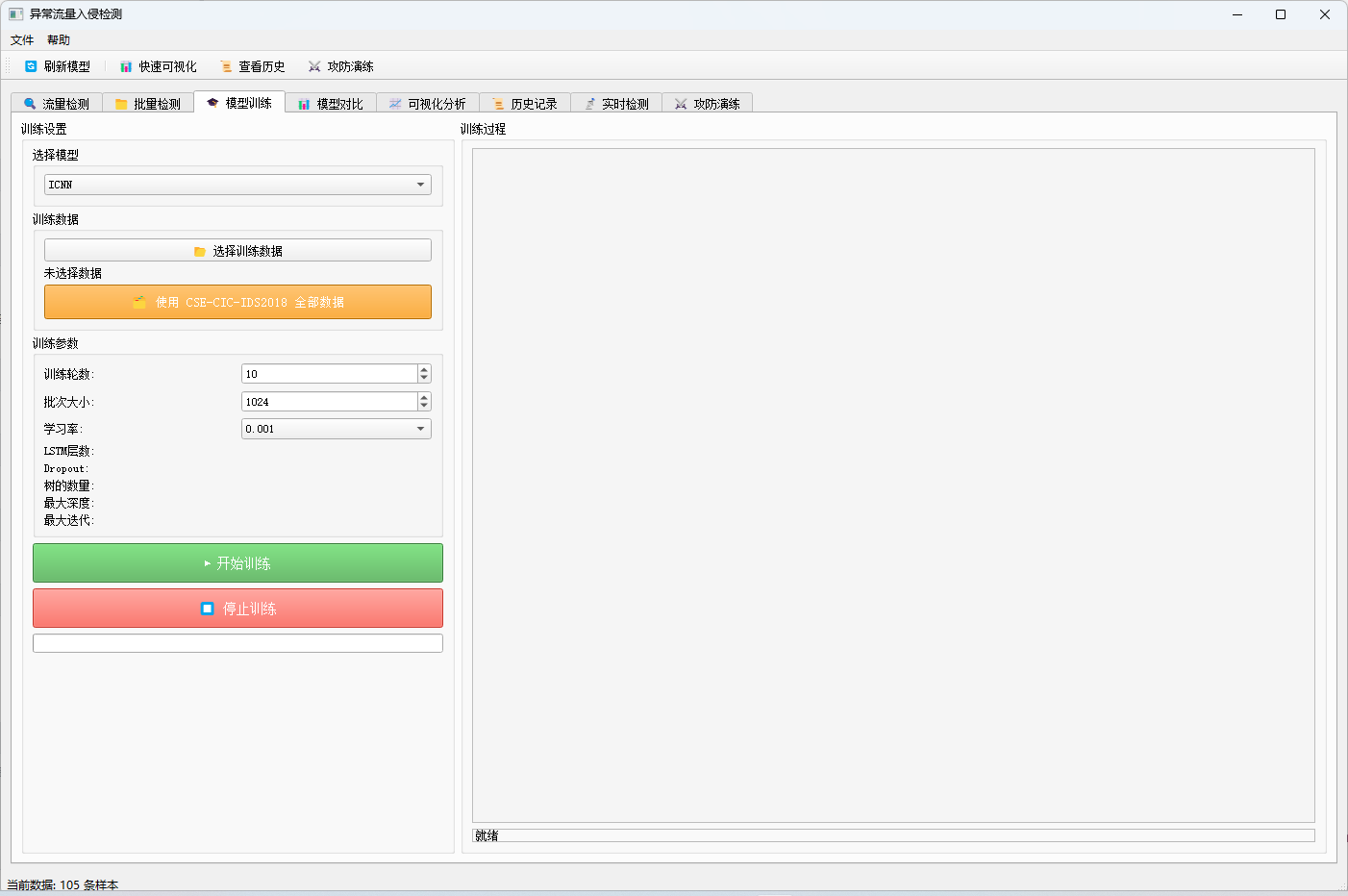
3.3 模型训练模块
- 多模型支持:支持ICNN、LSTM、随机森林、逻辑回归四种模型训练
- 参数配置:
- 深度学习模型:训练轮数、批次大小、学习率
- LSTM特有:层数、Dropout率
- 随机森林:树的数量、最大深度
- 逻辑回归:最大迭代次数
- 特征选取一致性(v3.0):所有模型训练统一使用
FEATURE_COLUMNS按列名选取特征,确保训练/推理特征顺序一致 - 归一化一致性(v3.0):所有模型统一使用 StandardScaler 单步归一化,RF 训练后也保存 scaler
