基于核密度估计的BP-KDE多输入单输出回归模型
摘要:本文介绍一种将传统BP神经网络与核密度估计(KDE)相结合的回归预测框架——BP-KDE模型。该模型不仅能完成多输入单输出的点预测任务,还能通过KDE对误差分布进行精细刻画,进而构建概率预测区间,输出更具统计可信度的预测结果。文章将结合完整的MATLAB实现代码,逐步讲解模型原理、工程细节与评估指标。
目录
背景与动机
在工程预测、金融建模、气象分析等实际场景中,仅输出一个"点预测值"往往是不够的。决策者更需要知道:这个预测值可靠吗?误差有多大?真实值落在哪个区间的概率更高?
传统BP神经网络(Back Propagation Neural Network)是解决非线性回归问题的经典工具,但它天然只给出点预测,缺乏对预测不确定性的量化能力。
核密度估计(Kernel Density Estimation, KDE) 是一种非参数化的概率密度估计方法,无需假设误差服从特定分布(如高斯分布),能够从数据本身出发,自适应地刻画误差的真实分布形态。
将两者结合,形成 BP-KDE 框架,可以:
- ✅ 利用BP网络的强拟合能力完成点预测
- ✅ 利用KDE精确描绘误差的概率分布
- ✅ 基于误差分布构建预测区间,量化预测不确定性
- ✅ 输出PICP、PINAW等区间评估指标,全面衡量模型质量
模型架构总览
输入特征 X (n_features × n_samples)
│
▼
┌─────────────┐
│ 数据归一化 │ mapminmax → [-1, 1]
└──────┬──────┘
│
▼
┌─────────────────────────────────┐
│ BP 神经网络 │
│ 输入层 → 隐藏层(logsig) → │
│ 输出层(purelin) │
│ 训练算法: Levenberg-Marquardt │
└──────────────┬──────────────────┘
│ 点预测值 Ŷ
▼
┌─────────────────────────────────┐
│ 误差计算 e = Ŷ - Y_true │
└──────────────┬──────────────────┘
│
┌───────┴────────┐
▼ ▼
┌─────────────┐ ┌─────────────────┐
│ KDE 分析 │ │ 区间估计 │
│ 可视化误差 │ │ Upper/Lower 界 │
│ 概率密度 │ │ PICP & PINAW │
└─────────────┘ └─────────────────┘
数据预处理
数据划分
代码使用 dividerand 函数将数据集按 7:3 的比例随机划分为训练集与测试集:
[trainInd, valInd, testInd] = dividerand(size(X,2), 0.7, 0, 0.3);
子集比例用途训练集70%网络权值学习测试集30%泛化性能评估
归一化处理
神经网络对输入数据的尺度非常敏感,因此对输入特征 X 和标签 Y 均采用 最小-最大归一化,将数值映射至 [-1, 1]:
[Pn_train, inputps] = mapminmax(P_train, -1, 1); [Tn_train, outputps] = mapminmax(T_train, -1, 1);
注意:测试集的归一化参数必须复用训练集的inputps和outputps,严禁对测试集重新计算归一化参数,以防止数据泄露。
Pn_test = mapminmax('apply', P_test, inputps);
Tn_test = mapminmax('apply', T_test, outputps);
BP神经网络构建与训练
网络拓扑结构
本模型采用经典的三层前馈网络:
层次节点数激活函数说明输入层size(X,1)—与特征维度一致隐藏层8logsigS型函数,捕捉非线性特征输出层size(Y,1)purelin线性输出,适合回归任务
inputnum = size(X, 1); % 输入特征数
hiddennum = 8; % 隐藏层节点数(可调)
outputnum = size(Y, 1); % 输出维度(单输出为1)
net = newff(minmax(Pn_train), [hiddennum outputnum], ...
