基于核密度估计的Transformer-KDE多输入单输出回归模型
在深度学习和机器学习的回归预测任务中,传统的“点预测(Point Prediction)”模型往往只能给出一个确定性的输出值。然而,在实际的工业、金融或气象等复杂场景中,数据通常伴随着高度的噪声和不确定性。此时,仅仅知道“预测值是多少”是不够的,我们更需要知道“预测值的置信区间是多少”。
为了解决这一问题,本文将详细拆解并介绍一种结合了自注意力机制(Transformer)、**长短期记忆网络(LSTM)以及核密度估计(KDE, Kernel Density Estimation)**的混合回归模型。该模型不仅能够实现高精度的多输入单输出回归,还能通过无参数的密度估计提供科学的 90% 置信区间预测。
1. 核心架构思想
这个混合模型的强大之处在于其“三剑合璧”的架构设计:
- Transformer (Self-Attention): 擅长捕捉输入特征之间的全局依赖关系。通过位置编码(Position Embedding)和多头注意力机制,网络能够自动赋予关键特征更高的权重。
- LSTM: 深度学习处理序列数据的经典网络,放置在 Transformer 之后,用于进一步平滑特征并提取深层的时序/局部动态规律。
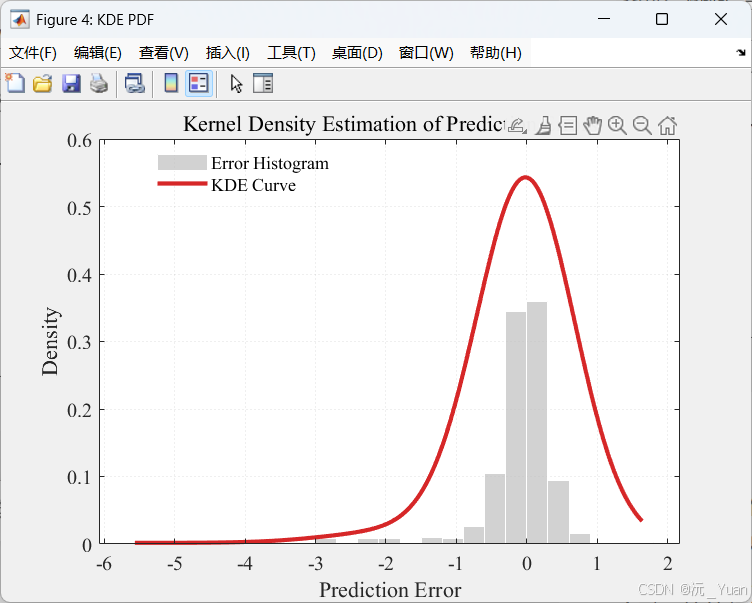