- 分层采样(v3.0):
train_test_split自动按类别分层,确保测试集类别分布均衡 - 维度检查(v3.0):ICNN/LSTM 训练前检查特征维度是否为 78
- 实时日志:训练过程实时显示,包含每轮损失和验证准确率
- 训练控制:支持开始/停止训练
- 自动保存:训练完成后自动保存模型、scaler 和 label_encoder
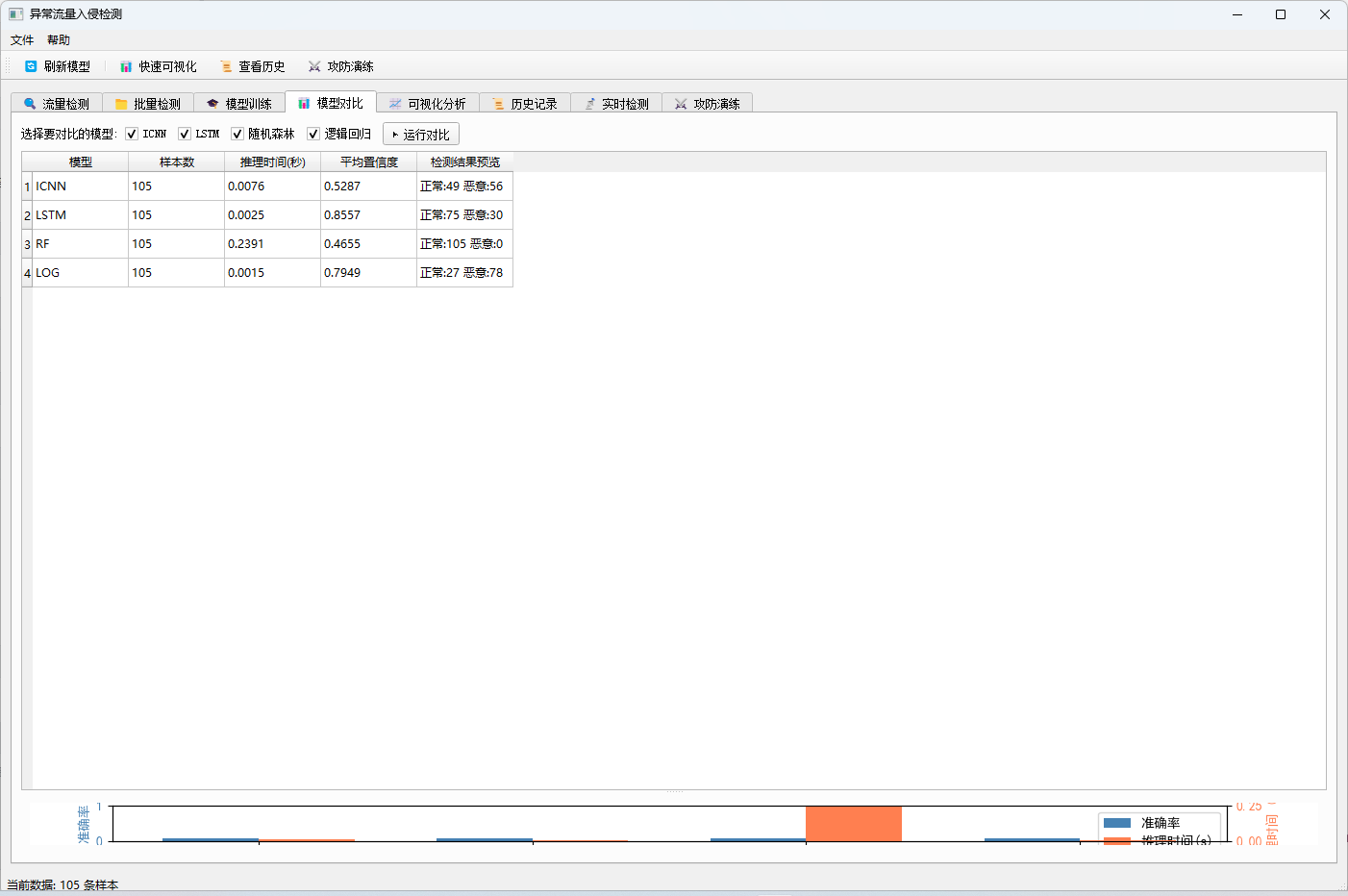
3.4 模型对比模块
- 多模型并行:同时运行多个模型进行性能对比
- 指标对比:样本数、推理时间、平均置信度、检测结果预览