{'logsig', 'purelin'}, 'trainlm');
训练参数配置
net.trainparam.epochs = 500; % 最大迭代次数 net.trainparam.goal = 1e-4; % 训练目标误差 net.trainParam.lr = 1e-4; % 学习率
训练算法:Levenberg-Marquardt(LM)
本模型使用 trainlm 算法,即 Levenberg-Marquardt 优化算法。LM算法结合了梯度下降法和高斯-牛顿法的优点:
- 在误差较大时,行为接近梯度下降,稳定收敛
- 在误差较小时,行为接近牛顿法,收敛速度极快
- 特别适合中小规模数据集上的神经网络训练
LM更新规则:Δw = -(J^T J + λI)^{-1} J^T e
其中 J 为雅可比矩阵,λ 为阻尼因子,e 为误差向量。
核密度估计(KDE)误差分析
对比项直方图KDE连续性分段阶梯,不连续连续光滑曲线对bin宽敏感非常敏感自动带宽选择分布形态展示粗粒度精细描绘尾部
代码实现
% 训练集误差 KDE
[f_train, xi_train] = ksdensity(TrainError);
plot(xi_train, f_train, 'Color', [0.8 0.2 0.2], 'LineWidth', 2);
% 测试集误差 KDE
[f_test, xi_test] = ksdensity(TestError);
plot(xi_test, f_test, 'Color', [0.8 0.2 0.2], 'LineWidth', 2);
MATLAB的 ksdensity 函数默认使用高斯核,并采用 Silverman 经验法则自动选择最优带宽:
从KDE图中读取信息
通过观察KDE曲线,可以判断:
- 峰值位置:误差的集中趋势(是否系统性偏大或偏小)
- 曲线宽度:误差的离散程度(越窄说明预测越稳定)
- 对称性:误差是否存在系统性偏差(偏斜分布暗示模型有偏)
- 尾部厚重程度:是否存在大误差的异常样本
区间预测:从点估计到概率区间
构建预测区间
在本框架中,假设预测误差近似服从正态分布,利用误差标准差构建 95% 预测区间:
Z_value = 1.96; std_error = std(TestError); Upper_Bound = TestResults + Z_value * std_error; Lower_Bound = TestResults - Z_value * std_error;