- KDE (核密度估计): 统计学中的非参数检验方法。我们利用预测误差的分布情况,在不预先假设误差服从标准正态分布的前提下,真实地拟合出误差的概率密度函数,从而计算出可靠的置信区间。
2. 数据处理与特征构建
在训练模型之前,代码首先对数据进行了标准化的处理:
- 数据划分: 按照
7:3的比例将数据集划分为训练集和测试集(dividerand)。 - 归一化处理: 为了消除不同维度特征之间的量纲影响,加速网络收敛,模型使用了
mapminmax将所有输入特征和输出标签映射到了 [0, 1] 的区间内。 - 维度重塑: MATLAB 的深度学习工具箱对序列数据的维度有严格要求。代码将二维矩阵通过
reshape转换为适合sequenceInputLayer的胞元数组(Cell Array)格式。
3. 构建 Transformer-LSTM 网络
使用带有 causal(因果)掩码的自注意力层,这在处理具备时间属性的序列时,能够有效防止“未来信息泄露”。
在 Transformer 提取出高维特征(128维)后,利用 indexing1dLayer(“last”) 降维,并送入 16 个隐藏单元的 LSTM 中进行最终的特征过滤与回归计算。
采用 Adam 优化器,搭配分段学习率衰减(LearnRateSchedule = piecewise),使得模型在训练初期能快速跳出局部最优,在训练后期能精细收敛。
4. 误差评估与点预测指标
模型在完成训练后,会进行反归一化,并计算一系列学术界公认的回归评价指标:
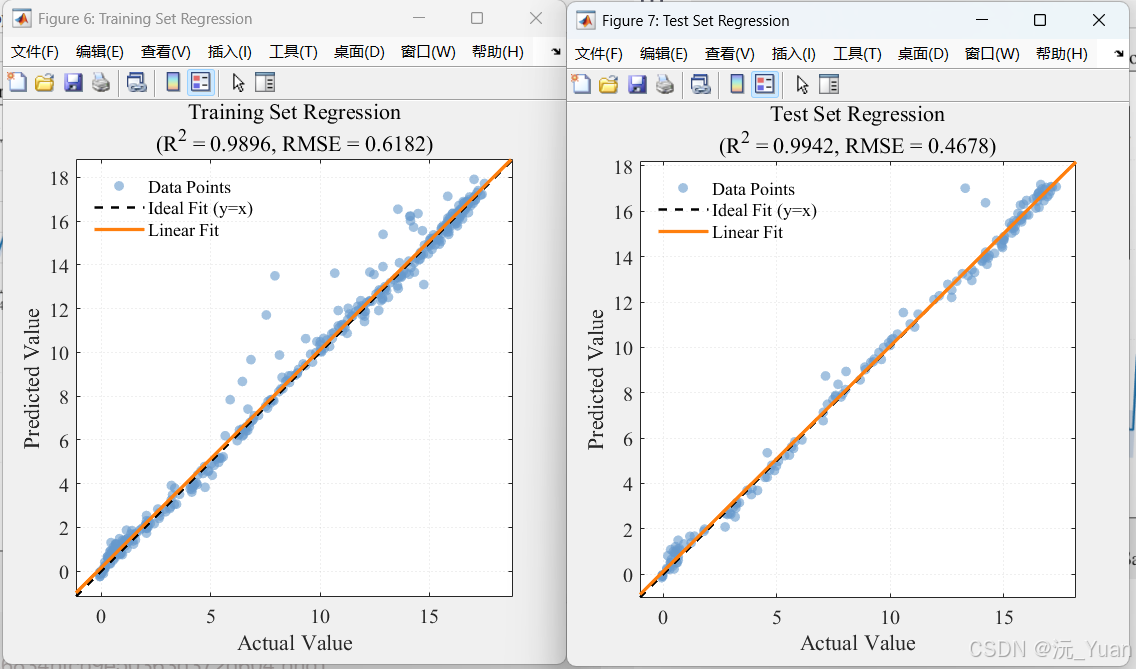
- MAE (平均绝对误差) & RMSE (均方根误差): 衡量预测值与真实值之间的绝对偏差大小。
- MSE (均方误差): 放大较大的预测误差,对异常值更敏感。
- R² (决定系数): 衡量模型对数据变异性的解释程度,越接近 1 模型拟合越好。
- RPD (剩余预测残差) & MAPE: 进一步评估预测的相对精度。
5. 进阶:基于 KDE 的区间预测
点预测完成后,代码进入了最具创新性的环节:KDE 误差概率密度估计。
相比于直接假设误差服从正态分布,KDE 能够根据训练集的实际误差,通过特定的核函数(此处使用的是高斯核 normal)“捏合”出真实的误差分布曲线。
核心步骤:
- 经验带宽选择: 带宽决定了密度曲线的平滑程度。代码采用了类似于 Silverman 经验法则的变体来动态计算训练集误差的带宽:
- h=3.5⋅σ⋅n−1/5
- h=3.5⋅σ⋅n−1/5
- (其中 σ
- σ 为误差标准差,n