- 可视化图表:生成对比图表直观展示模型性能差异
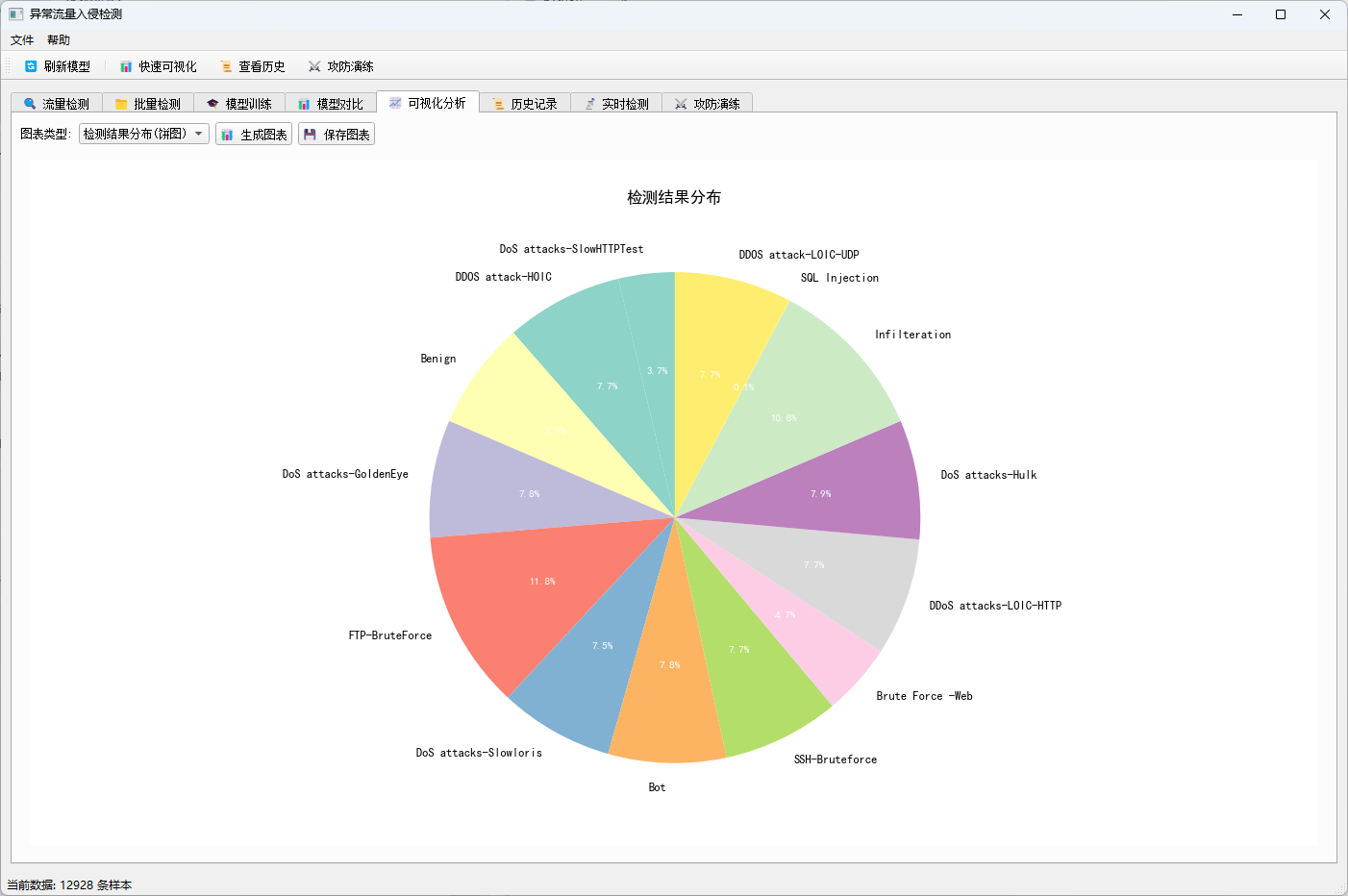
3.5 可视化分析模块
- 饼图:检测结果分布展示
- 柱状图:各类别数量统计
- 直方图:置信度分布分析
- 图表导出:支持PNG、PDF格式导出
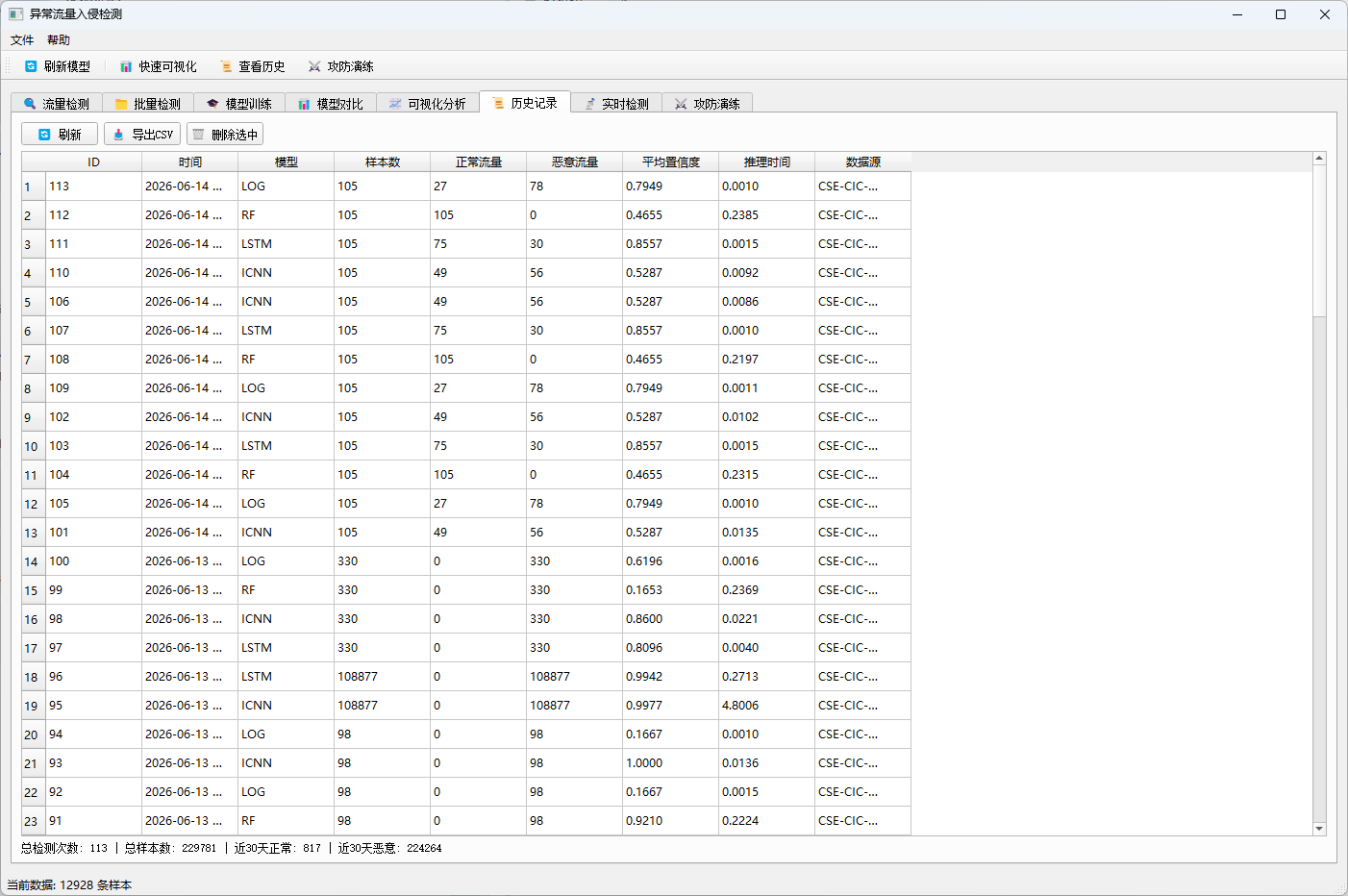
3.6 历史记录模块
- 检测日志:自动保存所有检测记录到SQLite数据库
- 数据查询:支持按时间、模型等条件查询
- 统计分析:历史数据统计报表(总检测次数、总样本数、正常/恶意流量统计)