扩展提示:若KDE分析表明误差分布明显非正态(如重尾、偏斜),可改用KDE的分位数来确定上下界,从而构建更准确的非参数预测区间。
综合评估指标体系
模型从点预测精度和区间预测质量两个维度进行评估。
点预测指标
MAE1 = sum(abs(TestError)) / len;
MSE1 = TestError * TestError' / len;
RMSE1 = sqrt(MSE1);
R = corrcoef(T_test, TestResults);
r2 = R(1,2)^2;
MAPE = calculateMAPE(T_test, TestResults);
区间预测指标
PICP(预测区间覆盖率):
- 衡量区间的"紧致程度"
- 在PICP满足要求的前提下,PINAW越小越好
is_covered = (T_test >= Lower_Bound) & (T_test <= Upper_Bound);
PICP = sum(is_covered) / len;
interval_widths = Upper_Bound - Lower_Bound;
range_T = max(T_test) - min(T_test);
PINAW = mean(interval_widths) / range_T;
优质模型的标准:PICP ≈ 95%(达标),PINAW尽量小(精确)。二者之间存在权衡关系,需综合评价。
完整代码解析
完整代码按照以下流程组织,模块清晰、逻辑连贯:
Step 1: 导入数据(load data.mat) ↓ Step 2: 划分训练/测试集(dividerand,7:3) ↓ Step 3: 数据归一化(mapminmax,[-1,1]) ↓ Step 4: 构建BP网络(newff,隐藏层8节点,LM算法) ↓ Step 5: 训练网络(train) ↓ Step 6: 训练集/测试集预测(sim + mapminmax reverse) ↓ Step 7: 误差计算 & KDE分析(ksdensity) ↓ Step 8: 计算点预测指标(MAE/RMSE/R²/MAPE) ↓ Step 9: 构建预测区间(Z=1.96 × std_error) ↓ Step 10: 计算区间指标(PICP/PINAW) ↓ Step 11: 可视化(3组图窗)& 终端输出
关键自定义函数:MAPE计算
function mape = calculateMAPE(actual, forecast)