- n 为样本量)。
- 计算 CDF 与分位数: 利用
ksdensity得到误差的概率密度函数(PDF),并计算累积分布函数(CDF)。 - 计算 90% 置信区间: 通过线性外插(
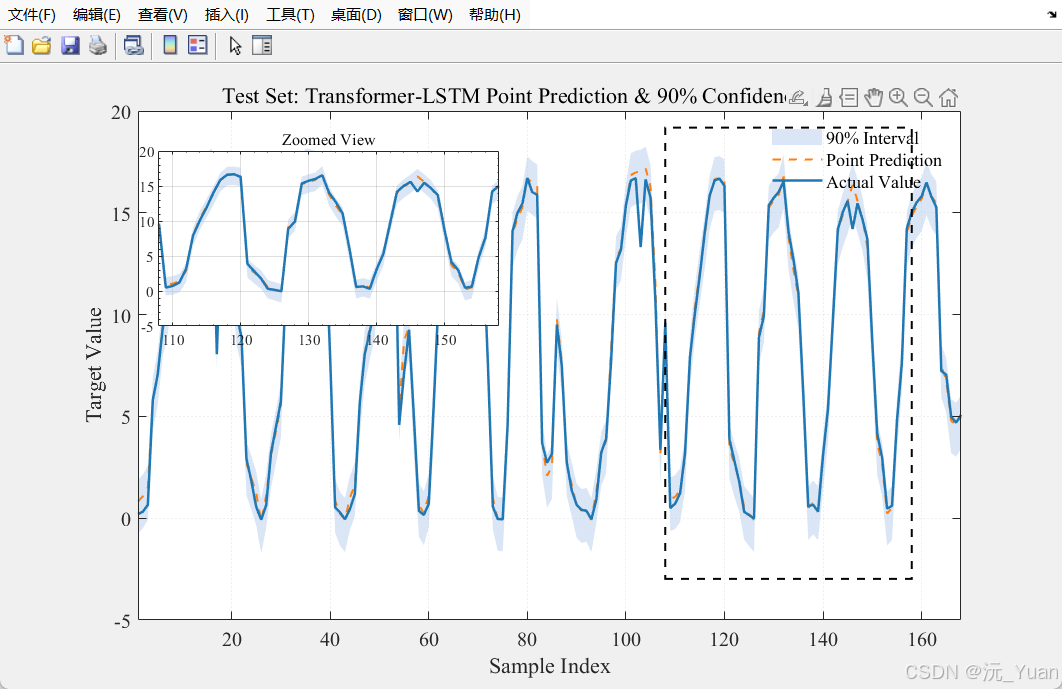
interp1),分别找到 CDF 对应于 0.05 和 0.95 的分位数。将这些误差分位数叠加到测试集的点预测值上,即可得到上下边界(upper_bounds_test和lower_bounds_test)。
区间评价指标:
为了衡量区间预测的质量,代码计算了两个重要指标:
- PICP (区间覆盖率): 测试集中,真实值落在预测区间内的比例。通常我们希望该值大于设定的置信水平(如大于 90%)。
- PINAW (区间平均宽度): 归一化后的平均区间宽度。在保证覆盖率的前提下,PINAW 越小,说明区间越窄,预测的不确定性越低,模型越具备指导价值。
6. 数据可视化
一份优秀的科研代码,其图表必须具备说服力。该代码内置了 7 张高度定制化的高质量图表,全局采用 Times New Roman 字体,配色经过精心调校(深蓝、亮橙、砖红),直接达到了学术论文的出版标准:
- 点预测对比图: 清晰展示训练集和测试集的拟合效果。
- 误差 Stem 图: 直观呈现每个样本的测试误差波动。