- 数据导出:支持历史记录导出为CSV
- 记录管理:支持删除单条记录
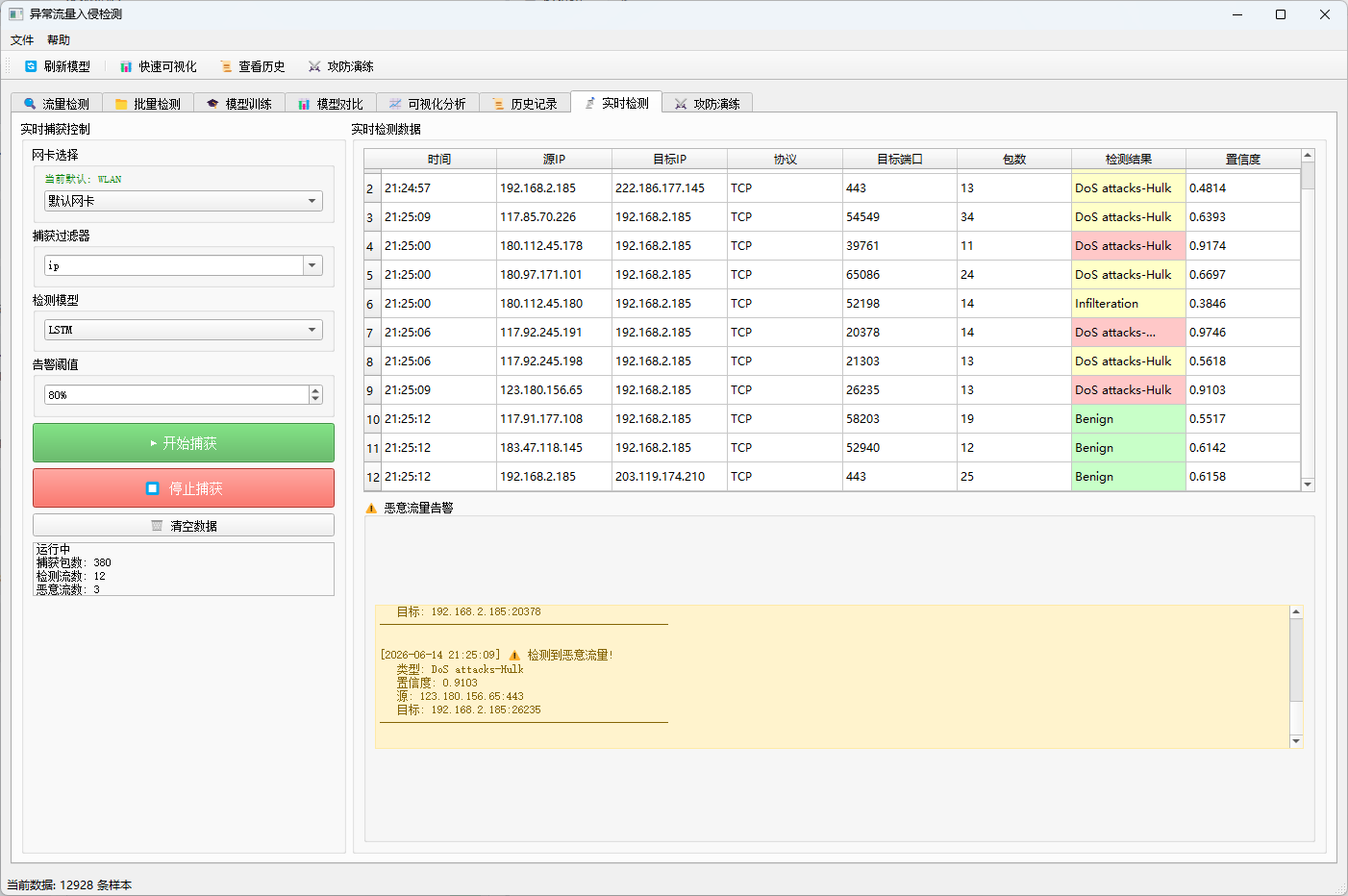
3.7 实时检测模块 ⭐(v3.0 大幅优化)
- 网卡捕获:实时捕获网卡数据包(基于Scapy)
- BPF过滤:支持Berkeley Packet Filter过滤规则
- 流特征提取:实时提取78维流特征(与CICFlowMeter对齐)
- 流成熟度控制:只检测包数≥10的成熟流,避免早期特征不稳定导致的误判
- 增量重新检测:同一流在新增≥10个包后自动重新检测,让早期误判有机会被纠正
- 三色展示体系:
