1.软件版本
matlab2022a
2.运行方法
使用matlab2022a或者高版本仿真,运行文件夹中的tops.m或者main.m。运行时注意matlab左侧的当前文件夹窗口必须是当前工程所在路径。具体操作观看提供的程序操作视频跟着操作。
3.部分仿真截图
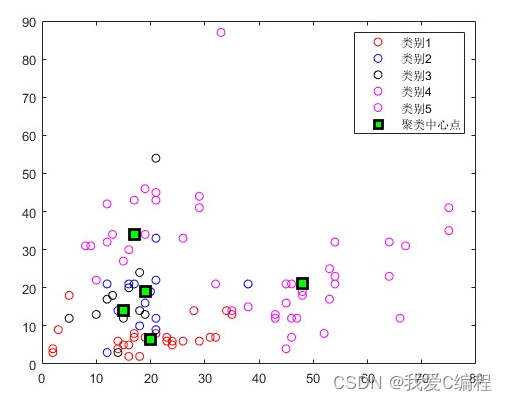
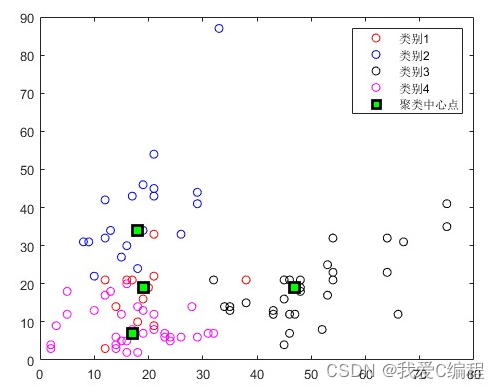
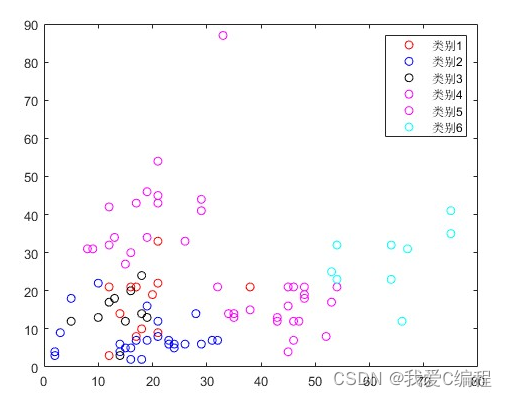
4.内容简介
首先计算整个数据集合的平均值点,作为第一个初始聚类中心C1;
然后分别计算所有对象到C1的欧式距离d,并且计算每个对象在半径R的范围内包含的对象个数W。
此时计算P=u*d+(1-u)*W,所得到的最大的P值所对应的的对象作为第二个初始聚类中心C2。
同样的方法,分别计算所有对象到C2的欧式距离d,并且计算每个对象在半径R的范围内包含的对象个数W,所得到的最大的P值所对应的的对象作为第二个初始聚类中心C3。
从这三个初始聚类中心开始聚类划分。对于一个待分类的对象,计算它到现有聚类中心的距离,若(这个距离)<(现有各个聚类中心距离的最小值),则将这个待分类对象分到与它相距最近的那一类;如果(这个距离)>(现有各个聚类中心距离的最小值),则这个待分类对象就自成一类,成为一个新的聚类中心,然后对所有对象重新归类。
如果找到新的聚类中心,在重新计算聚类的中心后。对目前形成的K+1 个聚类计算 DBInew 的值,和未重新分配对象到这 k+1 个类之前计算的 DBIold进行比较,如果 DBInew