- KDE 概率密度图: 将误差直方图与 KDE 拟合曲线叠加,完美展示误差分布的非参数特性。
- 动态画中画(Zoom-in)区间预测图: 这是可视化的一大亮点。用半透明淡蓝色填充 90% 置信区间,并且在主图中动态截取末尾 30% 的数据,生成局部放大的子坐标系(画中画),极大地提升了图表的专业度。
- 线性拟合散点图(Regression Plot): 利用
polyfit绘制了预测值与真实值的 1:1 对角线与实际拟合线,通过半透明散点完美呈现了预测的相关性。
7. 运行结果
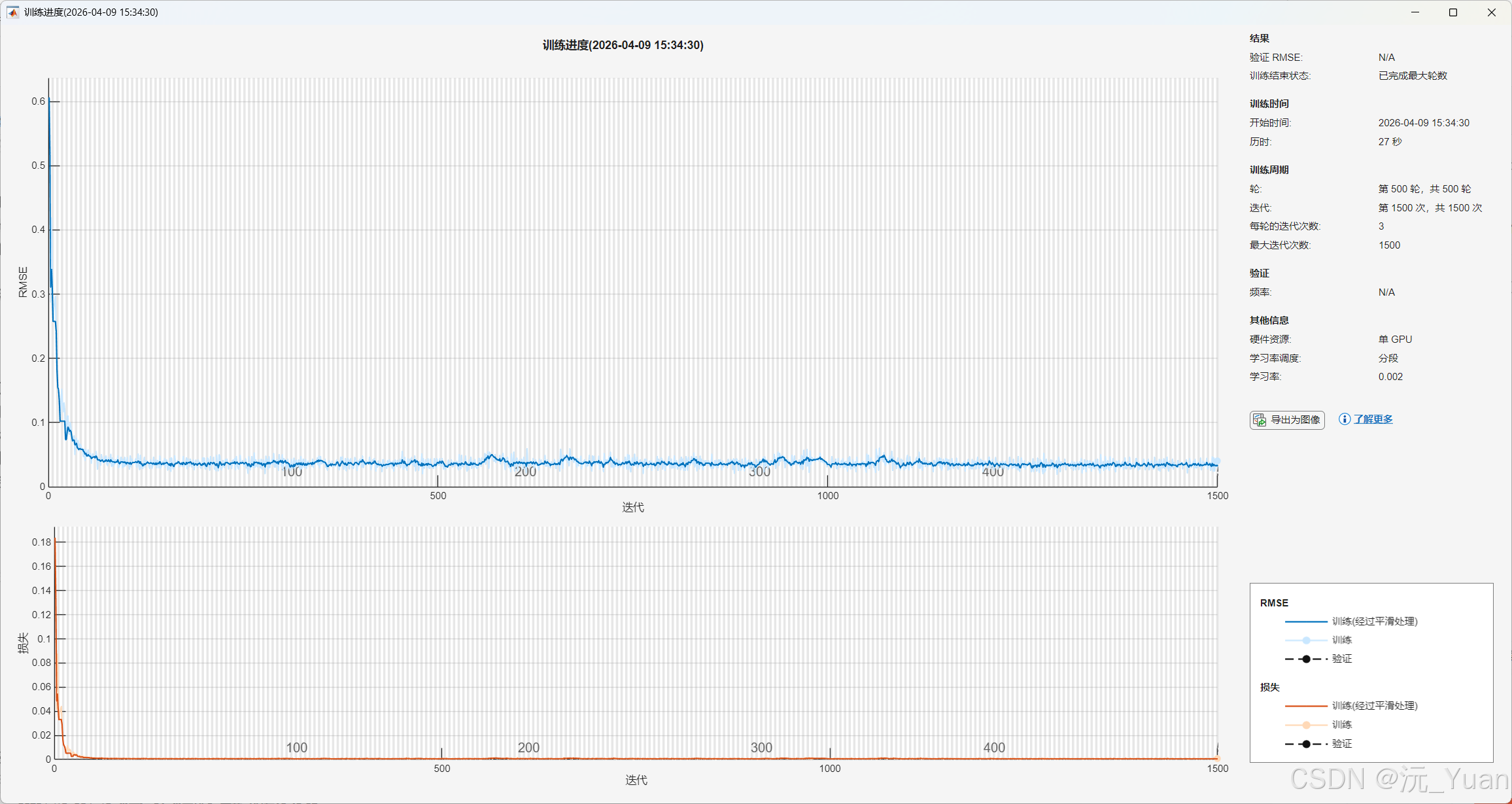
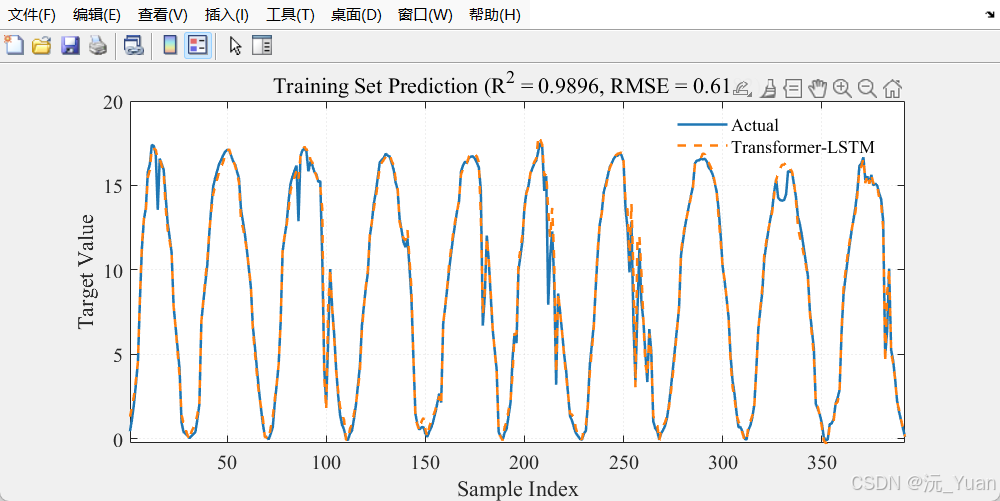
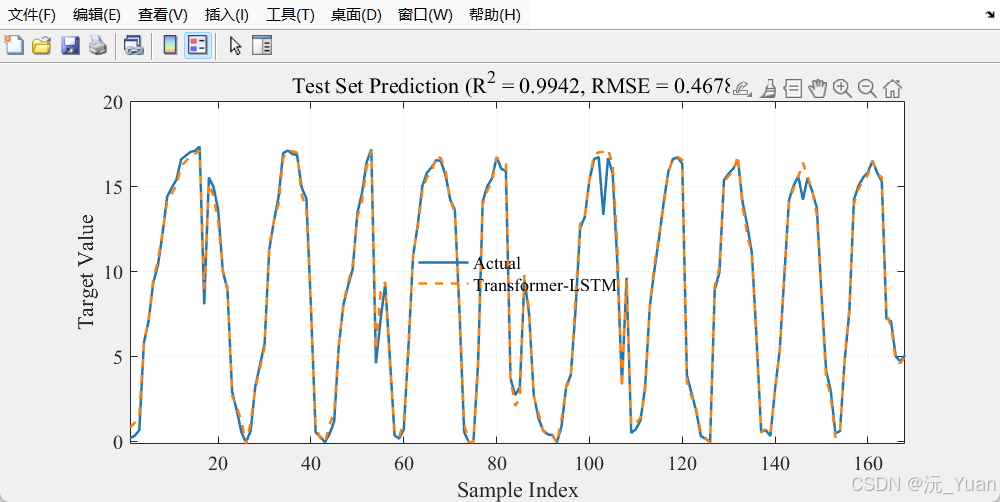
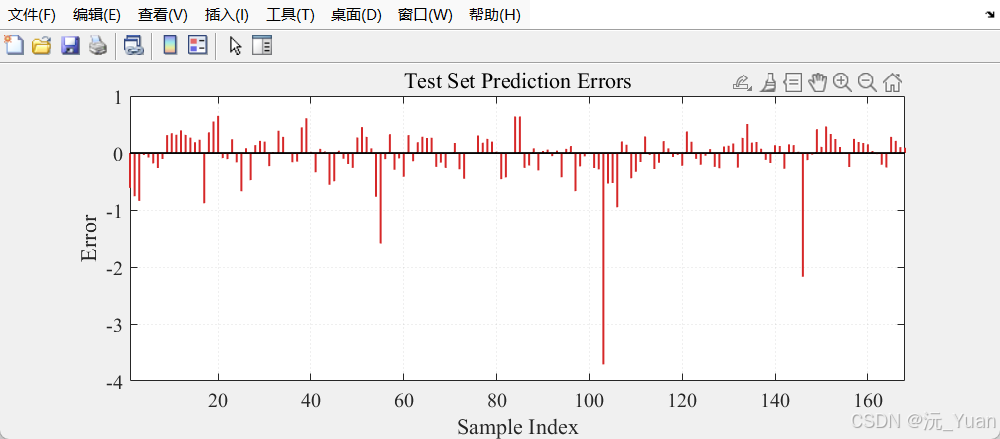
总结
《基于核密度估计的Transformer-KDE多输入单输出回归模型》是一套从数据预处理、特征深度提取、高精度点预测,一直延伸到不确定性量化(区间预测)的完整解决方案。它不仅在算法逻辑上环环相扣,其内置的可视化模块也极其完备,非常适合时间序列预测、工业参数回归、甚至金融风控等领域的工程应用与学术研究。