- 绿色 =
Benign(正常流量) - 红色 = 高置信度攻击(置信度≥阈值)
- 黄色 = 低置信度疑似攻击(置信度<阈值)
- 告警通知:只对高置信度攻击触发实时告警
- 统计信息:实时显示捕获包数、检测流数、恶意流数(恶意流计数去重,不再重复累加)
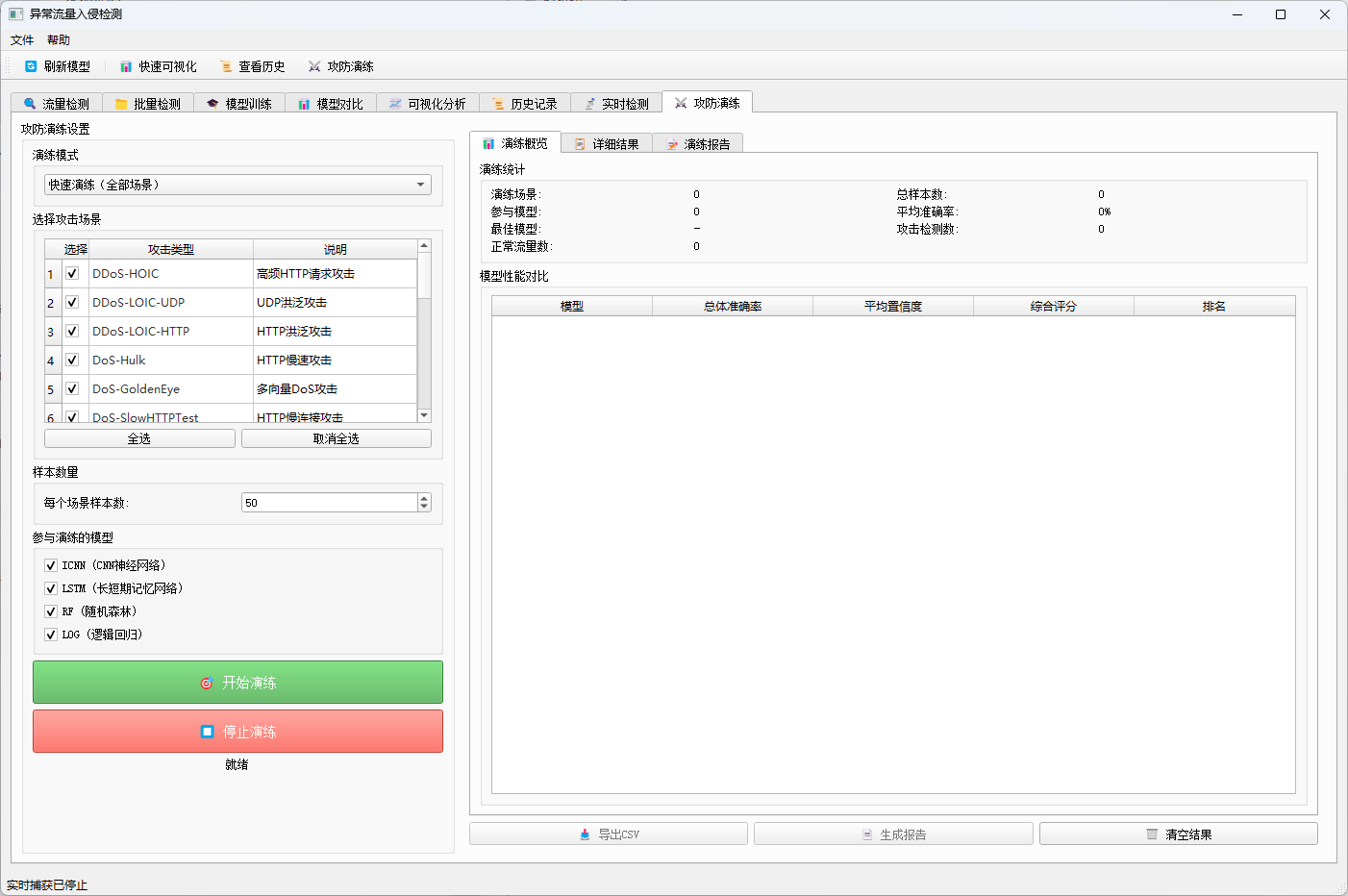
3.8 攻防演练模块 ⚔️
- 多种攻击场景:支持16种网络攻击场景模拟(DDoS、DoS、僵尸网络、端口扫描、暴力破解、Web攻击等)
- 自定义演练:可选择特定攻击场景进行专项演练
- 多模型对比:同时使用多个检测模型进行演练,对比检测效果