absolute_error = abs(actual - forecast);
valid_idx = actual ~= 0; % 排除真实值为0的样本,避免除零
percentage_error = absolute_error(valid_idx) ./ actual(valid_idx);
mape = mean(percentage_error) * 100;
end
此函数特别处理了真实值为零的边界情况,避免MAPE计算时出现Inf或NaN。
结果可视化说明
代码共生成 3组图窗,覆盖从基础到高级的完整分析视角:
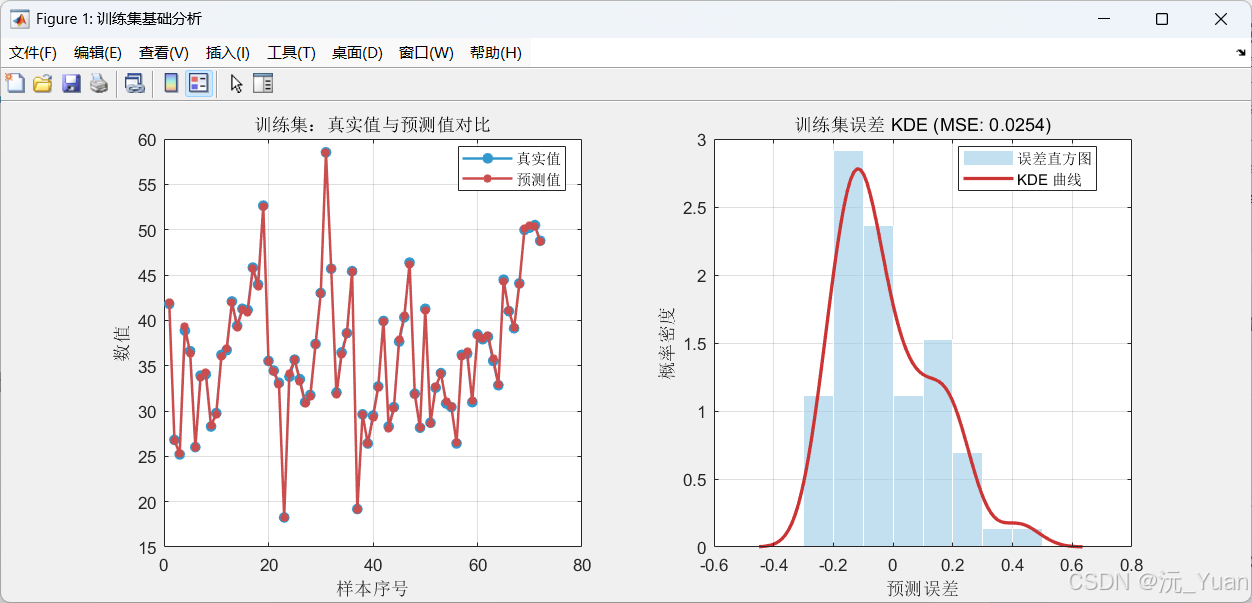
图窗1:训练集基础分析
子图内容关注点左图真实值 vs 预测值折线对比曲线贴合程度,是否存在系统性偏差右图训练集误差直方图 + KDE曲线误差分布形态,是否对称,峰值位置
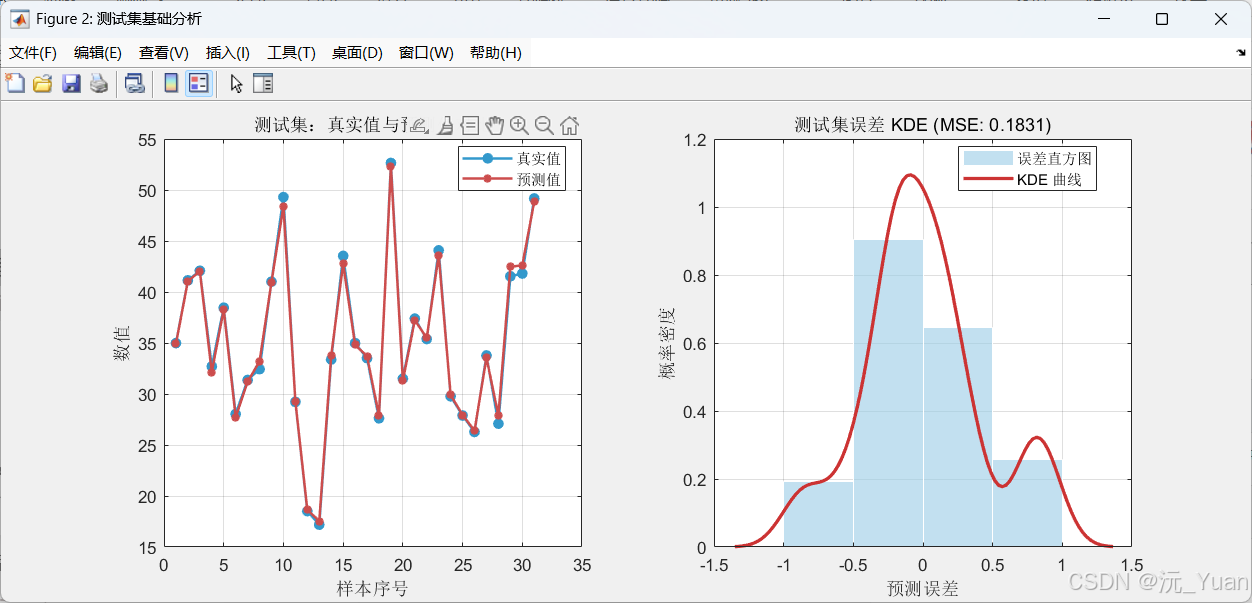
图窗2:测试集基础分析
与训练集类似,但更重要——测试集结果反映模型的真实泛化能力。
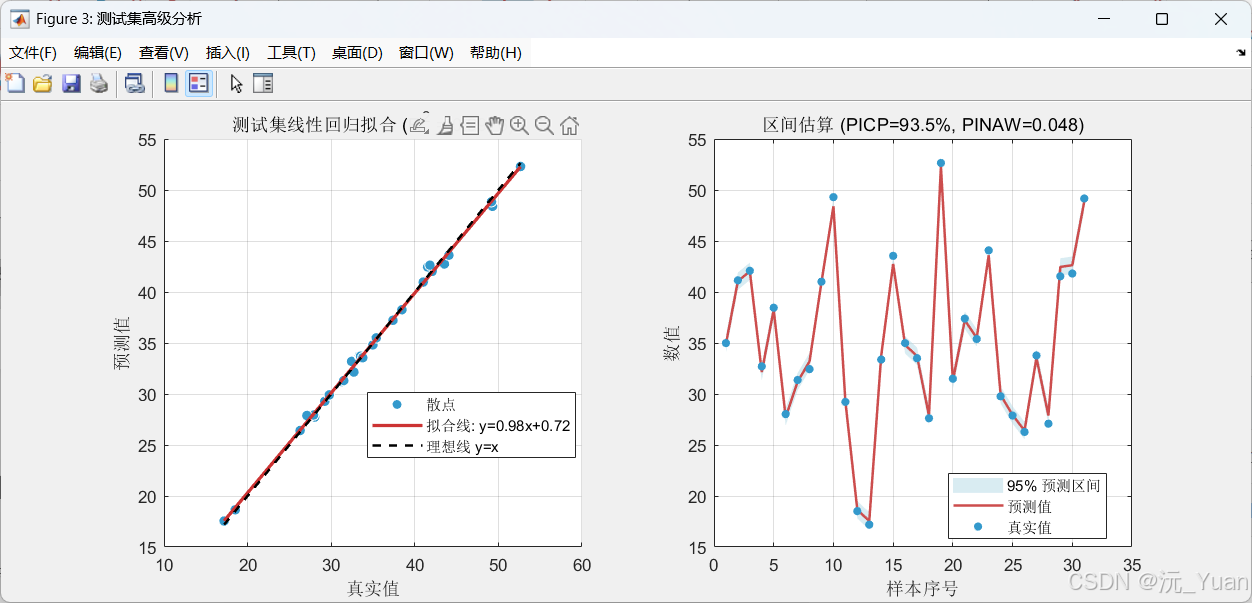
图窗3:测试集高级分析
子图内容关注点左图散点图 + 线性拟合线 + 理想线(y=x)R²值,拟合线与理想线的偏离程度右图预测区间阴影图(真实值 vs 预测值 vs 95%区间)PICP是否达标,区间宽窄是否合理
总结与展望
本文小结
BP-KDE框架通过以下三步实现了从"点预测"到"概率预测"的跨越:
- BP神经网络完成非线性映射,输出点预测值
- KDE分析对预测残差进行非参数密度估计,揭示误差的真实分布
- 区间构建基于误差统计特性生成预测上下界,量化预测不确定性
潜在改进方向
方向说明非参数区间直接用KDE的分位数构建区间,替代正态假设,适用于非对称误差分布Dropout不确定性在网络中引入Dropout,通过多次前向推断估计预测方差集成方法训练多个BP网络,用集成预测的方差作为不确定性估计自适应带宽KDE使用局部带宽KDE,对误差分布的局部结构有更强的刻画能力深度网络将BP替换为LSTM/Transformer等序列模型,适用于时序预测场景
📌 数据准备提示:运行代码前,请确保data.mat文件中包含变量X(特征矩阵,维度为n_features × n_samples)和Y(标签矩阵,维度为1 × n_samples)。如需快速测试,可取消注释代码中的随机数据生成行:
X = rand(5, 100); Y = rand(1, 100);