- 演练报告:自动生成演练报告,包含检测准确率、置信度、综合评分等指标
- 数据导出:支持导出演练结果为CSV格式,方便后续分析
- 可视化评估:提供演练概览、详细结果、综合报告等多个视角的展示
四、模型说明
4.1 ICNN(改进卷积神经网络)
- 模型类型:一维卷积神经网络
- 输入维度:78维特征向量
- 输出类别:15类(正常+14种攻击)
- 网络结构:
- 4层卷积层(通道数:1→32→64→64→128)
- 2层最大池化层
- 3层全连接层(2304→64→64→15)
- 特点:适合提取流量数据的局部特征
4.2 LSTM(长短期记忆网络)
- 模型类型:循环神经网络
- 输入维度:78维特征向量
- 隐藏层维度:64
- 层数:2层(可配置)
- Dropout:0.2(可配置)
- 输出类别:15类
- 特点:适合捕捉流量时序特征
4.3 随机森林(Random Forest)
- 模型类型:集成学习(决策树)
- 树的数量:100(可配置)
- 最大深度:无限制(可配置)
- 特点:训练速度快,可解释性强
4.4 逻辑回归(Logistic Regression)
- 模型类型:线性分类器
- 求解器:lbfgs
- 最大迭代:1000(可配置)
- 特点:简单高效,适合作为基线模型